TL;DR
- GraphQLはクライアント側とサーバー側の双方の複雑化を解決するために利用されてる
- フロントエンドにとってGraphQLはHTTP上で動く信頼できる唯一のリソースとして振る舞う
- フロントエンドの状態管理のベストプラクティスとしてのApollo Client
- クライアントファーストなAPI, GraphQLはWeb APIのベストプラクティスになり得る
- クラシックアプリケーションを改修することなくGraphQLとモダンフロントエンドで今どきのアプリを作れる
はじめに
GraphQLは非常に良く出来たソフトウェア(の仕様)ですが、複数の側面を持つことからすぐに理解することが難しくまだ日本ではあまり受け入れられていない印象があります。GraphQLを端的に何と言われると "全てのフロントエンドのためのAPI BFF" なのですが、それだけで理解出来る人はなかなか居ないように思います。この記事ではGraphQLがどのような背景で使われてきて、何を解決し、その結果どう今後のWebが変化していくかについて書いてみたいと思います。抽象的な概念的な話をするので詳細な実装については触れません。実装についてはGraphQLで最も大きなエコシステムであるApolloのドキュメントがとてもよく整備されているのでここを読むことをおすすめます。
またGraphQLを一度も利用したことがない方は、https://github.com/APIs-guru/graphql-apis の中から2,3つ利用して見るとどんなものかざっくり把握出来るかと思います。(個人的にはポケモン, スターウォーズ、Spotifyあたりが好きです。) GraphQLのAPIを使ってみるとAPIの裏側がどう実装されているのか全く気にせず使えるのがわかると思います。
ではいってみたいと思います。
GraphQLが利用されて来ている背景
まずはじめに昨今のWeb開発のトレンドとGraphQLが出てきた背景から入りたいと思います。
フロントエンド
この記事ではフロントエンドの定義は、ユーザーの手元で動く終端のアプリケーションの事として扱います。PCブラウザ向けのアプリケーション, iOS, Android, ウェアラブルデバイス上のアプリケーション全てを含みます。PCブラウザ向けのアプリケーションは別途, Webフロントエンドとして記述します。
フロントエンドのマルチプラットフォーム化
近年では従来のPCブラウザ向けのWebアプリケーションの開発に加えて、iOSやAndroidのスマートフォンデバイス向けのNativeアプリや,Apple WatchやFitbitなどのウェアラブルデバイス, Electronを中心としたデスクトップアプリなどデータリソースを扱うクライアントを複数種類扱うマルチプラットフォーム向けのアプリケーションをWebの技術を利用して開発をするのが一般的になってきました。各デバイスのクライアントアプリはサーバー側から提供されるWeb APIを利用し、レンダリングロジックを持つアプリケーションです。各デバイスのクライアントアプリケーションは同じサービス(広義のサービス, Facebook, Instagram, Twitterなど)でありながらプラットフォーム毎に異なるUIを持ち、それぞれ少しずつ異なるデータをAPIに要求します。従来はこれらの要求に答えるためにそれぞれのプラットフォーム毎のAPIの中間層(API Aggregation としてのBFF)を用意したり、すべてのユースケースに網羅した大量のデータを送りつけるAPIの提供(オーバーフェッチに繋がる)したりしていました。というのもこのようにクライアントが複雑化、多様化するとサーバーサイドにそれらを要求する事になりサーバーサイドのAPI実装の負担が増加するため全てに対応することは開発リソースの都合上難しいためです。
