What are Hive + Zeppelin
Hiveとは公式ページにいこのように記載されています。
The Apache Hive ™ data warehouse software facilitates reading, writing, and managing large datasets residing in distributed storage using SQL.
つまり、DWH(data warehouse software)という分類がされており、
SQLを用いて分散ストレージに格納されているデータセットを読んだり、書き込みや管理ができるものです。
続いて、Zeppelinってなんぞやという話ですが、公式ページに書いてある説明は次の通りです。
Web-based notebook that enables data-driven,
interactive data analytics and collaborative documents with SQL, Scala and more.
つまり、Jupyter notebook みたいなやつってことですね。
なぜ今ごろ、この2つ??
これもみんなの疑問の一つでしょう。
理由は単純で、久しぶりにHadoopをさわる機会があったからです。
備忘録の1つ程度に書いてますので、ご容赦ください。
Installation
ambariを入れましょう。
https://docs.hortonworks.com/HDPDocuments/Ambari-2.7.3.0/bk_ambari-installation/content/ch_Getting_Ready.html
この時、HiveとZeppelin notebook にチェックを入れるのを忘れずに。
終わりです。
(なんかすごい殺気を感じる。。。)
Hands-on
準備
まず、以下からデータをとってきます。
http://archive.ics.uci.edu/ml/datasets/Iris
(Download 横の「Data Folder」を選択し、「iris.data」を選択します。)
それをHDFSがhiveを載せたサーバ上に置き、HDFSに書きコマンドで移しましょう。
$ sudo -u hive hdfs dfs -mkdir iris
$ sudo -u hive hdfs dfs -put /home/hive/iris.data iris
$ sudo -u hive hdfs dfs -ls iris
Found 1 items
-rw-r--r-- 3 hive hdfs 4851 2019-07-01 22:35 iris/iris.data
次にDatabaseを入れておくdirectoryも作っておきます。
$ sudo -u hive hdfs dfs -mkdir databases
$ sudo -u hive hdfs dfs -ls
Found 3 items
drwxr-xr-x - hive hdfs 0 2019-06-27 22:17 .hiveJars
drwxr-xr-x - hive hdfs 0 2019-07-01 22:43 databases
drwxr-xr-x - hive hdfs 0 2019-07-01 22:37 iris
Hiveを動かす
以下のコマンドでBeelineを起動しましょう。
$ beeline -u jdbc:hive2://<HIVESERVER2_HOST>:<HIVESERVER2_PORT(default:10000)> -n hive
今回、hiveというユーザで入っています。
ユーザについて見てみましょう。
0: jdbc:hive2://localhost:10000> select current_user();
+--------+
| _c0 |
+--------+
| hive |
+--------+
1 row selected (2.594 seconds)
Databaseを作成し、データをhdfsの先ほど作成したdatabasesの中に格納していきます。
0: jdbc:hive2://localhost:10000> create database iris location "databases";
0: jdbc:hive2://localhost:10000> show databases;
+---------------------+
| database_name |
+---------------------+
| default |
| information_schema |
| iris |
| sys |
+---------------------+
4 rows selected (0.074 seconds)
しっかり作成されましたね。
