はじめに
エクセル資料からのデータクレンジングが上手くできたので、
備忘録的に書きます。
※長くなったため、前後編に分割します。
使用データ
本記事で処理するデータ一覧:
観光庁: 旅行・観光消費動向調査 から
- 「2018年10~12月期」 集計表
- 「2018年7~9月期」 集計表
- 「2018年4~6月期」 集計表
- 「2018年1~3月期」 集計表
- 「2017年10~12月期」 集計表
- 「2017年7~9月期」 集計表
- 「2017年4~6月期」 集計表
- 「2017年1~3月期」 集計表
各データの第4表(TO4)、主目的地(A07~N22)を使用
※それぞれのファイルについて、yyyyMM形式でリネームしています。
データについて
日本国内居住者の旅行・観光のデータです。
今回は日本人が「いつ・どこに行ったのか」というデータに整形します。
(ゴールデンウィークについて人数予測的なことをしたかったため、このデータを使用しました。)
※エクセルでの表記
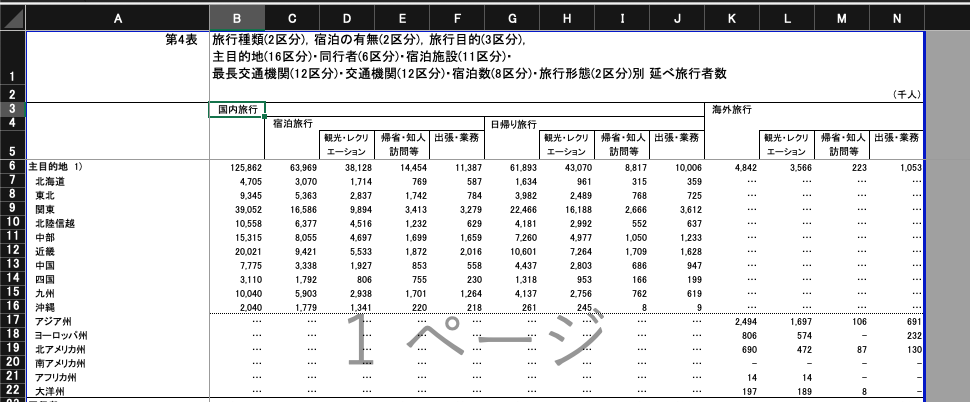
データの確認
import pandas as pd
import warnings
warnings.filterwarnings('ignore')
df = pd.read_excel('201710.xls',sheet_name=3)
df
※出力は諸々省略しています。
| 第4表 | 旅行... | Unnamed: 2 | Unnamed: 3 | Unnamed: 4 | Unnamed: 5 | Unnamed: 6 | Unnamed: 7 | Unnamed: 8 | Unnamed: 9 | Unnamed: 10 | Unnamed: 11 | Unnamed: 12 | Unnamed: 13 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | (千人) |
| 1 | NaN | 国内旅行 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | 海外旅行 | NaN | NaN | NaN |
| 2 | NaN | NaN | 宿泊旅行 | NaN | NaN | NaN | 日帰り旅行 | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 3 | NaN | NaN | NaN | 観光・レクリエーション | 帰省・知人\n 訪問等 | 出張・業務\n | NaN | 観光・レクリエーション | 帰省・知人\n 訪問等 | 出張・業務\n | NaN | 観光・レクリエーション | 帰省・知人\n 訪問等 | 出張・業務\n |
| 4 | 主目的地 1) | 149598 | 75147.6 | 40858.2 | 18593.9 | 15695.5 | 74450 | 45718.3 | 12223.2 | 16508.5 | 4370.5 | 2515.09 | 458.541 | 1396.87 |
| 5 | 北海道 | 5611.51 | 3259.33 | 1737.72 | 927.762 | 593.843 | 2352.19 | 1243.08 | 718.739 | 390.37 | … | … | … | … |
| 9 | 中部 | 20413 | 9664.64 | 5755.83 | 2209.13 | 1699.69 | 10748.3 | 6301.6 | 1756.33 | 2690.37 | … | … | … | … |
| 15 | アジア州 | … | … | … | … | … | … | … | … | … | 2357.49 | 1342.5 | 317.17 | 697.823 |
| 16 | ヨーロッパ州 | … | … | … | … | … | … | … | … | … | 621.551 | 252.744 | - | 368.807 |
| 72 | 8泊以上 | 1481.72 | 1481.72 | 130.941 | 746.332 | 604.443 | … | … | … | … | 625.676 | 252.649 | 180.521 | 192.506 |
するべきことを考えます。
将来的には特徴量を増やしていきますが、現段階ではデータを最小まで削っていきます。
また、データが複数ファイルに跨っているため、結合することを念頭に置いて作業します。
まず、先頭4行は各列の説明なのでいらなさそうです。
代わりにカラム名を追加します。
col = ["ind","dom","stay","stay_tour","stay_home","stay_work","day","day_tour","day_home","day_work","abr","abr_tour","abr_home","abr_work"]
df.drop([0,1,2,3],inplace=True)
df.columns = col
df.head(13)
| ind | dom | stay | stay_tour | stay_home | stay_work | day | day_tour | day_home | day_work | abr | abr_tour | abr_home | abr_work | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 4 | 主目的地 1) | 149598 | 75147.6 | 40858.2 | 18593.9 | 15695.5 | 74450 | 45718.3 | 12223.2 | 16508.5 | 4370.5 | 2515.09 | 458.541 | 1396.87 |
| 5 | 北海道 | 5611.51 | 3259.33 | 1737.72 | 927.762 | 593.843 | 2352.19 | 1243.08 | 718.739 | 390.37 | … | … | … | … |
| 14 | 沖縄 | 1884.13 | 1710.98 | 1274.78 | 218.553 | 217.643 | 173.15 | 164.164 | 8.98596 | - | … | … | … | … |