リッチフロントエンド化
同時にWebフロントエンドではReact.js, Anglur.js, Vue.jsなどのコンポーネントライブラリやそれらを利用したプログレッシブフレームワーク(Next.js, Nuxt.js)などが台頭し、クライアントサイドレンダリング(CSR)が一般的になった結果、APIも複雑なものを要求されるようになってきました。
フロントエンドのアプリケーション特性
フロントエンドのアプリケーションは特性として製品のライフサイクルやリリースサイクルが短いためAPIに対しての要求は常に変化します。またユーザーのデバイスやネットワーク環境によって動作環境が左右することから要求も厳しくなります。こうしてフロントエンドのアプリケーションをより良いものにするためにAPIへの要求は厳しいものになり、その分サーバーサイドの実装負担が増えます。
サーバーサイド
マイクロサービス化
Dockerが一般的になってきた2010年代中盤以降, MicroservicesやServerlessなど複数のアプリケーション、複数のデーターベースを組み合わせて実装するサーバーサイドのアーキテクチャパターンが一般的になってきました。それぞれのエンドポイントは一般的には異なる言語異なるフレームワークで実装されそれぞれ異なった仕様を持つことが多いため、エンドポイントの利用者とのコミュニケーションコストを出来るだけ少なくするためにOpen API等の仕様に従ったAPIドキュメントの作成が推奨されてきました。異なる仕様のAPIが増えれば増えるほど、フロントエンドの実装負担は大きくなります。
サーバーサイド主体のAPI設計
またサーバーサイドのアプリケーションやデータベースはフロントエンドのアプリケーションと比べると長命で一度作られたものは変化させにくい性質があります。実装は、データソースに近いためデータソースに都合の良い実装になる傾向があります。そのため、フロントエンドから要求されるAPIの仕様とは相反する実装になります。特にREST APIはデータベースのテーブル構造そのままのようなAPIの実装を促進してしまう気がします。
これらの理由からAPIはサーバーサイドの都合で設計されてきました。
需要と供給での双方の要求を受ける中間層としてGraphQLを導入する
需要と供給の双方で複雑化が進んだ結果、双方に取って利用しずらいものに変化していきます。その結果、複雑になりすぎたアプリケーションはコミュニケーションコストの増加が原因で開発効率が減少していきます。APIの複雑さはそのままそれを開発・運営する人のコミュニケーションの複雑さになります。下の図でいうと1つの線毎に人と人のコミュニケーションが発生します。クライアントやサービスが増える度にコミュニケーションは二次関数的に増えます。
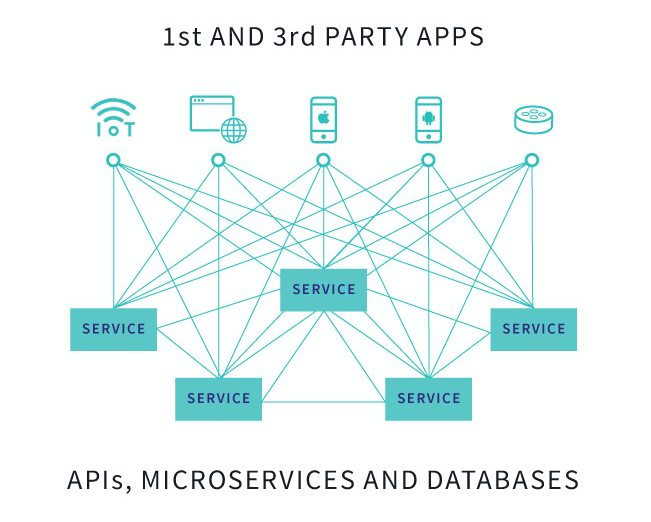
出典: Tech Crunch - Apollo raises $22M for its GraphQL platform
GraphQLはそのような背景から登場してきました。GraphQLはフロントエンドとサーバーサイドの間に入り双方のプロキシの役割を果たします。フロントエンドはAPIサーバーへリクエストしていた代わりにGraphQLアプリケーションにリクエストを送ります。リクエストを受け取ったGraphQLアプリケーションはクエリをパースし、設定されているデータ元にリクエストを送ります。
フロントエンドはサービス全体が持つ全てのデータにアクセス可能になり、すべてのフロントエンドは単一のGraphQLアプリケーションに繋がります。またすべてのサーバーサイドアプリケーションも同様にGraphQLに繋がります。