そしたら、そのDatabaseにtableを作っていきます。
0: jdbc:hive2://localhost:10000> use iris;
0: jdbc:hive2://localhost:10000> create table irisdata (sepal_length float, sepal_width float, petal_length float, petal_width float, class string);
0: jdbc:hive2://localhost:10000> show tables;
+-----------+
| tab_name |
+-----------+
| irisdata |
+-----------+
1 row selected (0.044 seconds)
すごいシンプルなSQL文でまずデータを入れてみます。
0: jdbc:hive2://localhost:10000> insert into table irisdata values (5.1,3.5,1.4,0.2,"Iris-setosa");
INFO : Compiling command(queryId=hive_20190706211758_5224694a-6dd1-4c7f-912a-ff1d920f1ea4): insert into table irisdata values (5.1,3.5,1.4,0.2,"Iris-setosa")
INFO : Semantic Analysis Completed (retrial = false)
INFO : Returning Hive schema: Schema(fieldSchemas:[FieldSchema(name:_col0, type:int, comment:null), FieldSchema(name:_col1, type:int, comment:null), FieldSchema(name:_col2, type:int, comment:null), FieldSchema(name:_col3, type:int, comment:null), FieldSchema(name:_col4, type:string, comment:null)], properties:null)
INFO : Completed compiling command(queryId=hive_20190706211758_5224694a-6dd1-4c7f-912a-ff1d920f1ea4); Time taken: 0.332 seconds
INFO : Executing command(queryId=hive_20190706211758_5224694a-6dd1-4c7f-912a-ff1d920f1ea4): insert into table irisdata values (5.1,3.5,1.4,0.2,"Iris-setosa")
INFO : Query ID = hive_20190706211758_5224694a-6dd1-4c7f-912a-ff1d920f1ea4
INFO : Total jobs = 1
INFO : Launching Job 1 out of 1
INFO : Starting task [Stage-1:MAPRED] in serial mode
INFO : Subscribed to counters: [] for queryId: hive_20190706211758_5224694a-6dd1-4c7f-912a-ff1d920f1ea4
INFO : Tez session hasn't been created yet. Opening session
INFO : Dag name: insert into table iri...4,0.2,"Iris-setosa") (Stage-1)
INFO : Status: Running (Executing on YARN cluster with App id application_1562401169829_0009)
----------------------------------------------------------------------------------------------
VERTICES MODE STATUS TOTAL COMPLETED RUNNING PENDING FAILED KILLED
----------------------------------------------------------------------------------------------
Map 1 .......... container SUCCEEDED 1 1 0 0 0 0
