Splunkでのデータ取り込みを最適化してみる
Overview
Splunk自体は、データをとりあえずForwarderから入れれば自動でsourcetypeを判別して、適切なFormatを
選択してくれる。便利なので、それを使えばいいのだけれど、実はいくつかTipsがあって、それを設定することで、データ取り込みのPerformanceを最適化できるのだ。
How to
configを直接編集してもいいのだけれど、typoも多し、面倒なので今回はHeavy Forwarderを使ってconfigを作ってみる。
ちなみに下記の設定を入れるいれないで数倍取り込みperformanceが変わると言われているので、いれたほうがいい。
編集するところは
- Timestamp
- Timeprefix
- LOOKAHEAD
- TZ
- SHOUDLINE MERGE
Timestamp
Splunkにログインして、データを取り込んで見る(Setting → Add Data)
Apacheのデータをとりあえずいれてみる
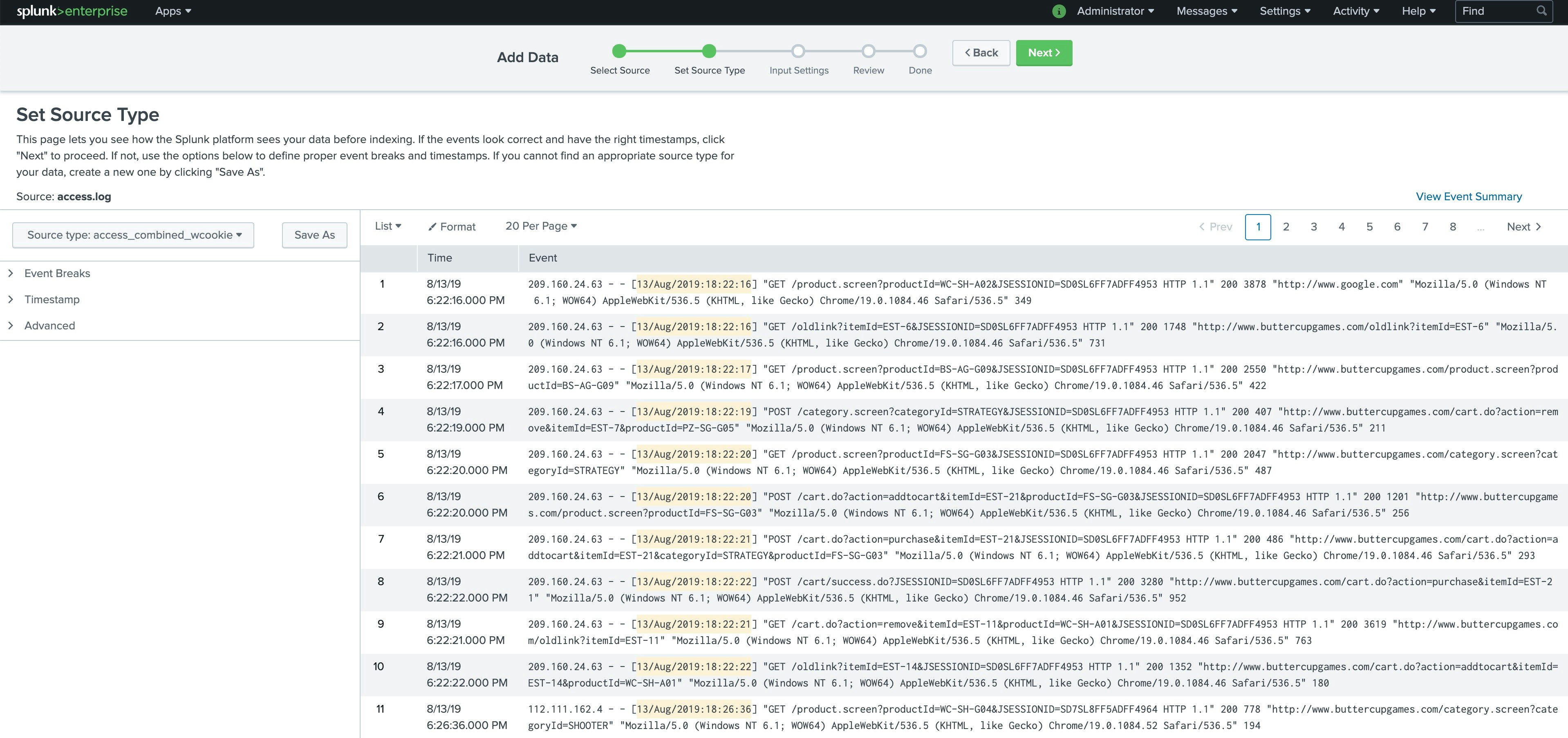
取りこんだ段階では、splunkが自動でapacheのformatと介錯して、sourcetype:access_combined_wcookiesを選択してる。
Timestampを編集
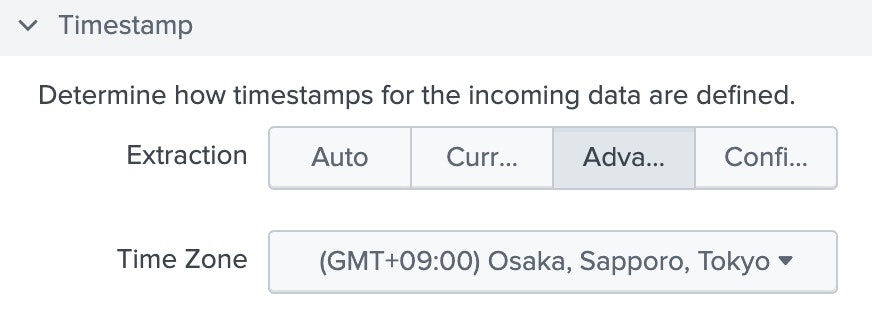
Timezoneを編集
ログの表してるtimezoneを選択する
Timestamp formatを選択する
ログのtimestampのformatを編集する。ドキュメントは下記を参照。
今回は
13/Aug/2019:18:22:16
というformatなので
%d/%b/%Y:%H:%M:%S
として、Timestamp formatの箇所に書く