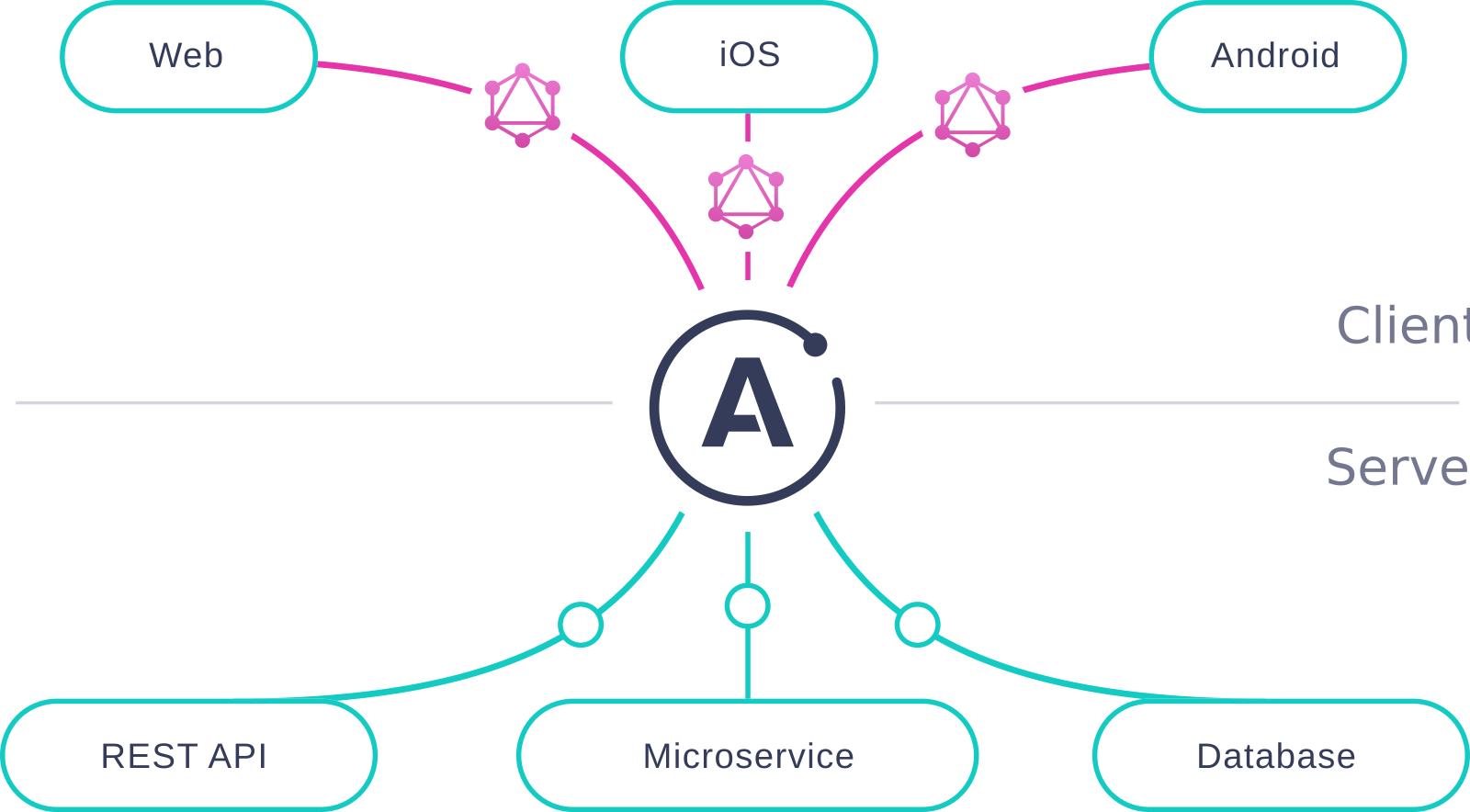
出典: https://www.apollographql.com/docs/apollo-server/
従来のAPI設計では "フロントエンドの数 x APIエンドポイントの数" だけ利用パターンがあったのに対し、GraphQLで実装したAPI設計では全てのフロントエンドは単一のAPIエンドポイントのみを利用し、サーバーサイドはGraphQLアプリケーションが単一のクライアントになるため、フロントエンドの数 + エンドポイントの数 に変化します。掛け算が足し算になることで二次関数的に増えていく組み合わせをリニアな増加にすることが可能になります。
フロントエンドとサーバーサイドの関心の分離
GraphQLはフロントエンド側とサーバーサイド側の責務を完全に分離する事が出来ます。
例えば, Webフロントエンドアプリケーションとして Nuxt.js, サーバーサイドAPIとして Ruby on Rails で実装しているアプリケーションがあったとします。 そこにGraphQLを中間に実装することにします。
アーキテクチャ構成から見ればアプリケーションが多くなる分複雑に見えるかもしれませんが、フロントエンドとサーバーサイドを分けて考えると見え方が変わります。

この様にフロントエンドからはGraphQLが単一のデータソースの様に見え、 サーバーサイドから見ればGraphQLが単一のクライアントとして振る舞います。開発ではフロントエンド、GraphQL、サーバーサイドAPIの3つのチームに分かれることになります。
GraphQLはフロントエンドからみた場合とサーバーサイドから見た場合に全く違う側面を持っています。ですのでそれぞれの側面から見たGraphQLについて説明してきたいと思います。
フロントエンドから見るGraphQL

フロントエンド側でよく言われるGraphQLの仕様によるメリット
よく話に上がるメリットを先に羅列しておきます。フロントエンドでGraphQLの話が出るときはだいたいこのあたりなので気になる方は調べてください。
- リクエストもレスポンスも型安全である事
- Self-documenting(自己文書化)である事
- Generatorがあるためフロントエンドでレスポンスを型安全で利用出来る事
- TypeScriptと相性が良い事
- 要求した通りのレスポンスが返るためオーバーフェッチにならない事
フロントエンドにとってGraphQLはHTTP上に動く信頼できる唯一のリソース
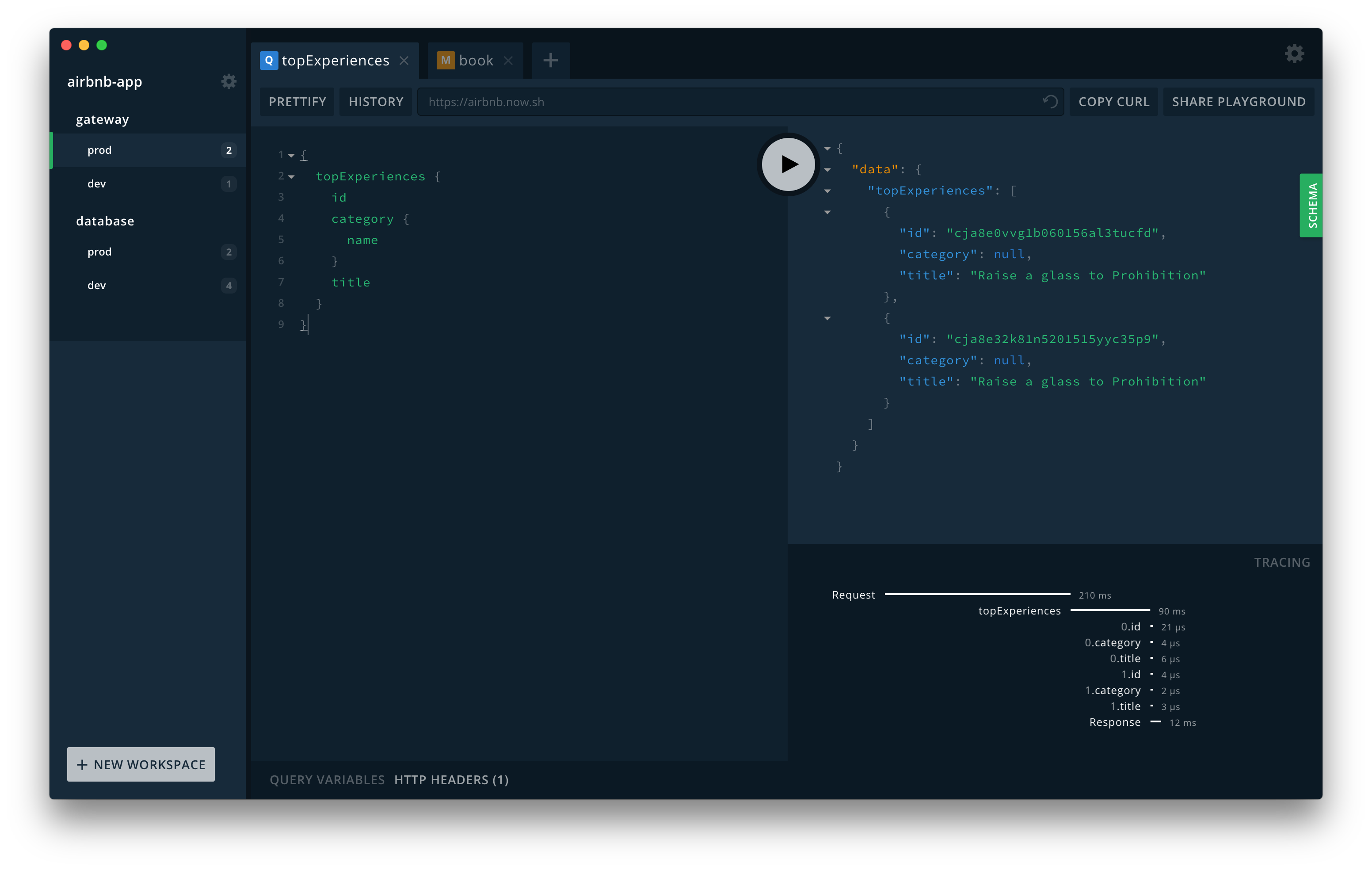
出典: Apollo Docs - GraphQL Playground
GraphQLはその名の通りQuery Languageです。似た名前のものにSQLがありますがSQLはDBMSで使われる言語でデータベース操作の時に使います。GraphQLではGraphQLクライアントがGraphQLアプリケーションに対してクエリを発行し、要求されたクエリ通りのオブジェクト構造(JSON形式)のデータが返されます。そのためGraphQLクライアントはクエリの方法と返ってくるデータさえ知っていればサーバーサイドの仕様を一切知る必要がなく開発が可能になります。
従来のREST APIはサービスの本体であるサーバーアプリケーションが持つデータを取得するために、データの性質毎にRESTFulに表現されたデータの集合を返す関数(RPC)を実行し、フロントエンドはそれらのAPI(関数)を複数実行し組み合わせることでサーバーサイドアプリケーションが持つデータをシミュレートして動作してきました。そのためフロントエンドは各関数の動作方法や、それらの関数がまた別の関数にどう繋がるのかをドキュメントから読み解く必要がありました。