Reducer 2 ...... container SUCCEEDED 1 1 0 0 0 0
----------------------------------------------------------------------------------------------
VERTICES: 02/02 [==========================>>] 100% ELAPSED TIME: 7.79 s
----------------------------------------------------------------------------------------------
INFO : Status: DAG finished successfully in 6.84 seconds
INFO :
INFO : Query Execution Summary
INFO : ----------------------------------------------------------------------------------------------
INFO : OPERATION DURATION
INFO : ----------------------------------------------------------------------------------------------
INFO : Compile Query 0.33s
INFO : Prepare Plan 4.08s
INFO : Get Query Coordinator (AM) 0.00s
INFO : Submit Plan 0.45s
INFO : Start DAG 0.68s
INFO : Run DAG 6.84s
INFO : ----------------------------------------------------------------------------------------------
INFO :
INFO : Task Execution Summary
INFO : ----------------------------------------------------------------------------------------------
INFO : VERTICES DURATION(ms) CPU_TIME(ms) GC_TIME(ms) INPUT_RECORDS OUTPUT_RECORDS
INFO : ----------------------------------------------------------------------------------------------
INFO : Map 1 3680.00 3,740 136 3 1
INFO : Reducer 2 612.00 590 0 1 0
INFO : ----------------------------------------------------------------------------------------------
...省略...
それではデータを見てみます。
select * from irisdata;
+------------------------+-----------------------+------------------------+-----------------------+-----------------+
| irisdata.sepal_length | irisdata.sepal_width | irisdata.petal_length | irisdata.petal_width | irisdata.class |
+------------------------+-----------------------+------------------------+-----------------------+-----------------+
| 5.1 | 3.5 | 1.4 | 0.2 | Iris-setosa |
+------------------------+-----------------------+------------------------+-----------------------+-----------------+
1 row selected (0.296 seconds)
では実際に、ファイルからテーブル作成をしていきます。
locationで指定したファイルの形式を適応させることができます。
(これを付けないと、load の部分が通りません。)