| 15 | アジア州 | … | … | … | … | … | … | … | … | … | 2357.49 | 1342.5 | 317.17 | 697.823 |
| 20 | 大洋州 | … | … | … | … | … | … | … | … | … | 216.617 | 149.536 | 22.4445 | 44.6358 |
| 21 | 同行者 2) | … | … | 40858.2 | 18593.9 | … | … | 45718.3 | 12223.2 | … | 4370.5 | 2515.09 | 458.541 | 1396.87 |
次に不要なデータを考えます。
合計値を表している
・「dom」(国内旅行の合計)、
・「stay」(宿泊旅行の合計)、
・「day」(日帰り旅行の合計)、
・「abr」(海外旅行の合計)
は現段階で不要そうです。(特徴量エンジニアリングの段階で作るかもしれませんが。)
また、旅行地ごとの合計である「主目的地 1)」も同様の理由で不要そうです。
「太平州」以降の行も旅行地をだけ欲しいため、今回は不要なため削除します。
次に国外、国内の区別も必要がないため、「abr_〜」を「stay_〜」に移します。
最後に[...]を0に置き換え、インデックス名を扱いやすい名称に変更します。
df.drop(4,inplace=True)
df = df_[:16]
df.drop(["dom","stay","day","abr"],axis=1,inplace=True)
df.loc[15,"stay_tour"] = df.loc[15,"abr_tour"]
df.loc[15,"stay_home"] = df.loc[15,"abr_home"]
df.loc[15,"stay_work"] = df.loc[15,"abr_work"]
#~~~ 海外である15〜20まで同じ処理をします。 ~~~~
df.loc[20,"stay_tour"] = df.loc[20,"abr_tour"]
df.loc[20,"stay_home"] = df.loc[20,"abr_home"]
df.loc[20,"stay_work"] = df.loc[20,"abr_work"]
ind = ["Hokakido","Touhoku","Kanto","Hokuriku","Tyuubu","Kinki","Tyuugoku","Shikoku","Kyusyu","Okinawa","Asia","Europ","N_America","S_America","Africa","Oceania"]
df.drop(["abr_tour","abr_home","abr_work","ind"],axis=1,inplace=True)
df.replace({"-" : 0, "…" : 0},inplace=True)
df.index = ind
df = df.T
df
| Hokakido | Touhoku | Kanto | Hokuriku | Tyuubu | Kinki | Tyuugoku | Shikoku | Kyusyu | Okinawa | Asia | Europ | N_America | S_America | Africa | Oceania | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| stay_tour | 1737.721011 | 3043.499685 | 10697.296494 | 4273.182148 | 5755.830116 | 6672.438355 | 2280.453698 | 1041.401360 | 3716.095664 | 1274.783622 | 1342.499158 | 252.743681 | 668.267156 | 0.000000 | 10.227739 | 149.536219 |
| stay_home | 927.761814 | 2117.715278 | 4264.654992 | 1282.015880 | 2209.126004 | 2501.629173 | 1470.903571 | 783.698030 | 2602.973023 | 218.552779 | 317.169702 | 0.000000 | 118.927178 | 0.000000 | 0.000000 | 22.444501 |
| stay_work | 593.843450 | 843.208004 | 5043.218581 | 447.366516 | 1699.685148 | 1886.816289 | 1013.059323 | 1165.977649 | 2714.423528 | 217.642672 | 697.823265 | 368.807023 | 207.017894 | 28.723752 | 10.919591 | 44.635789 |
| day_tour | 1243.077244 | 2683.346907 | 16264.217815 | 3304.452841 | 6301.603797 | 8089.388914 | 2241.074735 | 1048.740441 | 4090.347226 | 164.164248 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 |
| day_home | 718.738855 | 1275.640003 | 3650.657067 | 981.325378 | 1756.333664 | 1476.630386 | 1033.856475 | 176.768113 | 974.601011 | 8.985964 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 |
| day_work | 390.370434 | 1107.492062 | 5573.149393 | 548.348389 | 2690.372265 | 2765.073465 | 1377.506195 | 236.926044 | 1560.843464 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 |
(Excelファイルからそうなのですが、単位が千人なのに小数点6桁ある。。。)
Gitにソースあげました。正直Gitの方が見やすいです。
後編に続く