公式サンプルを読む
サンプルコードを検索してみたら公式サンプルらしきものが出てきた。
https://github.com/nuka137/pytorch-cpp-example/tree/6d82b0240af6cb33af015e30b01ee3f0fc3deec2/resnet/cpp
C++とPythonのサンプルコードがある様だ。ちなみに昭和のおじさんはGithubもGitの仕組みも良く分からない。ソースコードを管理する仕組みと言うのは知っているけど。最近はこういうのも学校で習うのだろうか?
ヘッダを読む
model.hを読んでみる。まず全体。
#pragma once
#include <torch/torch.h>
using namespace torch::nn;
struct ResidualBlockImpl : Module
{
ResidualBlockImpl(int in_channels, int out_channels, int stride=1);
torch::Tensor forward(torch::Tensor input);
private:
Conv2d conv1 = nullptr;
BatchNorm2d bn1 = nullptr;
ReLU relu1 = nullptr;
Conv2d conv2 = nullptr;
BatchNorm2d bn2 = nullptr;
ReLU relu2 = nullptr;
Conv2d conv3 = nullptr;
BatchNorm2d bn3 = nullptr;
Sequential shortcut = nullptr;
ReLU relu3 = nullptr;
int in_channels;
int out_channels;
};
TORCH_MODULE(ResidualBlock);
struct ResNet50Impl : Module
{
ResNet50Impl();
torch::Tensor forward(torch::Tensor input);
private:
Conv2d conv1 = nullptr;
BatchNorm2d bn1 = nullptr;
ReLU relu = nullptr;
MaxPool2d maxpool = nullptr;
Sequential layer1 = nullptr;
Sequential layer2 = nullptr;
Sequential layer3 = nullptr;
Sequential layer4 = nullptr;
AdaptiveAvgPool2d avgpool = nullptr;
Flatten flatten = nullptr;
Linear fc = nullptr;
};
TORCH_MODULE(ResNet50);
構造体が2つ定義されている。classにしなかった理由は何だろう?
c++の場合、structとclassの違いはアクセシビリティが違うだけだ。structはpublicがデフォルト、classはprivateがデフォルト。これだけである。まあ、これはほとんど好みの問題と言えよう。
1行ずつ読んでいく
#pragma once
#pragmaはコンパイラ機能をコード内で呼び出するための命令だ。onceという予約語は30年前には無かったと思う。ヘッダの先頭にonce(一度)と書いてあるわけで、察するに「コンパイラはこのヘッダを一度だけ読みなさい」という意味だろう。昔は#defineと#ifdef、#ifndefでシコシコ書いたものだ。
#include <torch/torch.h>
using namespace torch::nn;
torch/torch.hはlibtorchのヘッダ。using namespace torch::nnは名前空間を定義している。定義を呼び出すときのスコープ"torch::nn::"を省略できる。ギリギリ知っているキーワードだけど使ったことない。ライブラリが複雑になった、というか30年前に比べていろいろシステムが複雑になってこういうキーワードをよく使うようになったということか。
struct ResidualBlockImpl : Module
コンストラクタの定義。Moduleを継承している。のは分かるけど、Moduleって何?
Moduleのフルテキストはtorch.nn.Module。ここを読むとニューラルネットワーク定義の基底クラスとある。AIが動作に使うテンソルのカプセルということらしい。いいんだけどusingを使うと何の機能を呼び出しているのか分かりにくい。自分のコードではなるべく使いたくない。
ResidualBlockImpl(int in_channels, int out_channels, int stride=1);
これはコンストラクタ。本体はcppファイルの方にあるのだろう。int stride=1といのは引数のデフォルト値かな。こんな記法あったっかなあ? あったかもしれないけど使ったことが無い。3番目の引数は省略できると解釈。ここによると右詰めの引数なら使えるということらしい。
torch::Tensor forward(torch::Tensor input);
これはメンバ関数。Tensor型の変数を入力で、何か変換して、Tensor型の変数を返すらしい。
Tensor型ってなんだろう。テンソルは分かるけどニューラルネットのテンソルとなるとけっこう大きなサイズのはずだ。実体なのかポインタなのかは把握したい。forwardはオーバーロードのようだ。オーバーロードか否かってどうやって見分ければいいのか。
公式ドキュメント
公式ドキュメントを読むがModuleクラスにはforwardの定義が無い。moduleクラスを定義しているソースを見てもforwardの定義が無い。
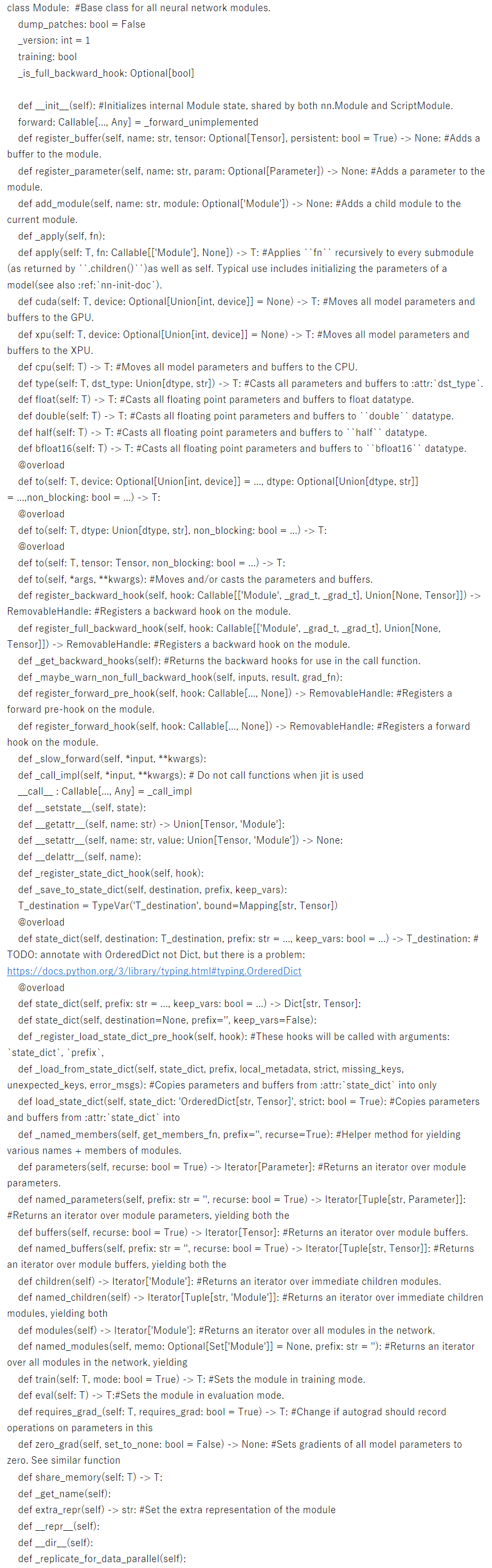
class Module: #Base class for all neural network modules.
dump_patches: bool = False
_version: int = 1
training: bool
_is_full_backward_hook: Optional[bool]