0: jdbc:hive2://localhost:10000> create table irisdata_from_file (
sepal_length float,
sepal_width float,
petal_length float,
petal_width float,
class string
)
row format delimited
fields terminated by ','
lines terminated by '\n'
stored as textfile
location '/user/hive/iris.data';
0: jdbc:hive2://localhost:10000> show tables;
+---------------------+
| tab_name |
+---------------------+
| irisdata |
| irisdata_from_file |
+---------------------+
0: jdbc:hive2://localhost:10000> load data inpath '/user/hive/iris/iris.data' into table irisdata_from_file;
中のデータを見てみます。
0: jdbc:hive2://localhost:10000> select * from irisdata_from_file where petal_width = 0.2;
+----------------------------------+---------------------------------+----------------------------------+---------------------------------+---------------------------+
| irisdata_from_file.sepal_length | irisdata_from_file.sepal_width | irisdata_from_file.petal_length | irisdata_from_file.petal_width | irisdata_from_file.class |
+----------------------------------+---------------------------------+----------------------------------+---------------------------------+---------------------------+
| 5.1 | 3.5 | 1.4 | 0.2 | Iris-setosa |
| 4.9 | 3.0 | 1.4 | 0.2 | Iris-setosa |
| 4.7 | 3.2 | 1.3 | 0.2 | Iris-setosa |
| 4.6 | 3.1 | 1.5 | 0.2 | Iris-setosa |
| 5.0 | 3.6 | 1.4 | 0.2 | Iris-setosa |
| 5.0 | 3.4 | 1.5 | 0.2 | Iris-setosa |
| 4.4 | 2.9 | 1.4 | 0.2 | Iris-setosa |
| 5.4 | 3.7 | 1.5 | 0.2 | Iris-setosa |
| 4.8 | 3.4 | 1.6 | 0.2 | Iris-setosa |
| 5.8 | 4.0 | 1.2 | 0.2 | Iris-setosa |
| 5.4 | 3.4 | 1.7 | 0.2 | Iris-setosa |
| 4.6 | 3.6 | 1.0 | 0.2 | Iris-setosa |
| 4.8 | 3.4 | 1.9 | 0.2 | Iris-setosa |
| 5.0 | 3.0 | 1.6 | 0.2 | Iris-setosa |
| 5.2 | 3.5 | 1.5 | 0.2 | Iris-setosa |
| 5.2 | 3.4 | 1.4 | 0.2 | Iris-setosa |
| 4.7 | 3.2 | 1.6 | 0.2 | Iris-setosa |
| 4.8 | 3.1 | 1.6 | 0.2 | Iris-setosa |
| 5.5 | 4.2 | 1.4 | 0.2 | Iris-setosa |
| 5.0 | 3.2 | 1.2 | 0.2 | Iris-setosa |
| 5.5 | 3.5 | 1.3 | 0.2 | Iris-setosa |
| 4.4 | 3.0 | 1.3 | 0.2 | Iris-setosa |
| 5.1 | 3.4 | 1.5 | 0.2 | Iris-setosa |
| 4.4 | 3.2 | 1.3 | 0.2 | Iris-setosa |
