日本天文学会が、軍事目的の研究に反対する声明を出した。それは会員アンケートに基づくものだそうだ。声明文に世代別の賛成、反対の割合と、その元データ(各回答者数)がある。割合のプロットを見ると、世代が進むにつれ反対が増え、その様子は線形だと見る話もある。
しかしせっかく計数データがあることだし、世代間にギャップがあるかどうか、Julia で検定作業をやってみた。
まず声明文からデータを CSV ファイルに保存する。こんな感じ。
年齢層,賛成,反対
10代,0,1
20代,98,46
30代,101,92
40代,92,106
50代,44,95
60代,26,68
70代,6,25
これを CSV.read() で読み込む。そして賛成、反対の割合も計算する。
julia> using CSV, Gadfly, DataFrames, DataFramesMeta, Statistics, Distances, Fontconfig, Distributions, Cairo
julia> dat = CSV.read("天文学と安全保障.csv", allowmissing = :none)
julia> ldat = stack(dat, [:賛成, :反対]) # ロングフォーマットに変換
julia> names!(ldat, [:賛否, :人数, :年齢層])
14×3 DataFrame
│ Row │ 賛否 │ 人数 │ 年齢層 │
│ │ Symbol │ Int64 │ String │
├─────┼────────┼───────┼────────┤
│ 1 │ 賛成 │ 0 │ 10代 │
│ 2 │ 賛成 │ 98 │ 20代 │
...
# 賛成、反対の割合のデータも作る
julia> datr = deepcopy(dat)
julia> insertcols!(datr, 4, 賛成率 = datr[:,:賛成] ./ (datr[:,:賛成] .+ datr[:,:反対]))
julia> insertcols!(datr, 5, 反対率 = datr[:,:反対] ./ (datr[:,:賛成] .+ datr[:,:反対]))
julia> ldatr = stack(datr[:,[:年齢層,:賛成率,:反対率]], [:賛成率, :反対率])
julia> names!(ldatr, [:賛否率, :割合, :年齢層])
14×3 DataFrame
│ Row │ 賛否率 │ 割合 │ 年齢層 │
│ │ Symbol │ Float64 │ String │
├─────┼────────┼──────────┼────────┤
│ 1 │ 賛成率 │ 0.0 │ 10代 │
│ 2 │ 賛成率 │ 0.680556 │ 20代 │
...
で、計数値をプロットする。
julia> draw(PDF("enq_1.pdf", 10cm, 8cm),
plot(ldat, xgroup = :年齢層, x = :賛否, y = :人数, color = :賛否,
Geom.subplot_grid(Geom.bar)))
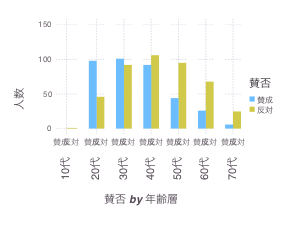
で、割合もプロットして見てみる。
julia> draw(PDF("enq_2.pdf", 10cm, 8cm),
plot(ldatr, xgroup = :年齢層, x = :賛否率, y = :割合, color = :賛否率,
Geom.subplot_grid(Geom.bar)))
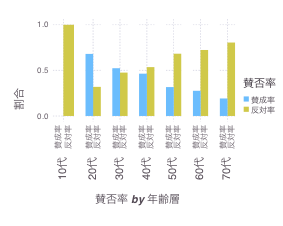
天文学会の声明では、10代の反対率が 100% ではなく 1% としてプロットされている。まぁ10代のサンプル数は1なので、それを 100% とプロットしてミスリードになるのを避けたのだろうと想像する。というか、10代の会員がいるのか。すごい。
各年代の間で、賛否の割合に有意な差があるかどうか、カイ二乗検定で調べてみる。
julia> p = zeros(6)
julia> for i in 1:6
p[i] = pvalue(ChisqTest(convert(Matrix, dat[[i,i+1],[:賛成,:反対]])))
end
julia> Generation_Interval = ["10 vs 20", "20 vs 30", "30 vs 40",
"40 vs 50", "50 vs 60", "60 vs 70"]
julia> pv = DataFrame([Generation_Interval, p])
julia> names!(pv, [:Generation_Interval, :p_value])
6×2 DataFrame
│ Row │ Generation_Interval │ p_value │
│ │ String │ Float64 │
├─────┼─────────────────────┼────────────┤
│ 1 │ 10 vs 20 │ 0.147339 │
│ 2 │ 20 vs 30 │ 0.00368634 │
│ 3 │ 30 vs 40 │ 0.246002 │
│ 4 │ 40 vs 50 │ 0.00637229 │
│ 5 │ 50 vs 60 │ 0.514027 │
│ 6 │ 60 vs 70 │ 0.358213 │
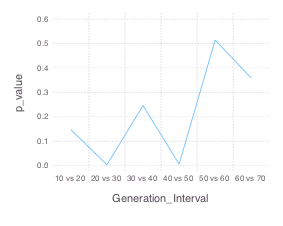
20代と30代の間、40代と50代の間でp値がかなり小さい。ここには軍事研究に対する意識に世代差があると見ていいのかもしれない。他のところはp値はぜんぜん小さくない。つまり世代差があるとは言えない。かと言ってじゃぁそこは世代差がないのかというと、それはわからない。サンプル数が増えればp値は小さくなる。サンプル数 = アンケートの回答者数が少ないのは、その世代の会員が少ないのか、このネタに関心が少なくて答えてないのかはわからない。棄権数/無回答数を入れた全会員数に対して、世代ごとに賛成/賛成以外(または反対/反対以外)の人数からその割合の違いを検定して上の例と比較するといいかもしれない。
結論
賛否の割合は年代に対して線形に変動しているが、同じ幅の変動でも「変動があるとは言い切れない」ところと「あると言える」ところがある。無回答数を入れたデータがあれば、全ての世代間で変動があると言えるかどうか、特定のところにだけジェネレーションギャップがあるのか、その辺の判断がつくかもしれない。