def __init__(self): #Initializes internal Module state, shared by both nn.Module and ScriptModule.
forward: Callable[..., Any] = _forward_unimplemented
def register_buffer(self, name: str, tensor: Optional[Tensor], persistent: bool = True) -> None: #Adds a buffer to the module.
def register_parameter(self, name: str, param: Optional[Parameter]) -> None: #Adds a parameter to the module.
def add_module(self, name: str, module: Optional['Module']) -> None: #Adds a child module to the current module.
def _apply(self, fn):
def apply(self: T, fn: Callable[['Module'], None]) -> T: #Applies ``fn`` recursively to every submodule (as returned by ``.children()``)as well as self. Typical use includes initializing the parameters of a model(see also :ref:`nn-init-doc`).
def cuda(self: T, device: Optional[Union[int, device]] = None) -> T: #Moves all model parameters and buffers to the GPU.
def xpu(self: T, device: Optional[Union[int, device]] = None) -> T: #Moves all model parameters and buffers to the XPU.
def cpu(self: T) -> T: #Moves all model parameters and buffers to the CPU.
def type(self: T, dst_type: Union[dtype, str]) -> T: #Casts all parameters and buffers to :attr:`dst_type`.
def float(self: T) -> T: #Casts all floating point parameters and buffers to float datatype.
def double(self: T) -> T: #Casts all floating point parameters and buffers to ``double`` datatype.
def half(self: T) -> T: #Casts all floating point parameters and buffers to ``half`` datatype.
def bfloat16(self: T) -> T: #Casts all floating point parameters and buffers to ``bfloat16`` datatype.
@overload
def to(self: T, device: Optional[Union[int, device]] = ..., dtype: Optional[Union[dtype, str]] = ...,non_blocking: bool = ...) -> T:
@overload
def to(self: T, dtype: Union[dtype, str], non_blocking: bool = ...) -> T:
@overload
def to(self: T, tensor: Tensor, non_blocking: bool = ...) -> T:
def to(self, *args, **kwargs): #Moves and/or casts the parameters and buffers.
def register_backward_hook(self, hook: Callable[['Module', _grad_t, _grad_t], Union[None, Tensor]]) -> RemovableHandle: #Registers a backward hook on the module.
def register_full_backward_hook(self, hook: Callable[['Module', _grad_t, _grad_t], Union[None, Tensor]]) -> RemovableHandle: #Registers a backward hook on the module.
def _get_backward_hooks(self): #Returns the backward hooks for use in the call function.
def _maybe_warn_non_full_backward_hook(self, inputs, result, grad_fn):
def register_forward_pre_hook(self, hook: Callable[..., None]) -> RemovableHandle: #Registers a forward pre-hook on the module.
def register_forward_hook(self, hook: Callable[..., None]) -> RemovableHandle: #Registers a forward hook on the module.
