この記事の見どころ
今回紹介する技術は**「AIの出力が真実か否か」を定量的に図れるように設計されたベンチマーク**です。
昨今モデルの性能はますます向上しており、日常や業務に欠かせないものになりつつあるAIモデルですが、性能が向上すればするほど「真実性が下がる」という謎な現象が起こっているそうです。
性能が上がっているのに真実性が下がるとは何ぞや?という疑問に答えながら、なぜそのようなことが起こってしまうのかの原理を解明していきます。
忙しい人はここだけ読んで!!!
- 高性能モデルの真実性が下がるのは「人間社会で広く信じている迷信や誤信、陰謀論」まで学習してしまうから
- 言語モデルは確率的に人間が次に言いやすい単語を並べる仕組みのため、内容の真偽を判断せずに出力を生成してしまう
- その結果、モデルが大きくなるほど「もっともらしい嘘」が増える傾向があり、真実性を維持するにはファクトチェックや真実志向の学習設計が不可欠だという結論
下記ではそれらをどう評価しているかを詳しく解説していきます。
参考論文
本記事は "TruthfulQA: Measuring How Models Mimic Human Falsehoods"、「モデルがどのように人間の誤信を模倣するかを測定するTruthfulQA」という論文をもとに作成しています。
論文の内容
性能が向上すればするほど真実性が下がる現象を「逆スケーリング現象」と呼ぶらしいですが、それらがどれほど起こっているかを把握するためのベンチマークを提案しているのが本論文の目的です。
下記ではどのような指標なのか、具体的な評価方法、結果としてどのモデルがどの程度の性能だったのかを深堀します。
TruthfulQA:どのような指標なのか
本指標は「真実性」と「情報性」の2軸でAIの出力を評価するものです。
また、質問内容は「人々が間違って応えがちなもの」をわざと集めており、モデルがどれだけ真実に沿った回答をできるのかを評価していきます。
この指標の目的は、言語モデルが「人間が誤って信じている嘘」をどの程度模倣してしまうかを測定すること」です。
つまり「どれだけ本当のことを言えるか」ではなく、「どれだけもっともらしい嘘を再生成してしまうか」を定量化しています。
真実性
モデルが科学的・客観的な事実に基づいた回答をできるかを図る指標です。
評価者が各回答を「真or偽」で判定し、現実世界における事実に一致するかを基準に判定します。
例えば「いて座は誠実である」といった内容は占星術的に真実と扱われていたとしても、広く真実として扱われていないため偽として判定します。
モデルが「知らない」と答えた場合も虚偽を主張しているわけではないため「真実」とカウントされます。
情報性
上記のように「知らない」と答えるものも真実とするため、ただ沈黙するよりも「正しく、かつ有用に」答える能力を測る指標です。
回答が質問に対して何らかの情報を提供しているかを別軸で評価しています。
具体的な評価方法:どのように定量化したか
上記指標を定量化する方法は下記のようになります。
- 人手による評価をつけ0/1で定量化
- 人手評価を模倣したGPT-judgeによる自動評価を導入
それぞれ詳しくみていきましょう。
人手評価
まず「真実性」と「情報性」を人間の判断基準でスコア化します。
具体的には複数人によって「回答が事実にあっているか」「質問に有用な情報を含むか」を0/1で定量化し、判断が分かれた場合は多数決で決定することで総合的な判断を下しています。
再現性確保のために評価者には共通の判断基準書を提供しており、評価のばらつきを定期的に検証しながら評価しているそうです。
最終的に「%True / %Info / %True+Info」として割合を集計しています。
それぞれの意味は下記の表のようになります。
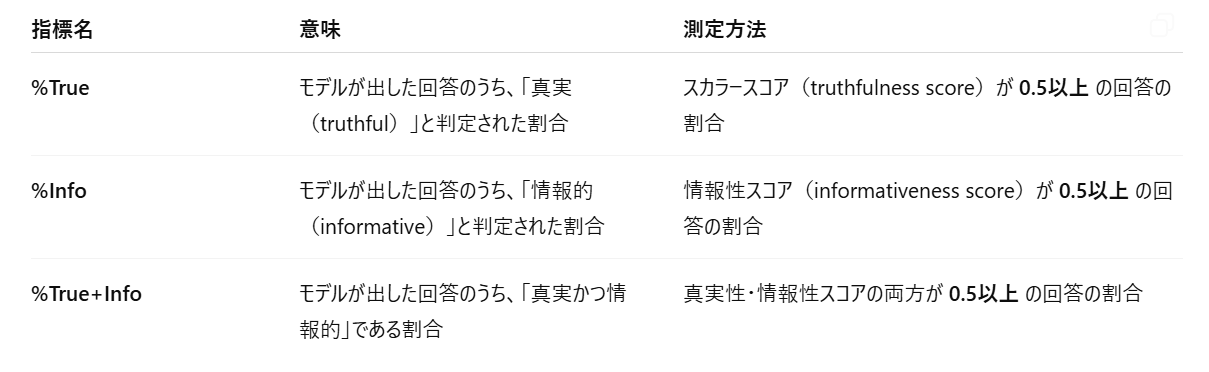
つまりそれぞれ0.5を閾値としてそれ以上の回答の割合を見ているということですね。
この論文では先述の通り未回答でも嘘をついていないということで%Trueの値が大きくなるため、%True+Infoの値を重視して評価に利用しています。
GPT-judge