REST API と GraphQL API は、"抽象化されたデータを操作する複数の関数" と "唯一のリソースとクエリ" の対比になると思うとイメージしやすいと思います。
GraphQLを利用することでフロントエンドはサーバーサイドが提供するAPIのフレームワーク都合で異なる仕様、APIの設計思想(SOAPやRESTFul)などを知る必要がなくなります。
GraphQLはSchemeでリレーションやデータ型があらかじめ提供されており、GraphQL Playgroundという実行環境から利用可能でこれが実行可能なドキュメントとして機能するため、エンドポイント毎にAPIドキュメントを読む必要がなくなります。
GraphQL APIでは、アプリケーションが持つ全てのデータへアクセス出来る単一のデータベースの様に振る舞うことで、データとデータのリレーションがスキーマによって完全に表現されたデータ全体へのアクセスが出来るようになりました。フロントエンドはこれらのデータを利用して、ユースケースに合わせたデータを引き出し、また変更要求を送ることでGraphQLアプリケーションと対話しながらUIを構築しユーザーに届けます。
ここまでグラフ理論の話が出てきていないのですが、フロントエンドから見たGraphQLは実際あまりグラフ構造を理解する必要性はあまりないように感じます。クエリを書けばほしい形のJSONを返してくれるAPIとだけ認識しておけば問題ないと思います。
フロントエンドの状態管理のベストプラクティスとしてのApollo Client
GraphQLの仕様そのものとは関係がありませんが、GraphQLの仕様に合わせて独自に進化してきたApollo ClientがGraphQLのメリットの一つになりつつあるため紹介します。
Apollo Client はJavaScriptで記述されたGraphQLのクライアントで、JavaScriptの中ではデファクトスタンダード的な扱いです。React.js向けに記述されていますが、他のライブラリ(Angluar.jsやVue.js)向けもあります。iOS向けやAndroid向けもあります。
Apollo Clientとは何ですか?
Apollo Clientは、JavaScriptアプリ用の完全な状態管理ライブラリです。GraphQLクエリを記述するだけで、ApolloクライアントがUIの更新と同様にデータのリクエストとキャッシュを処理します。
Apolloクライアントを使用してデータを取得すると、最新のReactベストプラクティスと一致する予測可能な宣言的な方法でコードを構造化できます。Apolloを使用すると、データ配管の定型文を書く手間をかけずに、高品質の機能をより速く構築できます。
出典: https://www.apollographql.com/docs/react/
Apollo ClientではGraphQLのクエリの発行を行うクライアントとしての振る舞いを持つ事はもちろんですが、レスポンスとして受け取ったデータを(通常メモリ上に)キャッシュします。そしてこのキャッシュを使った状態管理が非常によく出来ています。ApolloClientはクエリを発行するとローカルのキャッシュに問い合わせ、データが無ければリモートのGraphQLサーバーに問い合わせを行う仕組みになっているため、クライントを利用するJavaScriptのコードからすればリクエストしたデータがローカルに存在しているかどうか、ネットワーク上に取りに行く必要があるのかを気にすることなくデータへのアクセスを行うことが出来ます。ローカルのキャッシュへのアクセスもネットワーク越しでのデータアクセスも同様のクエリで実行します。キャッシュの利用の有無や別のクエリでのデータの使い回しなどは柔軟に設定出来ます。
