はじめに
単語をベクトル化する分散表現と、Tensorboardを使用して3次元空間上にプロットして可視化する方法についてまとめました。
※実装では、言語はPython、環境はGoogle Colaboratoryを使用しています。ご自身の環境に合わせて読み替えて下さい。
目次
単語の分散表現とは
自然言語処理といった分野があります。
自然言語とは、我々が日常的に話したり書いたりしている言葉のことです。
そういった自然言語をコンピュータで扱おうとした場合、そのままの形で扱うことは難しく、一旦数字に置き換える必要があります。
数値に置き換える方法は色々とあるのですが、今回は分散表現というものを使用します。
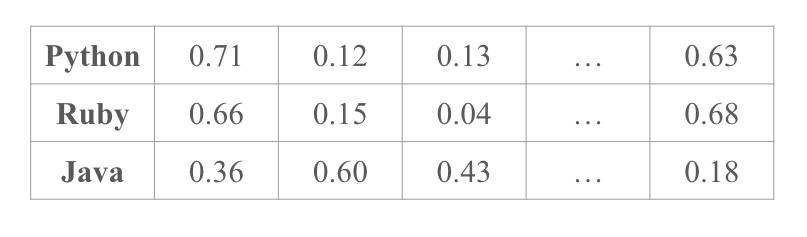
分散表現とは、単語を実数値のベクトルで表したものです。
ベクトルとは数値がいくつか並んだものだと考えて下さい。
例えば、Python, Ruby, Javaといった単語を分散表現で表すと以下のようになります(数値は適当な値です)。
ベクトルの性質について簡単に説明します。
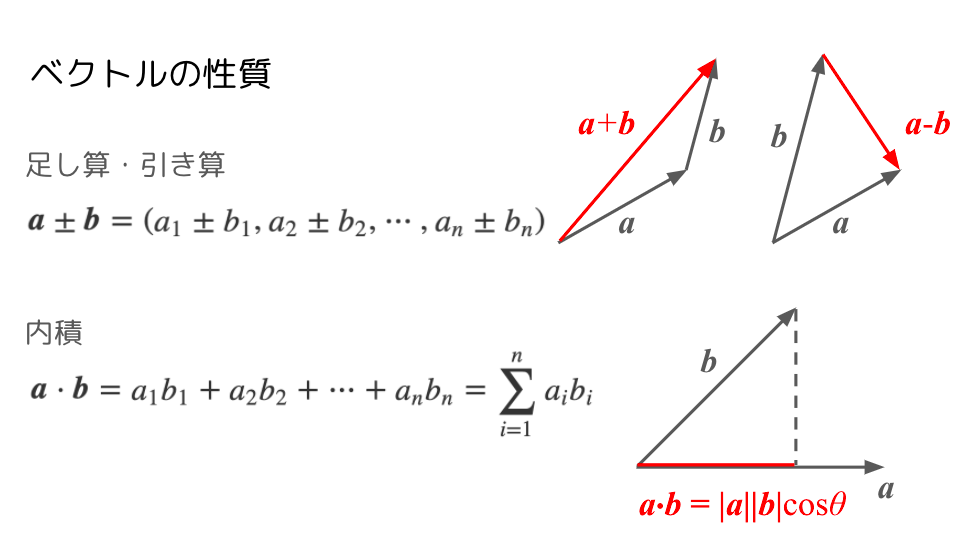
「ベクトルとは数値がいくつか並んだもの」と上述しました。
この数値がいくつ並んでいるか、が次元と呼ばれます。
数値が2つの場合は2次元、3つの場合は3次元、…となります。
ベクトルでは、足し算や引き算、内積その他の演算が定義されています。
※下図では、簡単のため2次元ベクトルの図を使用しています。
分散表現により、自然言語である単語をベクトル化することができれば、単語同士についても同様の計算ができるようになります。それは、
- 意味的な足し算や引き算
- どれだけ意味的に近いか
を計算することに相当します。
実装
モデルの準備
今回は、ゼロから単語の分散表現のモデルを作成することはせず、公開されている学習済みの単語分散表現を使用します。
以下のモデルをダウンロードして下さい(注釈)。
!wget https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.ja.300.vec.gz
ダウンロードができたら、モデルとしてインポートします。
ここでは、gensimという自然言語処理を扱うためのPythonライブラリを使用してモデルをロードします。
※ロードにはしばらく時間がかかります。
import gensim
model = gensim.models.KeyedVectors.load_word2vec_format('cc.ja.300.vec.gz', binary=False)
ロードが完了したら、早速モデルを使用してみましょう。
試しに、「Python」という単語の分散表現を見てみます。
model['Python']
# array([ 7.000e-03, 1.310e-02, 5.500e-03, -3.660e-02, -8.600e-03,
# -2.430e-02, -7.050e-02, 5.920e-02, 8.370e-02, 3.600e-02,
# ︙
# 2.110e-02, 4.180e-02, -5.470e-02, 2.350e-02, 2.200e-02],
# dtype=float32)
実数値が並んだベクトルとなっており、確かに分散表現で表されています。
