はじめに
white, inc の ソフトウェアエンジニア r2en です。
自社では新規事業を中心としたコンサルタント業務を行なっており、
普段エンジニアは、新規事業を開発する無料のクラウド型ツール を開発したり、
新規事業のコンサルティングからPoC開発まで携わります

今回は、機械学習の技術調査を行なったので記事で共有させていただきます
以下から文章が長くなりますので、口語で記述させていただきます
Optunaでのパラメータ探索等など、機械学習をしているとき良いモデルを保存していつでも使えるようにしたいと思ったので、Google Cloud Storageに保存して、いつでも読み込みと書き込みができるようなクラスを作成した。
また、Google Cloud StorageからBigQueryにアップロードするときに、CSV形式だと失敗することとかが多いため、pandasのDataFrameをGoogle Cloud Storage保存時にndjson形式に保存できるようにした。
環境
macOS Mojava ver 10.14.6
pyenv, pipenv, python ver. 3.6.8
ローカル設定
忘れてしまって申し訳ないんですが、多分、gcloudの設定をPCにしておく必要性があった気がする...
$ curl https://sdk.cloud.google.com | bash
$ pipenv install gcloud
今回使うライブラリをインストール
$ pipenv install --upgrade google-cloud-storage, google-auth
GCP設定
サービスアカウントの設定
IAMと管理のサービスアカウントから、サービスアカウントを作成する
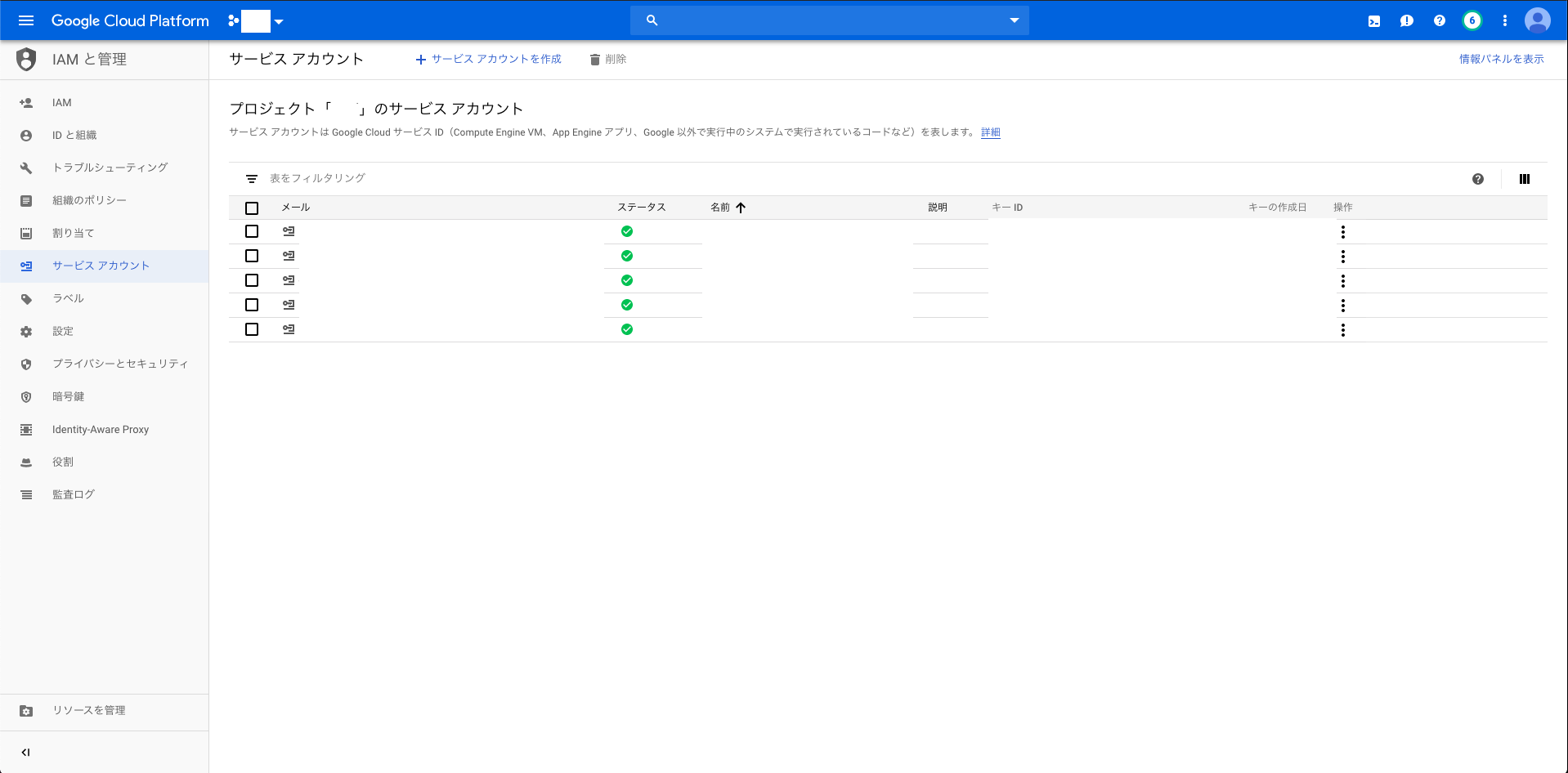
クレデンシャル情報の取得
Cloud APIを使用する(ローカルからGCPを操作する)場合、サービスを使うための認証情報が必要になるので取得する
Google Cloud Document 認証
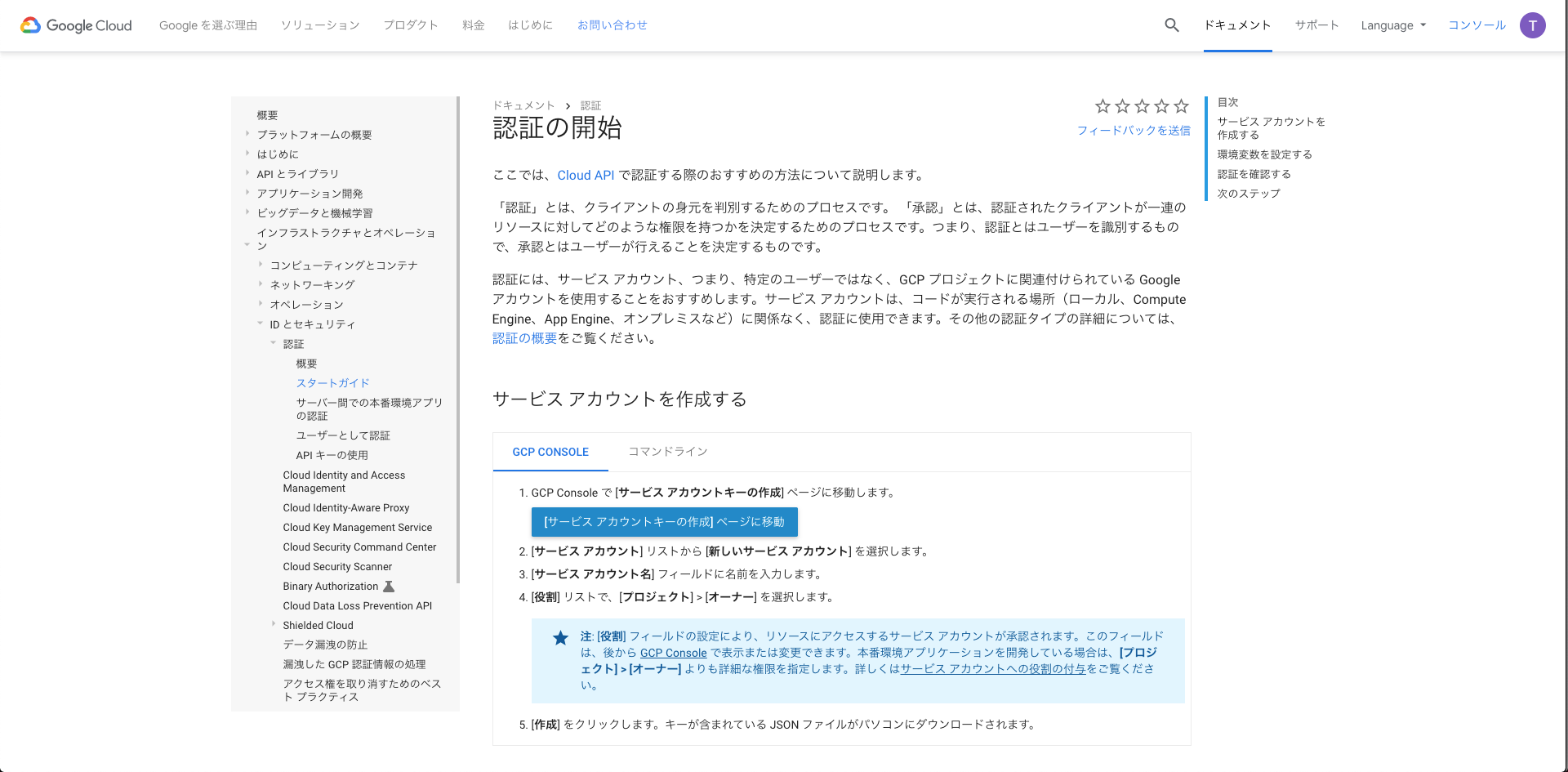
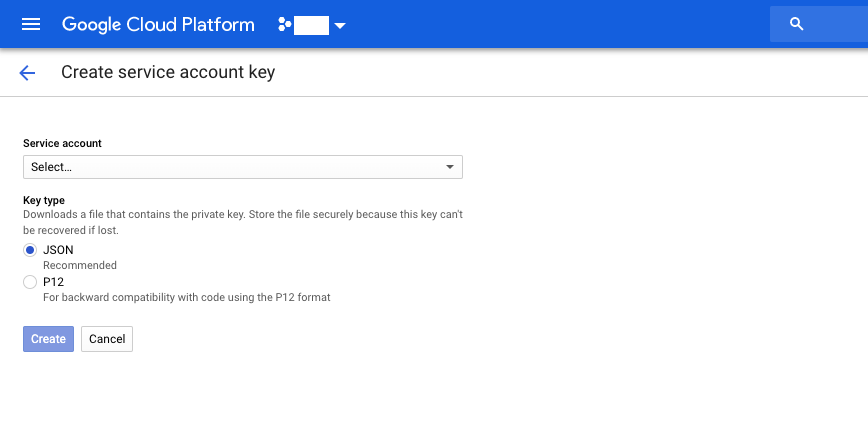
1. ServiceAccountを入力し、keyタイプをJSONに選択する。
2. Createボタンを押すとダウンロード画面に行くため、下記フォルダ構成のようにjsonファイルを配置する
Create Service account key
フォルダ構成
├── main.py <- 実行するファイル
├── utils
├── operation_cloud_storage.py <- GCS操作に関するクラス
└── credential-344323q5e32.json <- クレデンシャル情報
ソースコード
import io
import os
import pickle
import pandas
import google.auth
from pathlib import Path
from google.cloud import storage
from google.oauth2 import service_account
from typing import List, Set, Dict, Tuple, TypeVar
class GoogleCloudStorage():
'''
Google Cloud Storage操作に関するクラス
Google Cloud StorageのデータをダウンロードしてPythonのデータ型に変換する
Pythonのデータ型をアップロードしてGoogle Cloud Storageのデータに変換する
'''
def __init__(self, parameter: Dict) -> None:
'''
リモートのサーバ上で動作保証するため下記四種の方法で認証を通している