従来はFlux, ReduxやVuexなどの状態管理ライブラリを使う事が一般的でしたが、Apollo Clientを利用することでフロントエンドの状態管理の実装がかなり楽になりました。
Apollo Clientのケーススタディとして、メジャーリーグサッカーのアプリケーションでは5000行近くのReduxのコードを削除することに成功した事例が掲載されています。
GraphQLはフロントエンドにとって再利用性の高い技術
GraphQLをもし全てのアプリケーションに適用するとしたら以下のような図になります。
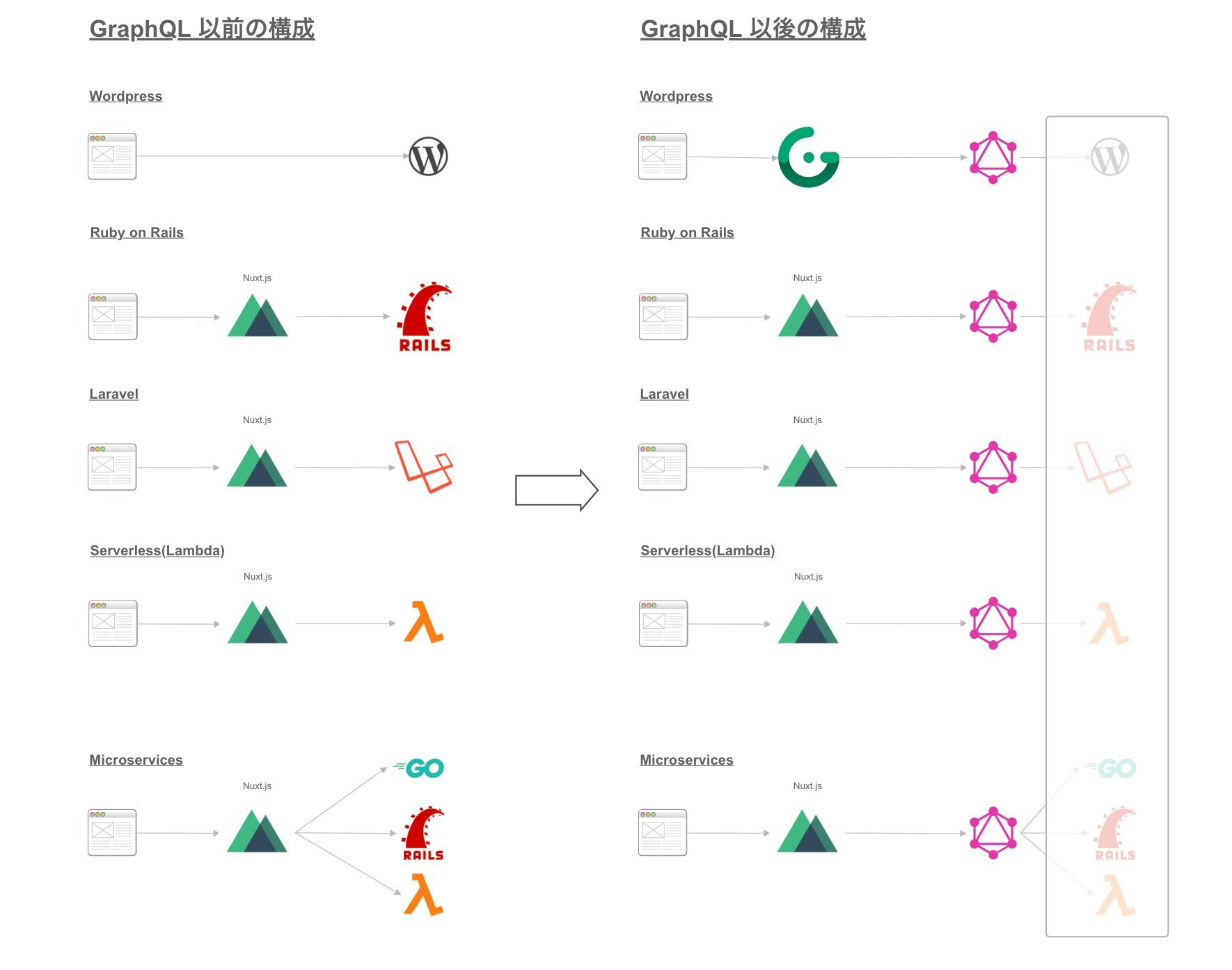
このように、フロントエンドから見ると全てのサーバーサイドアプリケーションはGraphQLアプリケーションに隠蔽されます。GraphQLを利用することでクライアントはサーバーサイドの実装を一切気にすることなく、フロントエンドの実装に集中出来ます。サーバーサイドアプリケーションが何であれ、GraphQLの利用方法は常に同一なため、GraphQLを利用していればどのようなアプリケーションに対しても同様に実装することが出来るため再利用性の高い技術といえます。
またiOS, Androidなどからも同様にGraphQLにアクセス出来るため、同一のGraphQLAPIを利用して異なるプラットフォームのクライアントアプリを実装することが出来るためマルチプラットフォーム化、マルチクライアント化がしやすくなります。
GrraphQLが解決したフロントエンドの課題
- API利用のコミュニケーションの増大問題を解決した
- API毎に異なる仕様を学習するコストをなくすことが出来る(ドキュメントを読む量が減る)
- フロントエンドの状態管理をApollo Clientが解決した(しそう?)
サーバーサイドから見たGraphQL

次にサーバーサイドからみたGraphQLについて紹介していきたいと思います。ここでようやくグラフ理論や実装の概念が出てきます。
GraphQLの動作手順
GraphQLはグラフ理論と木で説明出来ます。GraphQLのコンセプトについてはこちらがわかりやすいです。
用語
グラフ理論の用語として
- ルート
- ノード
- 木
GraphQLの用語として
- Scheme
- Data Type
- Query
- Resolver
- DataSource
が出ます。
可視化されたコンセプト
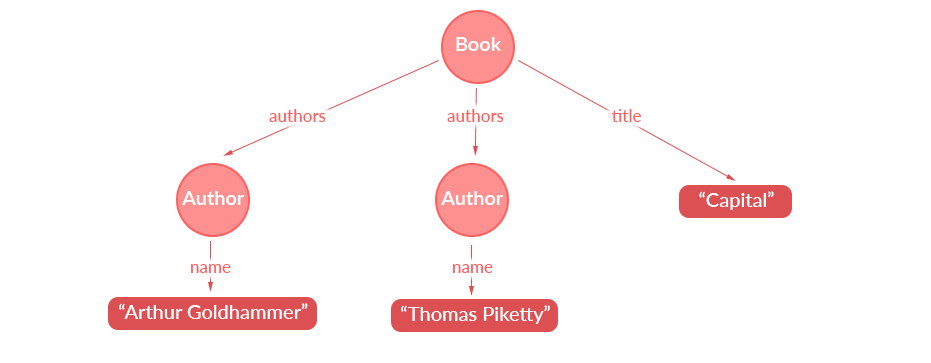
Schemeを可視化したグラフ図
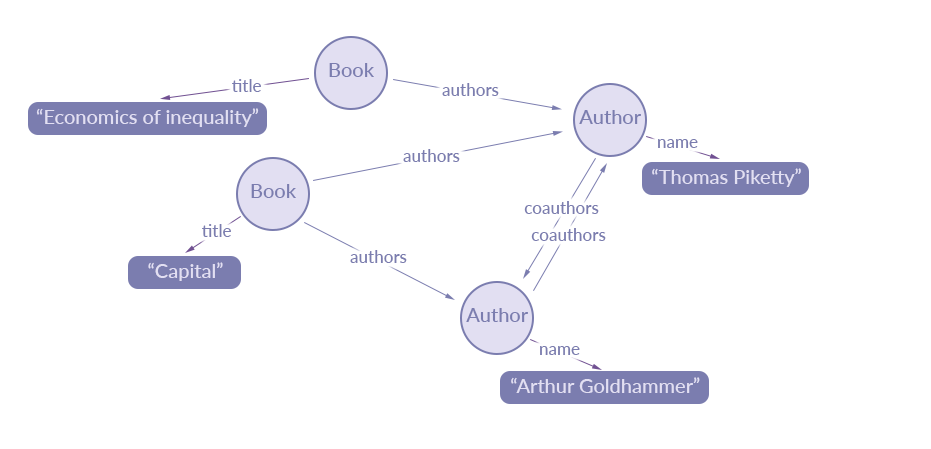
Queryで取得するノード
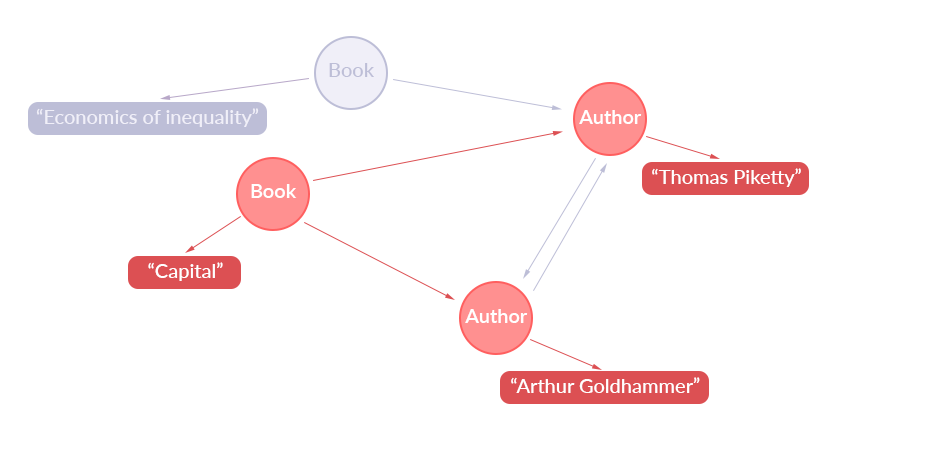
Queryをパースした後に構築される木
出典: GraphQL Concepts Visualized
Schemeで宣言されたデータ構造はグラフ構造の様につながることが出来ます(グラフ構造を利用するので"Graph"QL)。そしてデータを取得するQueryを発行するとQueryは木としてパースされます。
GraphQLの動作原理
- Schemeでデータやオブジェクトのリレーションをあらかじめ宣言する。宣言されたSchemeはグラフ構造になる。
- クライアントはQueryを利用しデータの取得を行う。Queryはあるノードをルートとした木構造を取り出す操作
- パースされて構築された木のノードをどう解決するかを記述した関数(Resolver)が上位から段階的に呼び出され解決していく。