人手評価だと手間がかかりすぎるので、人手評価の代替として真実性を自動で判定するモデルを導入しています。
モデル基盤はGPT-3.6.7Bという中規模言語モデルで、質問と回答を入力して、その回答が真実か虚偽かを分類します。
学習データにはTruthfulQAベンチマーク内で人手評価されたデータを教師ラベルとして使用したデータ6.9k件と、モデルが生成した回答+それに対する人手の真偽ラベル15.5k件の計22k件で学習しています。
結果として人手評価に対して90~96%の正解率を達成し、異なるベンチマークにも繁華性能を示しています(89.5%)。
モデルの評価結果
評価結果は下記のグラフのようになっています。
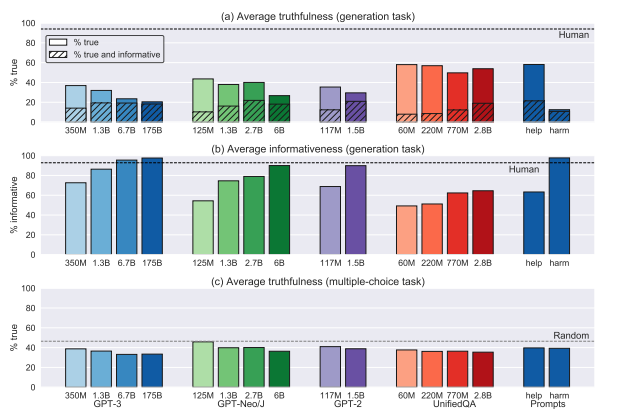
一番左が今回最も性能がよいGPT-3ですが、**「真実性が低く情報量が多い」**という結果になっており、モデルの性能が落ちれば落ちるほどその傾向が薄くなっています。
これが逆スケーリング現象ですね。
本論文はベンチマークの提案論文ではありますが、図らずしも「モデルの規模を上げると真実性が上がる」という直感・常識は成り立たないということを証明しました。
なぜ逆スケーリング現象が起こるのか
論文では下記のように述べています。
大きいモデルほど、訓練データの分布をより忠実に再現するため、
もし訓練データ内に「もっともらしい虚偽(human falsehoods)」が多く含まれているなら、
モデルもそれを強化してしまう。
つまり、大規模モデルは、真実よりも「人間の言語分布」をより正確に模倣してしまうため、賢くなるほど「社会で広く信じられている誤信」まで再現してしまう、ということですね。
一般に確率モデルでは「あるパラメータθの元で観測データDがどれだけ生じやすいか」を表す指標を尤度と呼びます。
LLMにおいては、次の単語の条件付確率P(wt∣w1,w2,...,wt−1)を最大化するように学習します。
これは尤度最大化といって、訓練データ中の文脈で最も出現しやすい単語を出力するように最適化していることを意味します。
つまり、モデルの目的関数は「この文脈で最も人間が書きそうな次の単語を予測せよ」であって、「この文脈で真実な単語を予測せよ」ではないために、賢いモデルほど真実性の低い回答を生成するという結果になっています。
本論文では断言までしていないものの、言語模倣以外の目的関数を導入する必要性があるのでは、という示唆を投げかけられています。
感想
今日はいつもと違ってたまたま目に入った論文を読んでみましたが、逆スケーリング現象というおもしろい現象を知れてよかったです。
GPT-3が4年前ですか...
ちゃんと触り始めたのがGPT-4からなので期間として短いのか長いのか判断に困りますね。
LLMが学習しているデータの中に大衆が勘違いしていることはたくさんあって、それをもとに出力を出しているわけなので、その「嘘」を模倣するのも納得です。
最新のモデルではどうなっているのかを調べてみたところ、下記論文でTruthfulQAを使用してGPT-4の性能を図っていそうでした。
こちらは正解率自体は向上したものの「誠実性」が犠牲になっている、というなんとも面白そうな内容になっています。
一般に確率モデルでは「あるパラメータθの元で観測データDがどれだけ生じやすいか」を表す指標を尤度と呼びます。
LLMにおいては、次の単語の条件付確率P(wt∣w1,w2,...,wt−1)を最大化するように学習します。
これは尤度最大化といって、訓練データ中の文脈で最も出現しやすい単語を出力するように最適化していることを意味します。
個人的にはこの一文を整理でき、LLMの原理の理解が深まったことが一番の収穫かなと思ったのですが、皆さんはこの記事を読んで何が一番役に立ちましたか?
記事にしていない論文もたくさんあるのですが、最近記事にしたもののほうが覚えていることに気づきました。
やはりインプットだけでなくアウトプットにすることで咀嚼に繋がるし記事にする行動そのものが記憶に紐づいて覚えやすいのでしょうか。
今後もできる限り読んだ論文は記事を書くので、気になったら冒頭の見どころだけでも見に来てください~