'''
self.project_name = parameter['project']
self.bucket_name = parameter['bucket']
self.file_name = parameter['folder']
self.mime_type = parameter['mime_type']
self.credential_path = parameter['credential_path']
try:
os.environ["GOOGLE_APPLICATION_CREDENTIALS"] = str((Path(Path.cwd()).parent)/parameter["credential_path"])
self.credentials = str((Path(Path.cwd()).parent)/parameter["credential_path"])
self.client = storage.Client(self.project_name).from_service_account_json(self.credentials)
except Exception as e:
print(e)
try:
self.credentials, _ = google.auth.default()
self.client = storage.Client(project=self.project_name, credentials=self.credentials)
except Exception as e:
print(e)
try:
os.environ["GOOGLE_APPLICATION_CREDENTIALS"] = str((Path(Path.cwd()).parent)/parameter["credential_path"])
self.credentials, _ = google.auth.default()
if self.credentials.requires_scopes:
self.credentials = self.credentials.with_scopes(['https://www.googleapis.com/auth/devstorage.read_write'])
self.client = storage.Client(credentials=self.credentials)
except Exception as e:
print(e)
try:
credentials_path = str((Path(Path.cwd()).parent)/parameter["credential_path"])
self.credentials = service_account.Credentials.from_service_account_file(credentials_path)
if self.credentials.requires_scopes:
self.credentials = self.credentials.with_scopes(['https://www.googleapis.com/auth/devstorage.read_write'])
self.client = storage.Client(credentials=self.credentials)
except Exception as e:
print(e)
def download_as_string(self) -> str:
bucket = self.client.get_bucket(self.bucket_name)
blob = storage.Blob(self.file_name, bucket)
return blob.download_as_string()
def download_as_pickle(self) -> str:
bucket = self.client.get_bucket(self.bucket_name)
blob = storage.Blob(self.file_name, bucket)
return pickle.loads(blob.download_as_string())
def download_to_file(self, file_obj) -> object:
bucket = self.client.get_bucket(self.bucket_name)
blob = storage.Blob(self.file_name, bucket)
return blob.download_to_file(file_obj)
def upload_from_string(self, context: str) -> None:
bucket = self.client.get_bucket(self.bucket_name)
blob = storage.Blob(self.file_name, bucket)
blob.upload_from_string(context, content_type=self.mime_type)
def upload_from_ndjson(self, dataframe: pandas.core.frame.DataFrame) -> None:
'''
GCSからBigQueryにあげるときにndjson形式だとエラーが発生しにくい為、
pandas.DataFrameをndjson形式で保存できるようにしている
'''
buffer = io.StringIO()
dataframe.to_json(buffer, orient="records", lines=True, force_ascii=False)
bucket = self.client.get_bucket(self.bucket_name)
blob = storage.Blob(self.file_name, bucket)
blob.upload_from_string(buffer.getvalue(), content_type=self.mime_type)
def upload_from_file(self, file_obj) -> None:
bucket = self.client.get_bucket(self.bucket_name)
blob = storage.Blob(self.file_name, bucket)
blob.upload_from_file(file_obj)
{
"type": "service_account",
"project_id": "project-291031",
"private_key_id": "464564c7f86786afsa453345dsf234vr32",
"private_key": "-----BEGIN PRIVATE KEY-----\ndD\n-----END PRIVATE KEY-----\n",
"client_email": "my-email-address@project-291031.iam.gserviceaccount.com",
"client_id": "543423423542344334",
"auth_uri": "https://accounts.google.com/o/oauth2/auth",
"token_uri": "https://oauth2.googleapis.com/token",
"auth_provider_x509_cert_url": "https://www.googleapis.com/oauth2/v1/certs",