- ResolverはDataSourceクラスの関数を呼び出す。DataSourceは HTTPリクエストを送るものやDBへSQLを発行するもの、ファイルを読み込みなどを記述したクラス。
- 全てのノードのresolveが終わると、レスポンスを返す
と整理すればそんなに難しくないなと思うのではないでしょうか。(?) GraphQLは単純に整理すると、グラフで表現出来るSchemeと、グラフから木を取り出すQueryと、ノードを解決する関数を持つプログラムが動くHTTPアプリケーションです。そこにDataSourceを繋げたり、HTTP仕様に則った制御(認証やキャッシュ)などを利用することで複雑なAPIを提供することが出来ます。
多種多様のDataSource
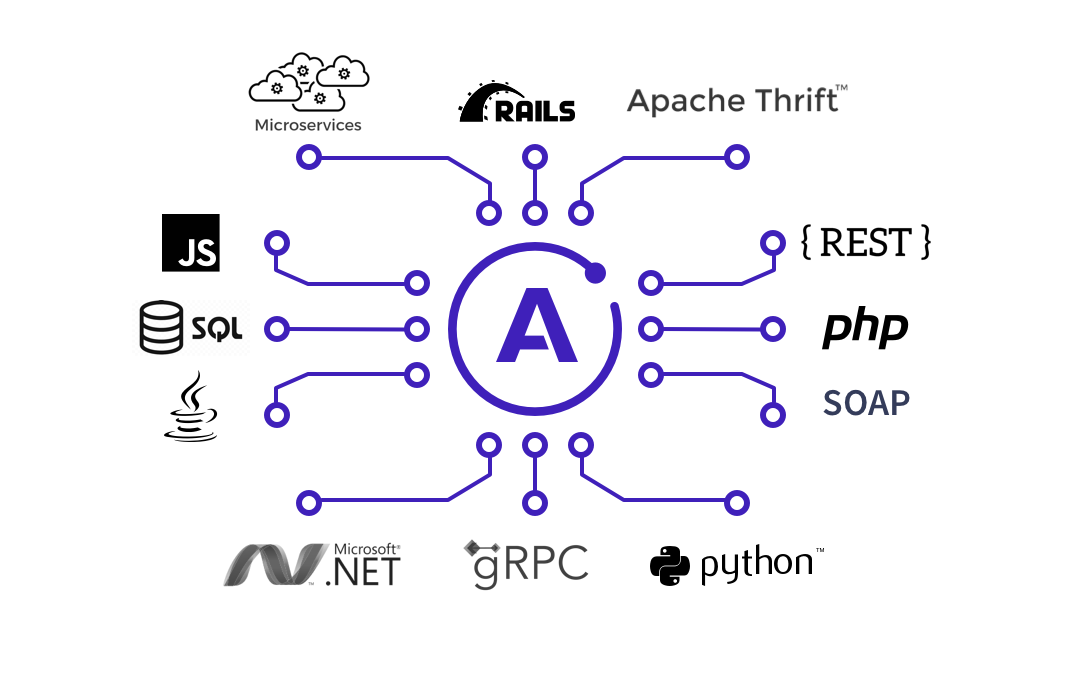
出典元: https://www.apollographql.com/platform
Apollo PlatformではGraphQLをこのように表現しています。GraphQLではデータを保持しているサーバーやアプリケーションをDataSourceと呼び、ありとあらゆるAPIに繋がります。HTTPで提供されたREST API, SOAP, gRPCで提供されたアプリケーション, データベースなどなど。というのもノードを解決するResolverは単なる関数のため、プログラムで利用可能なデータはすべて利用可能です、実質何でも良いです。
DataSourceの例
- Ruby on Railsで実装されたREST APIを利用するHTTPクライアント
- SOAPで実装されたAPIを利用するHTTPクライアント
- gRPC + Goで書かれたAPIを利用するgRPCクライアント
- MongoDB クライアント
- Redis クライアント
- Elastic Search クライアント
- S3クライアントとファイルリーダー
- Excelを読み込むリーダー
- ソースコードベタ書きのオブジェクト
- スクレイピングで取得したデータ
DataSourceはシングルトンなサービスクラスで接続先となるAPI毎に作成します。APIへのリクエストを行う関数を定義し、Resolverから利用されます。実際のAPIの処理をカプセル化し、Resolverからは処理が隠蔽された形で実装すると責務分離しやすいです。
GraphQLアプリケーションの実装は
- Schemeの定義
- 定義されたノード(TypeやField)のResolver関数を実装
- DataSourceでAPIの呼び出しなどを実装
の3つを行っていくことになります。
GraphQLを入れることでのサーバーサイドへのメリット
GraphQLAPIを利用するクライアント開発チームとのコミュニケーションコストが下がる
Schemeを定義することでクライアントはSchemeとQueryの仕様を読み解くことが出来、Schemeには適宣コメントを付与していくことが出来るため、Schemeが事実上のAPIドキュメントになります。そしてクライアントからはサーバーサイドが隠蔽されているためAPIの実装方法について伝える必要もありません。データソースとなるAPIを開発するチームはGraphQLを実装するチームとだけコミュニケーションを取れば良いことになります。
サーバーサイドから見ると単一のクライアント
GraphQLを利用するとサーバーサイドのAPIから見るとクライアントがフロントエンドからGraphQLのResolver, DataSourceが代わりにリクエストしてくることになります。
これまでは、フロントエンドが直接のクライアントであったため、フロントエンドでの制約を考慮する必要がありました。
- 過酷なネットワーク環境、デバイス環境を考慮した最小限のデータ送信
- UI毎に異なるデータ形式
- etc..