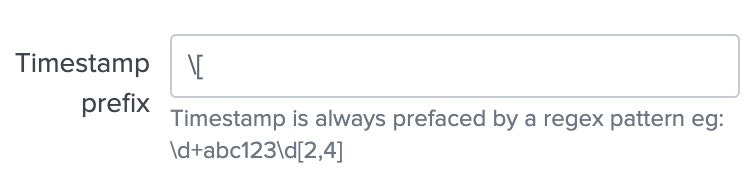
Timestamp prefixを編集
timestampが何で始まるかをregexで書いてあげる。今回は[ではじまるので
とする。
LOOKAHEADを編集
LOOKAHEADはtimestampの文字数をカウントするもの。今回は20文字なので

SHOULDLINE MERGE
イベントをどうまとめるかを定義するもの。基本はfalseでいいけど、xmlとか、exceptionのログとかだとtrueにする必要があるものが多いので、その都度。

これで保存すれば、OK。
補足
ちなみに、編集したファイルは、props.confとして保存される。
qiita.rb
#cat /Applications/splunk731/splunk/etc/apps/search/local/props.conf
[access_combined_wcookie_custom]
BREAK_ONLY_BEFORE_DATE =
DATETIME_CONFIG =
LINE_BREAKER = ([\r\n]+)
MAX_TIMESTAMP_LOOKAHEAD = 20
NO_BINARY_CHECK = true
REPORT-access = access-extractions
SHOULD_LINEMERGE = false
TIME_FORMAT = %d/%b/%Y:%H:%M:%S
TIME_PREFIX = \[
TZ = Asia/Tokyo
disabled = false
pulldown_type = true