今回は分類器のお話ですね。
前回分はこちら↓↓
http://qiita.com/ru_pe129/items/207a09b5d20a125033f4
2.3 Classification
分類器は要素の特徴とラベルの関連付けを行うものである。分類器には多くの種類があるが、一般的には教師なし分類(unsupervised)と教師あり分類(supervised)に分けることができる。教師なし分類では事前にラベルが分かっているデータが与えられない分類方法である。教師あり分類では事前に特徴とラベルの訓練データが与えられており、訓練データを利用して分類器を作成する。本節ではいくつかの分類アルゴリズムを紹介する。
2.3.1 Nearest Neighbors
Instance-based 分類器は訓練データを用いて道データのラベルを推測する分類器である(例:rote-learner)。もっともよく使われるInstance-based分類器は Nearest neighbor classifir(kNN、最近傍分類器) である。以下にkNNのイメージ図を示す。
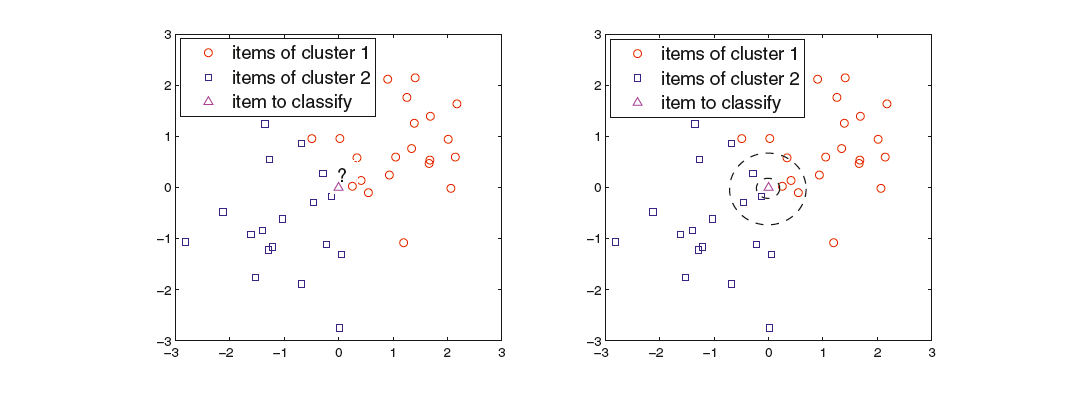
kNNは、与えられた点にもっとも近いk個の点を訓練集合から選択し、もっとも点の数の多いラベルと同じラベルが与えられた点にも与えられる。つまり、近くの点のラベルで多数決を行うわけである。kNNで問題となるのはkの選び方である。kが小さすぎるとノイズに弱くなってしまうが、kが大きすぎると関係のないラベルを多く含んでしまい、シャープに分類することができなくなる。
kNNは数値的なモデルを作らないlazy learnerであり、機械学習におけるもっとも単純な手法となっている。なぜlazyなのかと言えば、モデルを作成しないせいでデータごとに計算処理をすべて行わなければならないからである。したがって、未知のデータを分類する際のコストは高い。kNNとは反対に決定木はeager learnerと呼ばれる。決定木はルールが決まってしまえば条件をもとに判断するだけでよく、毎回大量の計算をしなくて済む。
kNNは協調フィルタリングのコンセプトに近い手法であり、協調フィルタリングにおけるもっとも一般的な手法である。lazy learnerであるがゆえにデータが追加されたときにモデルを再計算する必要がないのもkNNを用いるメリットである。一方で、近傍点の再計算にはコストがかかるため、選択母数を減らす必要がある。
いくつかの欠点はあるものの、kNNは精度が高く、協調フィルタリングにおけるデファクトスタンダードとなっているのもまた事実である。
2.3.2 Decision Trees
Decision Trees(決定木) は分類対象の属性を木構造で表現する分類器である。ノードはdecision nodesと呼ばれ、下の階層のどの気に振り分けるか決定する。葉は対象の属性の値を示す。Decision Treeでは、ルールの生成コストが小さく、未知のデータの分類も高速で行えるという利点がある。また、他の分類器に比べて分類ルールを解釈しやすいというメリットもある。