今回のモデルでは、ベクトルの次元は300次元となっています。
model['Python'].shape
# (300,)
次に、Pythonに近い単語上位10コを表示してみます。
model.most_similar('Python', topn=10)
# [('python', 0.7935450077056885),
# ('Clojure', 0.7304115295410156),
# ('OCaml', 0.7204216718673706),
# ('Cython', 0.7158461809158325),
# ('Ruby', 0.706175684928894),
# ('Perl', 0.7045886516571045),
# ('Haskell', 0.6954647302627563),
# ('Java', 0.6816721558570862),
# ('Erlang', 0.6776419878005981),
# ('IPython', 0.6646149754524231)]
では次に、単語同士の足し算・引き算を計算してみます。
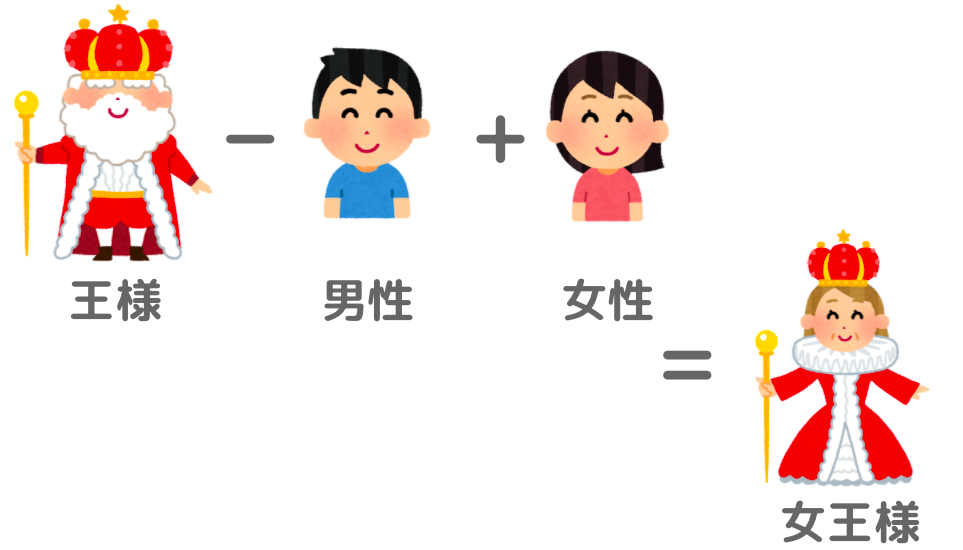
ここでは、例としてよく挙げられる
『王様−男性+女性=女王様』
について、実際にそういった結果になるかを確認してみます。
model.most_similar(positive=['王様', '女性'],
negative=['男性'],
topn=10)
# [('女王', 0.5497723817825317),
# ('王妃', 0.5333674550056458),
# ('お姫様', 0.5282727479934692),
# ('王さま', 0.5261490345001221),
# ('ラジオキッズ', 0.5149459838867188),
# ('お姫さま', 0.5045803785324097),
# ('王女', 0.5034000873565674),
# ('タプチム', 0.499458909034729),
# ('ブランチ', 0.4980105757713318),
# ('乃女', 0.49398326873779297)]
確かに、「女王」「王妃」「お姫様」といった、期待する答えが上位に並んでいますね。
せっかくなので、もうひとつ。
『日本−東京+ロンドン』の結果は何になるでしょうか?
国名である日本から首都である東京を引き算し、首都であるロンドンを足し算したものは…?
model.most_similar(positive=['日本', 'ロンドン'],
negative=['東京'],
topn=10)
# [('イギリス', 0.6945440769195557),
# ('英国', 0.6216877698898315),
# ('ヨーロッパ', 0.6075816750526428),
# ('アメリカ', 0.5903184413909912),
# ('イングランド', 0.5594041347503662),
# ('各国', 0.549339234828949),
# ('欧米', 0.537621259689331),
# ('米国', 0.5245243906974792),
# ('オーストラリア', 0.5227084159851074),
# ('欧州', 0.5212200284004211)]
正解は「イギリス」でした!
