Watson Visual Recognition(VR)で新機能 Custom Object Detectionのベータ版が提供されたので試してみました。こちらのリンクから申請をすることで順次使用開始のメールが送られてきます。Documentationにも使用方法が記載されています。
Custom Object Detectionとは
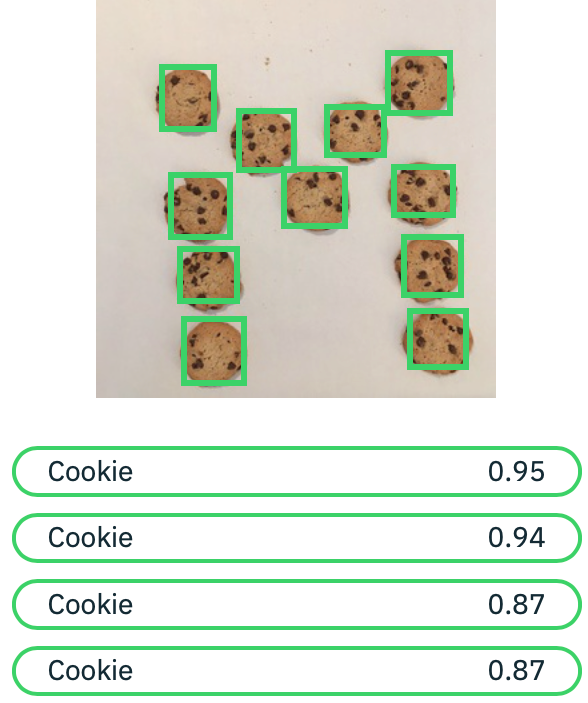
これまでVRで可能な学習機能は画像の「分類」のためのもので、以下のように画像にクッキーが写っていることは分かりますが、画像上の位置を特定することはできませんでした。

Custom Object Detectionでは以下のようにクッキーであるという分類と共に、その位置も「検出」できるようになります。物体の位置を特定する、あるいは数をカウントすること等ができるので、これまでの「分類」のユースケースに比べると使い道がグッと増えることになります。
実際に試してみた
物体検出に関してはこれまで以下のような記事を公開していますが、今回も同じデータを使って画像から新旧Watsonのロゴを検出してみたいと思います。