| 5.1 | 3.8 | 1.6 | 0.2 | Iris-setosa |
| 4.6 | 3.2 | 1.4 | 0.2 | Iris-setosa |
| 5.3 | 3.7 | 1.5 | 0.2 | Iris-setosa |
| 5.0 | 3.3 | 1.4 | 0.2 | Iris-setosa |
+----------------------------------+---------------------------------+----------------------------------+---------------------------------+---------------------------+
28 rows selected (0.521 seconds)
Zeppelinでのデータ操作
準備
zeppelinを開きます。
http://localhost:9995/
(こちらは、自分の環境に合わせてアクセスをお願いします。)
次に、ユーザのところをクリックし、Interpreterを選択します。
jdbcの箇所でeditを選択します。
以下を設定しましょう。
default.driver : org.apache.hive.jdbc.HiveDriver
default.user : hiveUser
default.password : hivePassword
default.url : jdbc:hive2://localhost:10000
そしたら、Saveしてください。
noteの作成
Create new noteを選択します。
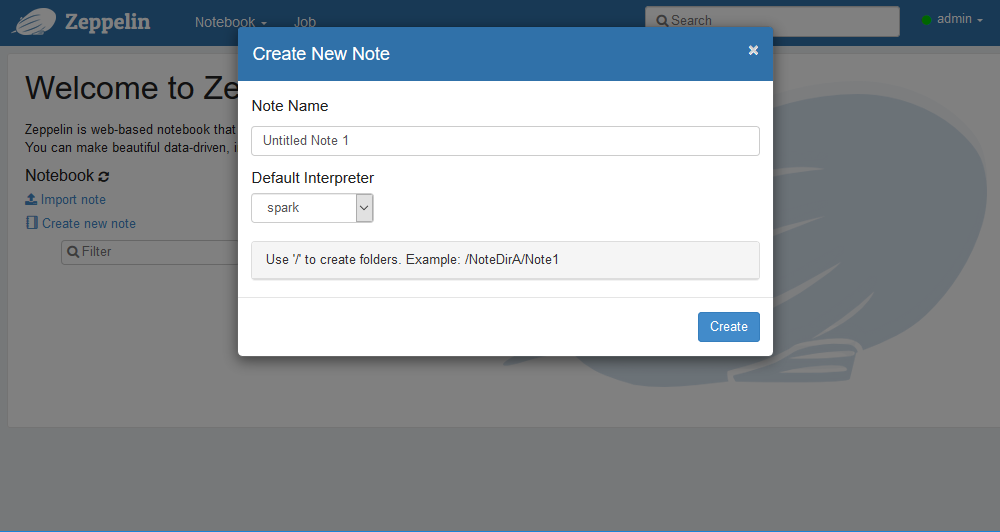
・Name:今回のnoteの名前
・Default Interpreter:どの言語を用いるかを設定します。
ex) spark, angular, jdbc, livy, md, sh
今回はDefault Interprinterをjdbcに設定します。
Hiveに入っているデータを操作する。
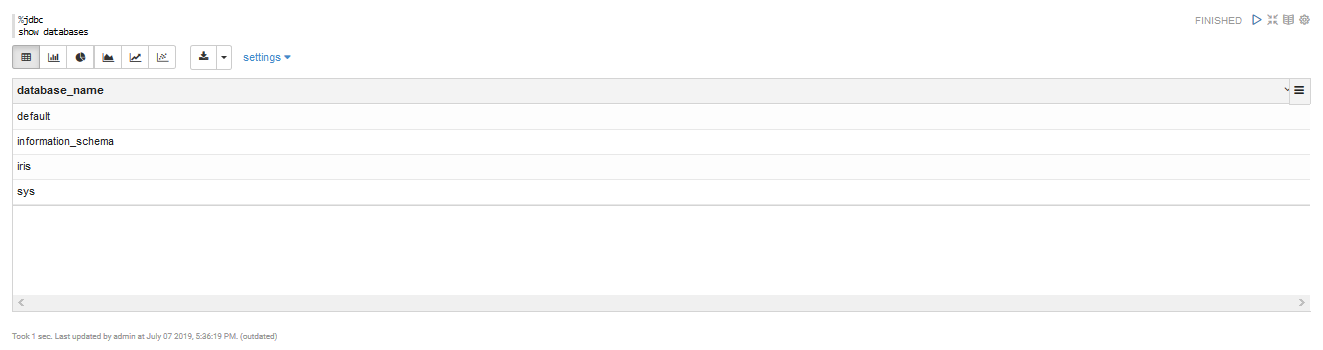
以下のように記入して「Shift + Enter」を押します。
%jdbc
show databases;
結果は、Hive上の時と同じものが表示されました。
次は、databaseにアクセスします。
%jdbc
use iris
「Shift + Enter]
%jdbc
show tables
順調ですね。
では、実際にデータを取得してみましょう。
%jdbc
select * from irisdata_from_file
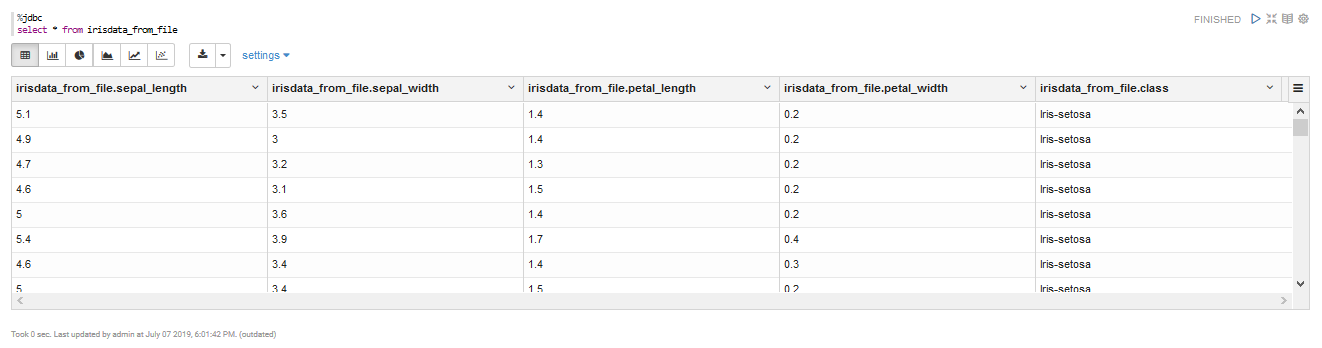
ここから、Zepplinを使う事の意味を感じられる部分を見ていきます。
%jdbc
select * from irisdata_from_file where class='Iris-setosa'
Queryの真下で表示をTableからBar Chartに変えてみましょう。
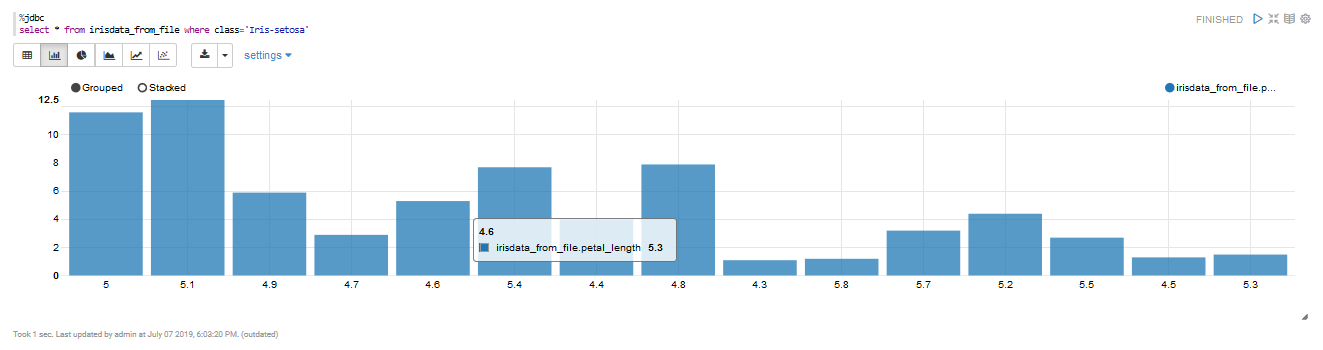
こういったものを、Zepplinでは、pythonで言うmatplotlib等を使わずに見ることができます。
%jdbc
select * from irisdata_from_file where class is not null
settingというところを開いてみましょう。
ここでは、keysがx座標, valuesがy座標を表します。
以下のように設定してみましょう。(drug and dropで移動できます)
keys :
irisdata_from_file.class
value:
- irisdata_from_file.sepal_length
- irisdata_from_file.sepal_width
- irisdata_from_file.pepal_length
- irisdata_from_file.pepal_width
valueに関して、上にカーソルを持っていき選択すると
「sum, count, avg, min, max」が選べるので、今回はmaxを選択してみましょう。
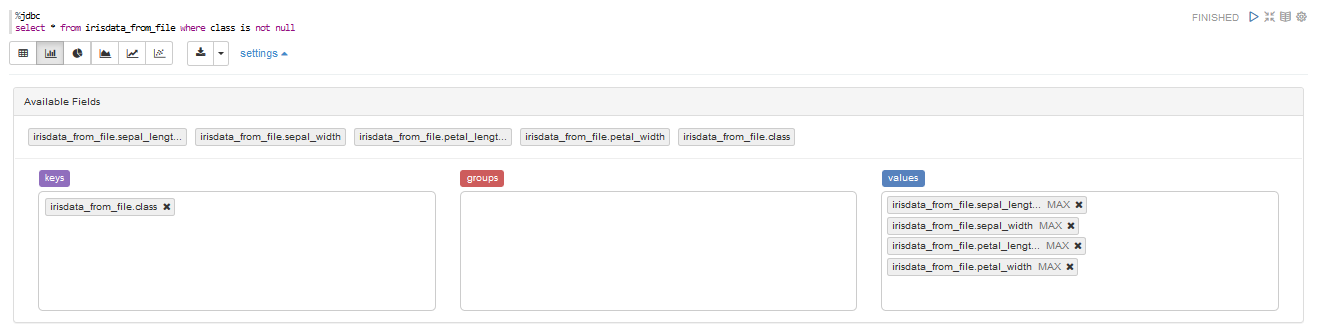
Bar chartを選択して結果を見てみましょう。
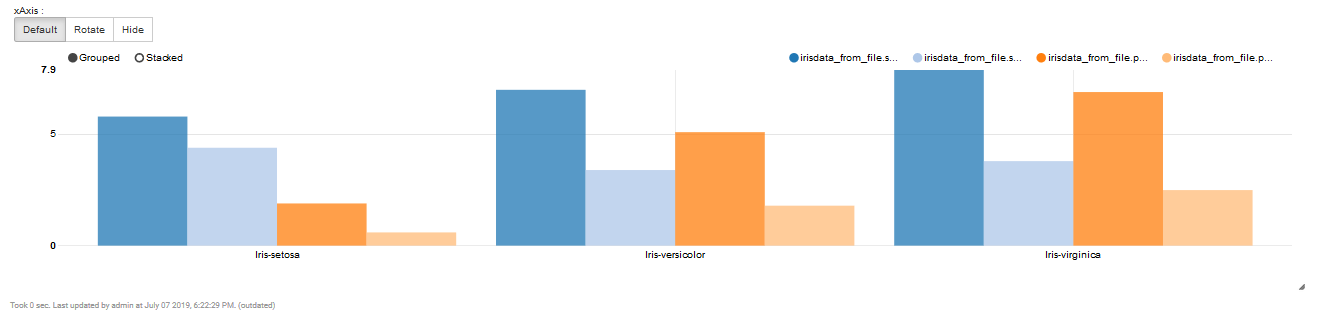
とても、データ分析らしくなってきましたね。
終わり
今、流行りに流行っているKaggle等で、テーブルコンペなどがあった際に使ってみるのも面白そうだなって思いました。
ambariのインストール方法とかも、ご要望をいただければ載せていこうかなと思います。