Decision Treeはモデルベース型のRSであり、アイテムが持つ特徴量を用いて決定木(モデル)を構成する。ここで、Decision Treeによって得られるprecisionは平均的なスコアよりも小さくなることに注意しなければならない。また、全分類対象をDecision Treeで分類することも非常に難しいということも忘れてはならない。
2.3.3 Rule-based Classifiers
Rule-based classfiers は「もし~なら・・・」という条件を使ってデータを分類する分類器である。このタイプの分類器を生成するためにはデータから直接データを取り出す方法があり、RIPPERやCN2が例として挙げられる。しかし、Decision TreeやNeural Networkなどの他の手法を用いて間接的にルールを取得する方法が一般的である。Rule-based分類器を用いると、分類器が非常に解釈しやすいというメリットがある。しかし、RSにはあまり使われない手法である。なぜなら、Decision Treeの時と同様にルールで全アイテムを扱うことは難しいからである。また、条件を用いるということは推薦対象のドメインに関する知識を用いる必要があるからである。ただし、ドメイン知識を適切にもちいることでRSのパフォーマンスが向上する場合もある。
2.3.4 Bayesian Classifiers
Bayesian分類器 は確率を用いて分類問題を解くための枠組みで、条件付確率とベイズの定理をもとに作られている。Bayesian分類器の中でも最も有名なのがナイーブベイズ分類器である。ナイーブベイズはノイズに強いという特徴があるが、計算に用いる各確率の独立仮定が成り立たない場合もある。その場合はBBN(Bayesian Belief Networks)という手法を用いればよい(詳細は省略)
Bayesian分類器はモデルベースのRSにおいては人気な手法であり、内容ベースのRSでモデルを抽出するために用いられる。
2.3.5 Artificial Neural Networks
Artificial Neural Networks(ANN) は結合されたノードの組み合わせであり、リンクには重みが付けられている、ANNは脳の構造にインスパイアされて考え出された手法である。各ノードは生物学上のニューロンの類推としてニューロンと呼ばれている。 シンプルな構成ではあるが、十分な教師データを与えることで分類問題を解決するための学習を行うことができる。
以下の図はANNのもっともシンプルな形であるパーセプトロンの構造を示す。
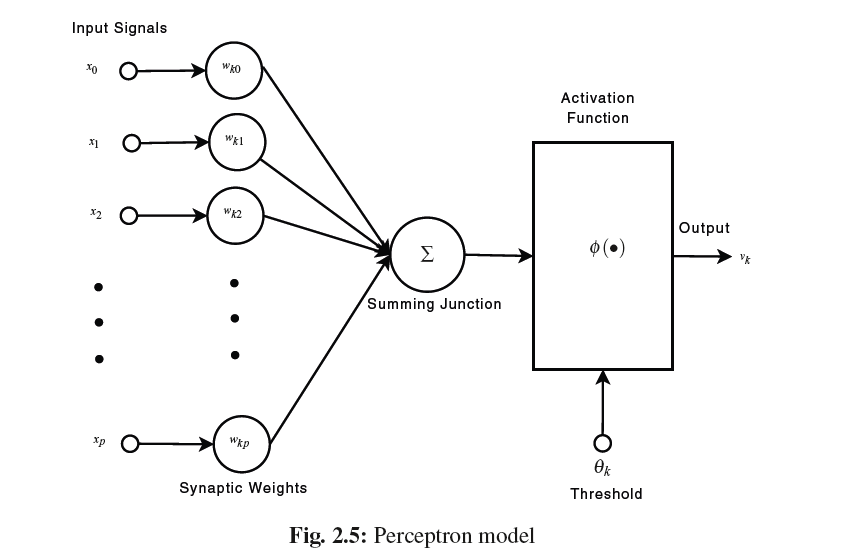
図中のactivation functionをしきい値関数であるとみなした場合、各入力とそのリンクの重みを掛け合わせたものの和がしきい値を超えるかどうかによって出力を変化させる。出力はoutput functionによって以下の式であらわされる。
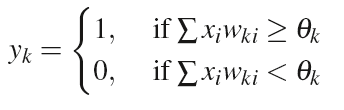
しきい値関数以外にも、シグモイド関数やアークタンジェント、ステップ関数などがactivation functionとして用いられる。