"client_x509_cert_url": "https://www.googleapis.com/robot/v1/metadata/d453/my-email-address@project-291031.iam.gserviceaccount.com"
}
lightgbmモデルのクラス
import copy
import pandas
import lightgbm
from typing import List, Set, Dict, Tuple, TypeVar
class light_gradient_boosting_tree():
'''
https://lightgbm.readthedocs.io/en/latest/
決定木アルゴリズムに基づいた勾配ブースティング(Gradient Boosting)の機械学習フレームワーク
'''
def __init__(self):
pass
def insert_parameter(self, parameter: Dict[str, str]):
'''
機械学習のパラメータをセット
'''
self.params = parameter
def fit(self, X_train: pandas.core.frame.DataFrame, X_valid: pandas.core.frame.DataFrame, y_train: pandas.core.series.Series, y_valid: pandas.core.series.Series = None) -> None:
'''
データを学習
特徴量重要度をローカルのフォルダに保存する
'''
train_data = lightgbm.Dataset(X_train, label=y_train)
eval_data = lightgbm.Dataset(X_valid, label=y_valid, reference=train_data)
parameter = copy.deepcopy(self.params)
self.clf = lightgbm.train(parameter, train_data, valid_sets=eval_data)
def predict(self, X_test: pandas.core.series.Series) -> pandas.core.series.Series:
'''
データを予測
'''
return pandas.Series(self.clf.predict(X_test))
データセット
from sklearn.datasets import load_boston
from sklearn.model_selection import train_test_split
def make_dataset() -> Tuple[numpy.ndarray, numpy.ndarray, numpy.ndarray, numpy.ndarray]:
boston = load_boston()
X, y = boston.data, boston.target
X_train, X_valid, y_train, y_valid = train_test_split(X, y)
return X_train, X_valid, y_train, y_valid
lightgbm学習
def fit(X_train: numpy.ndarray, X_valid: numpy.ndarray, y_train: numpy.ndarray, y_valid: numpy.ndarray) -> Callable:
lgb_parameter = {
'boosting_type': 'gbdt',
'objective': 'regression',
'metric': 'l2',
'num_leaves': 31,
'learning_rate': 0.05,
'feature_fraction': 0.9,
'bagging_fraction': 0.8,