このように、分散表現では単語同士の意味的な足し算や引き算ができるようになります。
色々と遊んでみると面白いかと思います。
2つの単語の類似度を計算することもできます。
PythonとRuby、PythonとAppleの類似度をそれぞれ計算するとどうなるでしょうか?
model.similarity('Python', 'Ruby')
# 0.70617557
model.similarity('Python', 'Apple')
# 0.33666733
PythonとRubyはともにプログラミング言語なので類似度は高く、PythonとフルーツのAppleは関連性がなさそうなので類似度は低い、といった想定に近い結果が得られたと思います。
TensorBoardによる3次元空間での可視化
次に、分散表現を3次元空間へプロットすることを考えます。
※分散表現は数百(今の場合300)次元のベクトルなので、そのまま可視化することはできません。詳細は割愛しますが、次元削減という方法を用いて3次元に落とし込みます(注釈)。
TensorBoardを使用することで、分散表現を3次元空間へプロットして可視化することができます。TensorBoardとは、TensorFlowの可視化ツールで機械学習ではよく用いられています(公式HP)。
それでは、まず必要なライブラリをインストールします。
!pip install gensim torch tensorboardX tensorflow
次に、可視化したい分散表現を用意します。ここでは、すでに用意している学習済み分散表現のモデルmodelを使用しています。また、プロットする単語数は30,000としました。
import gensim
import torch
from tensorboardX import SummaryWriter
writer = SummaryWriter()
weights = model.vectors
labels = model.index2word
weights = weights[:30000]
labels = labels[:30000]
writer.add_embedding(torch.FloatTensor(weights), metadata=labels)
それでは、TensorBoardを使って分散表現をプロットしてみましょう。
※プロットする単語数が多いほど(今回は30000語)、表示に時間がかかります。時間がかかりすぎる、あるいは表示できない場合には、単語数を減らしてみて下さい。
%load_ext tensorboard
%tensorboard --logdir runs
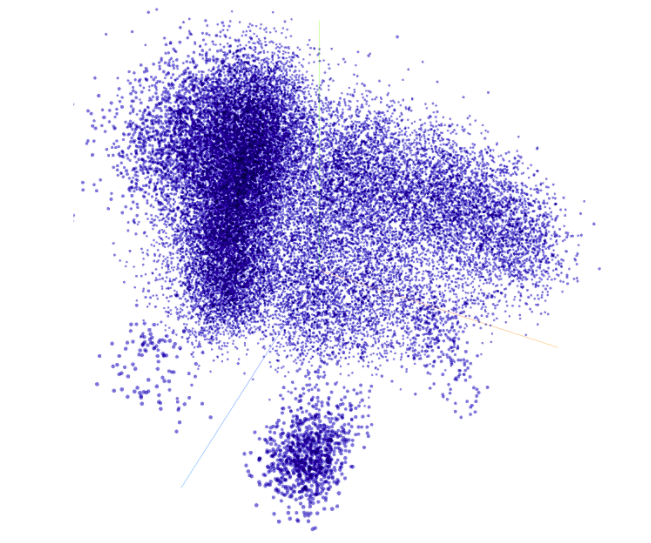
各単語が3次元空間上にプロットされています(注釈)。
ではここで、試しに「プログラミング」という特定の単語に着目してみます。すると、以下の場所に位置していました。

「プログラミング」という単語の周辺にはどういった単語が分布しているでしょうか。
近づいて見てみると以下のようになっていました。

「Javascript」「ソフトウェア」「コンピュータ」「アルゴリズム」といった、意味的に近いと思われる単語が分布している様子が見てとれます(注釈)。
まとめ
今回は、単語をベクトル化する分散表現と、Tensorboardを使用して3次元空間上にプロットして可視化する方法についてまとめました。
分散表現では、数値のベクトルと同じように計算することができます。
意味的な足し算や引き算、3次元空間へプロットすることで単語同士の意味的な関連性を見ることができます。
注釈
- 本記事は、『Python Charity Talks in Japan 2021.02』で私がLTした内容をまとめたものです。
- Facebookが公開している単語の分散表現モデル。日本語WikipediaをMeCabで分かち書きした後、fastTextというアルゴリズムによって計算したもの(詳細は公式HPをご参照下さい)。
- 次元削減にはいくつかの方法がありますが、今回は「PCA(主成分分析)」を使用しました。次元削減の方法については、こちらの記事がわかりやすかったです。
- 今回、次元削減でPCAを使用していますが、TensorBoardではそれ以外を選択することも可能です。
- 意味的に近くない単語も含まれてしまっていますが、現在プロットしている30,000単語より単語数を増やすことで、より関連性の高い単語が得られるようになるハズです。
参考文献