物体検出のための学習データを用意するためにはアノテーションツールで画像にアノテーションしたものが必要です。VRの場合はWatson Studioでアノテーションをすることができます。
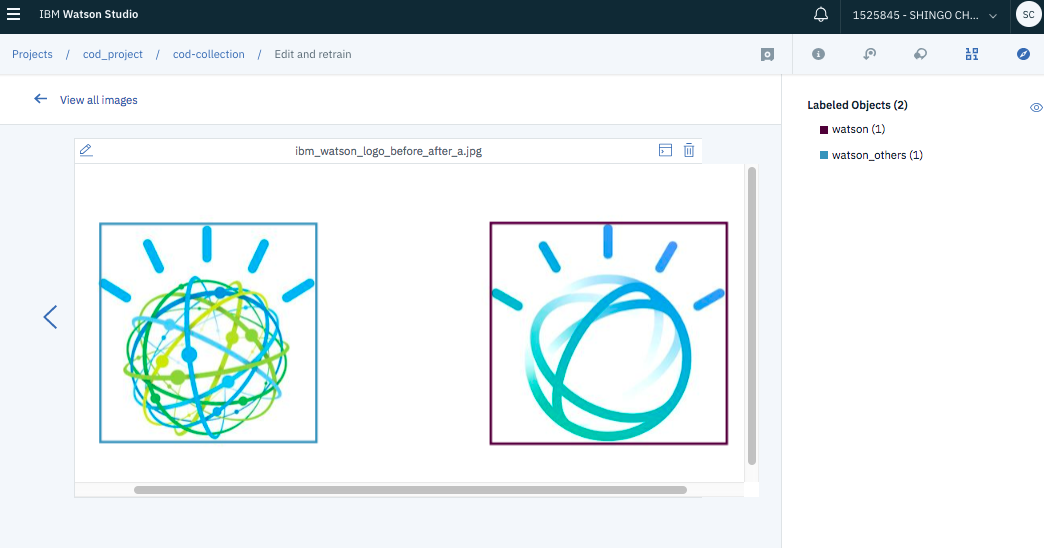
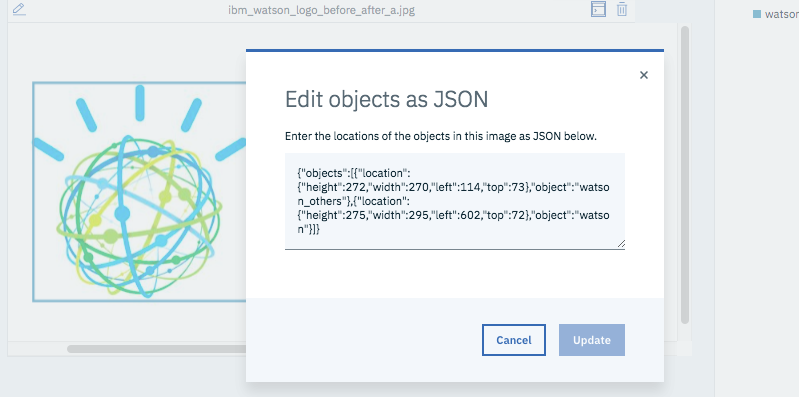
アノテーションした情報はJSON形式で、アノテーション箇所の分類(ラベル)と位置(left,top,width,height)を保持しています。
アノテーションが完了したら、Watson Studioで「Train Model」ボタンをクリックすると学習が開始します。

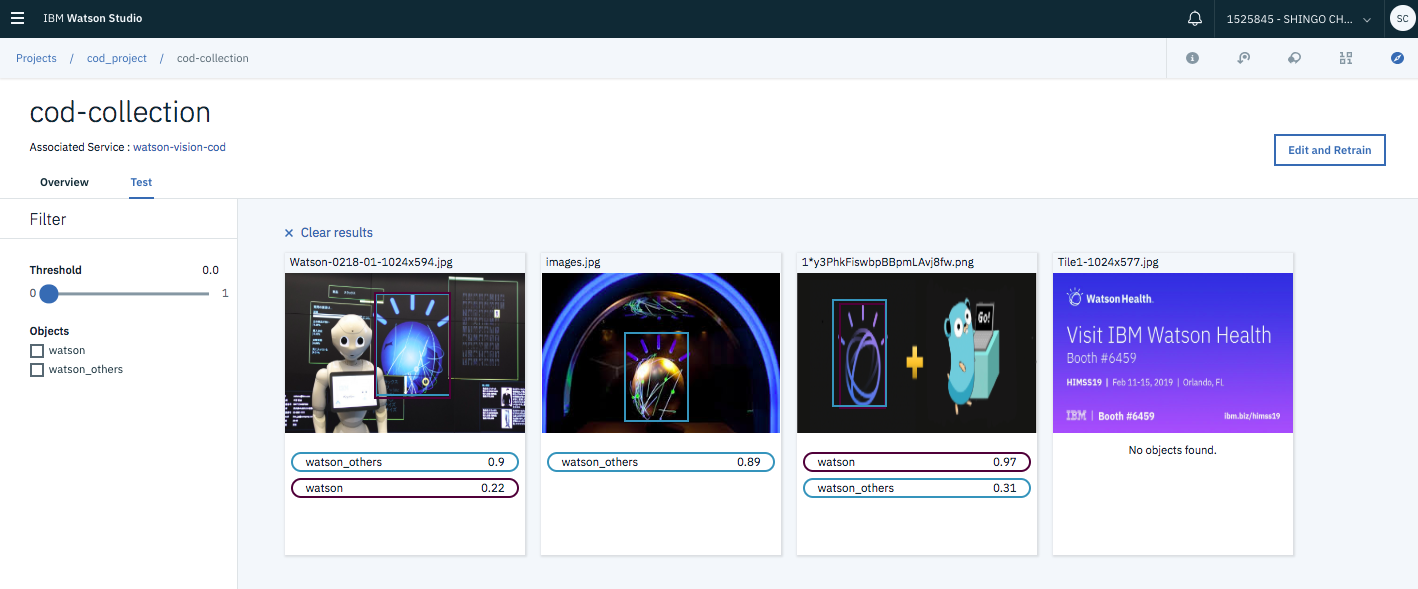
学習完了後、テストもWatson Studio上で可能です。テスト画面でテスト用の画像をドラッグ&ドロップすると、検出結果がconfidenceと共に表示されます。全体的にはそれなりに検出ができているように見えます。一番右の画像は検出対象が小さいためか検出に失敗しており、製品としての限界がどのくらいかも今後見極めて使っていく必要がありそうです。