'bagging_freq': 5,
'verbose': 0
}
algorithm = light_gradient_boosting_tree()
algorithm.insert_parameter(lgb_parameter)
algorithm.fit(X_train, X_valid, y_train, y_valid)
return algorithm
<class '__main__.light_gradient_boosting_tree'>
機械学習のモデルをGoogle Cloud StorageにPickle形式でアップロードして書き込む
import pickle
import uuid
def write_model(algorithm: Callable) -> str:
upload_clf_parameter = {
"project": "unisys-245106",
"bucket": "performance_database",
"folder": "datalake/models/",
"mime_type": "application/octet-stream",
"credential_path": "recommend/utils/performance-base-5873434c8f27.json"
}
trial_uuid = str(uuid.uuid4())
upload_clf_parameter["folder"] += f'lgb/{trial_uuid}.pkl'
clf = pickle.dumps(algorithm)
GoogleCloudStorage(upload_clf_parameter).upload_from_string(clf)
return f'lgb/{trial_uuid}.pkl'
lgb/930e087e-3c82-4620-9f4a-972b621b0c2c.pkl
学習済みモデルをGoogle Cloud StorageからPickle形式でダウンロードして読み込む
def read_model(model_path: str) -> pandas.core.series.Series:
download_clf_parameter = {
"project": "unisys-245106",
"bucket": "performance_database",
"folder": "datalake/models/",
"mime_type": "application/octet-stream",
"credential_path": "recommend/utils/performance-base-5873434c8f27.json"
}
download_clf_parameter['model_path'] = model_path
download_clf_parameter['folder'] += download_clf_parameter['model_path']
clf = GoogleCloudStorage(download_clf_parameter).download_as_pickle()
return clf.predict(X_valid)
0 23.892873
1 23.247592
2 38.848780
3 19.778641
4 31.075990
実行
def main():
X_train, X_valid, y_train, y_valid = make_dataset()
algorithm = fit(X_train, X_valid, y_train, y_valid)
model_path = write_model(algorithm)
prediction = read_model(model_path)
if __name__ == '__main__':
main()