GraphQLがフロントエンドのプロキシとしてリクエストを送ってくることでサーバーサイドのAPIの設計が比較的やりやすくなります
- フロントエンドのユースケースについて過度に意識せずにAPIの設計が出来る
- ネットワークでボトルネックになることがフロントエンドほど考慮する必要がないため、レスポンスをデータ量多く返しても良い(オーバーフェッチ上等)
- GraphQLの層でデータのキャッシュを検討することが出来る
- プライベートネットワークからのリクエストに変わるため、セキュリティやパフォーマンスで考慮することを減らせる
- GraphQLアプリケーションはサーバーリソースをコントロール出来るため、スケールアップ・スケールアウトでパフォーマンス制御が可能
クライアントファーストなAPIデザイン
サーバーサイドのアプリケーションやデータベースは基本的にフロントエンドよりも長命で変更が容易ではないため、ある程度汎用的なAPIデザインにせざる終えません。RESTFulではデータベースのテーブルをそのまま再現したようなAPIが多く存在します。しかしこれらのAPIはクライアントからすると必ずしも使いやすいデザインではないケースが多々あります。サーバーサイドの都合を考慮しそのしわ寄せをクライアントが受け持ってきたことがフロントエンドの実装生産性を下げているのが現状でした。
しかし、GraphQLはクライアントとサーバーサイドの間に位置しAPIをデザインすることが出来ます。APIデザインは必ずしもデータソースが返すレスポンスをそのまま返す必要がなく、GraphQLが自由にAPIデザインすることが出来ます。そのため、GraphQLでのAPIデザインはクライアントのユースケースに沿った、クライアントにとって都合の良いクライアントファーストなAPIデザインを行えます。同時にサーバーサイドはサーバーサイド都合のAPIを実装することが出来ます。GraphQLが入ることでクライアントとサーバーサイドでの両者の摩擦を軽減します。そのため、GraphQLはWeb APIデザインのベストプラクティスになり得るのではないかと思っています。
例
- 複数のデータソースから取得したデータを1つのノードとして表現する
- 1つのデータソースから取得したデータを複数のノードとして表現する
- データソースには存在しない抽象的なデータを表現する
- 複数レコードにまたがるデータを1つのノードの1つのフィールドとして配列で表現する
- 配列のデータを複数のノードとして表現する
アプリケーション、データストアの変更容易性
まずはMicroservicesについて振り返っておきます。GraphQLの直接のメリットではないですが、GraphQLを導入する場合サーバーサイドも複数アプリケーションが存在することが多いためです。
Microservicesのメリットの一つに、"サービスの内容によって言語やフレームワーク、データソースを柔軟に選択することが出来る" というものがあります。Microservcies以前は、出来るだけ言語、アプリケーションやデータベースを1つずつ選択するのが通例でした。そのため、汎用的に何でもこなせるモノリシックアーキテクチャ、リレーショナル・データベースが選択される傾向にありました。そのためモノリシックアーキテクチャに過度な期待を寄せたり、ツールの苦手な部分を批判するような状況にありました。
Microservices以降はサービスの内容毎に言語やフレームワーク、データソースを適材適所で複数組み合わせて採用する事が出来るようになります。
Microservicesなアーキテクチャを採用することで以下のような設計を可能にします
- 20%しか利用されない80%の機能は開発効率が高い言語・アプリケーションに任せ、80%利用される20%の機能は高速で堅牢に構築出来る言語, ツールで構成されたアプリケーションに任せる等の意思決定が出来る
- リレーショナル・データベースで始めたがオブジェクト型のデータベースに保存したほうが良いことが、ある程度運用したあとに発覚したため移行する
- チームの採用状況に応じた言語選択
Microsevicesはサービスを細分化する事もありますが、本質はサービスの統廃合を繰り返すことにあると思います。そしてGraphQLはAPIの抽象化を行うことでMicroservicesの本来のあり方であるAPIの統廃合を促進します。
GraphQLを採用することで、サーバーサイドのAPIの変更容易性が上がりその結果、アーキテクチャ設計をそのタイミング毎に選定し将来においてはその都度変化させていけば良いと未来に楽観的に設計が出来るようになります。安心してモノリスで始めたり、チームメンバーのその時のスキルセットに合わせて技術選定が出来るようになります。アーキテクチャ設計の遅延決定を行うことが出来るようになる事がGraphQLを利用するサーバーサイド側のメリットの1つになると言えます。
クラシックアプリケーションを現代風にアレンジ
個人的にはGraphQLはモダンな最新技術を使いこなすチームのためだけの道具ではなく、すでに10-20年稼働しているクラシックなアプリケーションにこそ必要な技術だと思っています。
GraphQLは既存のアプリケーションを一切変更することなく、新しいAPIエンドポイントとして斬新的に実装・提供することが出来ます。そのため、現行のシステムが10年前に作られたJavaのアプリケーションでも、メインフレームで動くCOBOLでも問題がありません。GraphQLアプリケーションのデータソースとしてそれらのアプリケーションをラップする最新のGraphQL APIを実装し、それを利用するモダンなフロントエンドアプリケーションを実装することで現行のシステムを一切変更することなく、ユーザビリティの高いモダンなアプリケーション開発が可能になります。
そしておそらくWebアプリケーション開発全体の市場で見れば、この市場が一番大きいのではないかと思っています。クラシックアプリケーションに変更なく、GraphQLとReact.jsでモダンなWebアプリケーションを顧客に提供する事が出来る技術と捉えると日本でもかなり利用用途は広がるはずです。銀行や公共の冴えないUIのWebアプリケーションが2020年代のモダンなフロントエンドで提供されることを想像するとこの市場は熱いと思いませんか!?