def _slow_forward(self, *input, **kwargs):
def _call_impl(self, *input, **kwargs): # Do not call functions when jit is used
__call__ : Callable[..., Any] = _call_impl
def __setstate__(self, state):
def __getattr__(self, name: str) -> Union[Tensor, 'Module']:
def __setattr__(self, name: str, value: Union[Tensor, 'Module']) -> None:
def __delattr__(self, name):
def _register_state_dict_hook(self, hook):
def _save_to_state_dict(self, destination, prefix, keep_vars):
T_destination = TypeVar('T_destination', bound=Mapping[str, Tensor])
@overload
def state_dict(self, destination: T_destination, prefix: str = ..., keep_vars: bool = ...) -> T_destination: # TODO: annotate with OrderedDict not Dict, but there is a problem: https://docs.python.org/3/library/typing.html#typing.OrderedDict
@overload
def state_dict(self, prefix: str = ..., keep_vars: bool = ...) -> Dict[str, Tensor]:
def state_dict(self, destination=None, prefix='', keep_vars=False):
def _register_load_state_dict_pre_hook(self, hook): #These hooks will be called with arguments: `state_dict`, `prefix`,
def _load_from_state_dict(self, state_dict, prefix, local_metadata, strict, missing_keys, unexpected_keys, error_msgs): #Copies parameters and buffers from :attr:`state_dict` into only
def load_state_dict(self, state_dict: 'OrderedDict[str, Tensor]', strict: bool = True): #Copies parameters and buffers from :attr:`state_dict` into
def _named_members(self, get_members_fn, prefix='', recurse=True): #Helper method for yielding various names + members of modules.
def parameters(self, recurse: bool = True) -> Iterator[Parameter]: #Returns an iterator over module parameters.
def named_parameters(self, prefix: str = '', recurse: bool = True) -> Iterator[Tuple[str, Parameter]]: #Returns an iterator over module parameters, yielding both the
def buffers(self, recurse: bool = True) -> Iterator[Tensor]: #Returns an iterator over module buffers.
def named_buffers(self, prefix: str = '', recurse: bool = True) -> Iterator[Tuple[str, Tensor]]: #Returns an iterator over module buffers, yielding both the
def children(self) -> Iterator['Module']: #Returns an iterator over immediate children modules.
def named_children(self) -> Iterator[Tuple[str, 'Module']]: #Returns an iterator over immediate children modules, yielding both
def modules(self) -> Iterator['Module']: #Returns an iterator over all modules in the network.
def named_modules(self, memo: Optional[Set['Module']] = None, prefix: str = ''): #Returns an iterator over all modules in the network, yielding
def train(self: T, mode: bool = True) -> T: #Sets the module in training mode.
def eval(self: T) -> T:#Sets the module in evaluation mode.
def requires_grad_(self: T, requires_grad: bool = True) -> T: #Change if autograd should record operations on parameters in this
def zero_grad(self, set_to_none: bool = False) -> None: #Sets gradients of all model parameters to zero. See similar function
def share_memory(self: T) -> T:
def _get_name(self):
def extra_repr(self) -> str: #Set the extra representation of the module
def __repr__(self):
def __dir__(self):
def _replicate_for_data_parallel(self):
pythonの構文に慣れているわけではないがforwardの定義がないことくらいわかる。
module.hを読む
気を取り直してcppのヘッダのmoduleの定義を見てみる。
class TORCH_API Module : public std::enable_shared_from_this<Module> {
explicit Module(std::string name);
/// Constructs the module without immediate knowledge of the submodule's name.
/// The name of the submodule is inferred via RTTI (if possible) the first
/// time `.name()` is invoked.
Module();
virtual ~Module() = default;
protected:
/// The following three functions allow a module with default arguments in its
/// forward method to be used in a Sequential module.
/// You should NEVER override these functions manually. Instead, you should use the
/// `FORWARD_HAS_DEFAULT_ARGS` macro.
virtual bool _forward_has_default_args() {
return false;
}
virtual unsigned int _forward_num_required_args() {
TORCH_CHECK(
false,
"torch::nn::Module subclass that has default arguments in `forward` method ",
"must override `_forward_num_required_args` method. Please use ",
"`FORWARD_HAS_DEFAULT_ARGS` macro to do so.");
}
virtual std::vector<AnyValue> _forward_populate_default_args(std::vector<AnyValue>&& arguments) {
TORCH_CHECK(
false,
"torch::nn::Module subclass that has default arguments in `forward` method ",
"must override `_forward_populate_default_args` method. Please use ",
"`FORWARD_HAS_DEFAULT_ARGS` macro to do so.");
}
/// The registered parameters of this `Module`.
/// Inorder to access parameters_ in ParameterDict and ParameterList
// NOLINTNEXTLINE(cppcoreguidelines-non-private-member-variables-in-classes)
OrderedDict<std::string, Tensor> parameters_;
}
長いので気になった所だけを抜き出している。結論から言うとforward関数は無かったが、"torch::nn::Module subclass that has default arguments in forward method must override _forward_populate_default_args method. Please use FORWARD_HAS_DEFAULT_ARGS macro to do so."。とある。サブクラスでは必ずforward関数をオーバーライドしろとある。どういうカラクリなのか分からないが今のc++だとオーバーライドを強制できるらしい。それにしても知らないキーワードがいっぱいだ・・・
今日はここまで
つづく