ANNは複数のレイヤーから構成され、3つのタイプに分けることができる。入力層、隠れ層、出力層である。入力層は入力データを受け取り、隠れ層に重みづけした出力を送る。出力層は隠れ層から受け取った重み付き出力を受け取って最終的な出力を行う。データの伝搬方法にはいくつかの手法が存在するが、もっとも一般的に使われているのはフィードフォワードANN、つまりデータの伝搬方向が入力層→隠れ層→出力層の一方向となっているものである。
ANNを用いる利点としては、activation functionに非線形関数を用いることで非線形の分類問題を扱うことができる点があげられる。複数のノードが並行して処理を行っていることによって、効率的かつ一部のネットワークが処理に失敗してもうまく処理を行えることも利点の一つ手である。一方で適切な形態を考案することが難しいという問題点がある(ノードや層の数)。また、ANNは意味的な解釈を与えず、ブラックボックスとして機能するため、分類方法に意味的な解釈を与えない。
ANNもBayesian分類器のようにモデルベースのRSで利用することができるが、他の分類器を用いた場合と比べてパフォーマンスが上がったという報告は見られない。実際、決定木、Bayesian分類器、ANNを用いた実験では、決定木の結果が非常に悪い結果となり、その他二つは似通った結果になったという。この実験ではANNのような非線形分類問題に対応した分類器を用いる必要はないだろうという結論となった。
ANNは複数の情報源や推薦モジュールからのデータを統合する手段としても使うことができる。たとえばテレビ番組の推薦を行う際にユーザーのプロフィールやユーザーが所属するコミュニティ、番組のメタデータなどの複数の情報を用いる場合にANNは有効である。
2.3.6 Support Vector Machines
Support Vector Machines(SVM) は、マージンを最大化するような線形超平面を見つけることによって分類を行う分類器である。以下の図のような2次元の平面で二つのクラスに分類することを考えてみよう。
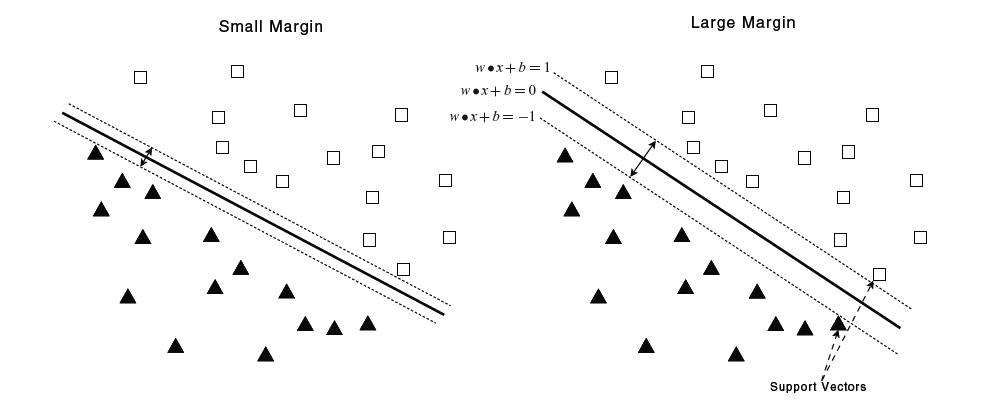
左の図は右の図に比べるとマージンが小さいことが分かる。(マージンを大きくとることによって分類に誤りが少なくなってよりはっきり分類できるというイメージだろうか?)
以下の式は+1のクラスと-1のクラスの2クラスに分類する場合の分類関数とマージンの定義式である。
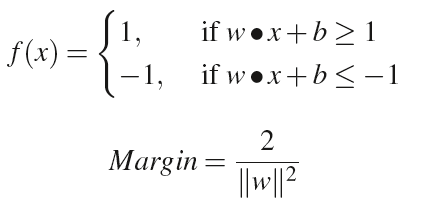
なお、マージンを最大化することは以下の式を最小化することと同じである。
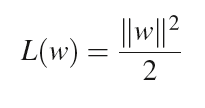
分類対象が線形分類できない場合はマージンにゆとり(ε)を持たせることである程度対応可能である。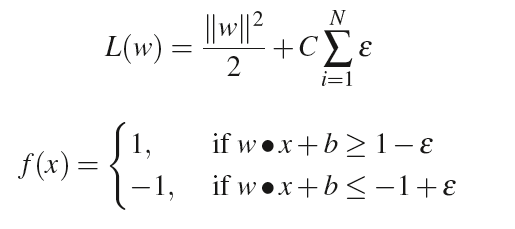
SVMは精度と効率の良さから近年では人気のある手法となっている。
全体的に説明を省略してしまったので、すでに機械学習について知っている人しか分からないような文章になってしまったかもしれません…