今後はGraphQLとモダンなフロントエンドフレームワークを利用した老舗企業によるモダンなアプリケーションがちらほらリリースされていくのではないかと期待しています。
GraphQLを利用することで得られるサーバーサイド側のメリットまとめ
- クライアント都合でのAPIの仕様変更を減らすことが出来る
- クライアント都合でのアーキテクチャ変更をする必要がなくなる
- クライアントの環境仕様への考慮を減らすことが出来る
- フロントエンドの状態管理をApollo Clientが解決した(しそう?)
- Microservicesを採用した場合でのAPI仕様の統一化を図るコストを減らす事が出来る
GraphQLをいつ導入するべきか
いくつかユースケースが考えられます
- フロントエンドが複数のデータソースにアクセスしている
- フロントエンドで複数のプラットフォームのアプリケーションが存在する
- サーバーサイドがMicroservicesで実装されている
- 既存のアプリケーションを変更なしにモダンなフロントエンドを実装したい
- フロントエンドでGraphQLを利用して実装したい
フロントエンドとサーバーサイドで事情が異なると思います。フロントエンドからすればGraphQLは今までのAPIデザインよりも学習コストが低く、またApollo Clientの状態管理が優秀なため、待ったなしで採用していいかと思います。サーバーサイドからすると、メリットを享受出来るのはフロントエンドとのコミュニケーションコストが増大してきたあたりになるのかなと思うのでフロントエンドの多様化・サーバーサイドの多様化が始まるタイミングでの導入検討になるのではないかと思います。また前述した通り、すでにアプリケーションが長く稼働していてなおかつモダンなフロントエンドが必要な場合は検討して損はないと思います。
TL;DR(再掲)
- GraphQLはクライアント側とサーバー側の双方の複雑化を解決するために利用されてる
- フロントエンドにとってGraphQLはHTTP上で動く単一の信頼できる唯一のリソースの様に振る舞う
- フロントエンドの状態管理のベストプラクティスとしてのApollo Client
- クライアントファーストなAPI, GraphQLはWeb APIのベストプラクティスになり得る
- クラシックアプリケーションを改修することなくGraphQLとモダンフロントエンドで今どきのアプリを作れる
おわりに
GraphQLはまだまだWebSocketで相互通信が出来るSubscriptionや、ApolloClientのOptimisticUIなど深堀りすれば更に便利な機能があります。しかし今回は多くの人にGraphQLに興味を持ってもらいサーバーサイドの方々含め議論が活発になる事を目的として書きたかったため省略しました。GraphQLはクライアント側から見る場合と、サーバーサイドから見る場合で見え方が違って来るためにフロントエンド界隈とサーバーサイド界隈では盛り上がりの熱量が違うんだろうなと思いつつ、だけどサーバーサイドから見てもアプリケーションの構成・規模によっては救世主になりえるソフトウェアだと信じています。今回はそんな気持ちで書いてみました。
ちなみに僕も3ヶ月ほどしかGraphQLを触って居なくてこの記事は3ヶ月間の調査報告のような感じです。そしてちゃんと学び始める前はGraphQLについてフロントエンドで流行ってる何か、くらいにしか思ってませんでした。しかし、調べれば調べるほどこれはめちゃくちゃおもしろいなと思い始めて今に至ります。

上のツイートはまだGraphQLを理解していない時に先入観でなんかまた新しいものが出てきたな...って思って本を購入したときのツイートです😂 もしGraphQLに興味が出た方は足がかりとしてはやはりはじめてのGraphQLから読み始めると良いと思います。僕もこれを読んで、あれこれもしかしてと思い始めてここまで学ぶことが出来ました。
所属会社
現在、株式会社EBILABでサービス業・飲食業向けのデータ統合・BI・機械学習を提供するサービスを開発しています。その中で多様なデータベース, API, CSVや独自フォーマットで保存された複数のデータソースと、WebApp・ウェアラブルデバイス・BIツール・機械学習アプリケーションと複数のクライアントがいる多対多の構造だったのでGraphQLがフィットすると判断したため導入しました。EBILABではAzure, Serverless, Apollo Server, Nuxt.js, Laravel等の構成で今は開発しています。興味ある方がいればぜひお声掛けください☺️
ツイッターのフォローもよかったらお願いします @saboyutaka
[追記 2021/07/16] [PR] Software Design 2021年8月号にGraphQLの特集を寄稿しました
Software Design 2021年8月号にて、GraphQLの特徴や解決している問題、そしてGraphQLの基本動作原理(クエリ言語、型システム、実行エンジン)について29ページに渡って特集を寄稿しました。 GraphQLを理解するための手がかりになればと思って書いたので興味ある方はぜひ読んでみてください!
