Towards Viewpoint Invariant 3D Human Pose Estimation(CVPR2016)
description: 論文読んだまとめ記事
url: https://arxiv.org/abs/1603.07076
自分なりに解釈したメモになります。
ミスがあったら優しく教えてください。
- Title
Towards Viewpoint Invariant 3D Human Pose Estimation - Conference
CVPR2016 (Computer Vision and Pattern Recognition) - Authors
Albert Haque, Boya Peng*, Zelun Luo*, Alexandre Alahi, Serena Yeung, Li Fei-Fei スタンフォードのコンピュータサイエンスをテーマにする研究室からの論文。 ファーストオーサーAlbertはポスドクで毎年のようにNIPS、ICCVへ論文を通している。 音声認識や画像認識を医療分野に適応する研究を行っており、特にデプス情報に関する研究が多い。 デプスマップから患者が何時起きていつ寝たなどの行動を推定して記録するようなシチュエーションに関係する研究が多く、この論文もその一環であるように考えられる。 また、ポケモンについても論文書いているなどおちゃめな側面もある。 > https://arxiv.org/pdf/1902.06208.pdf ---
どんなもの?
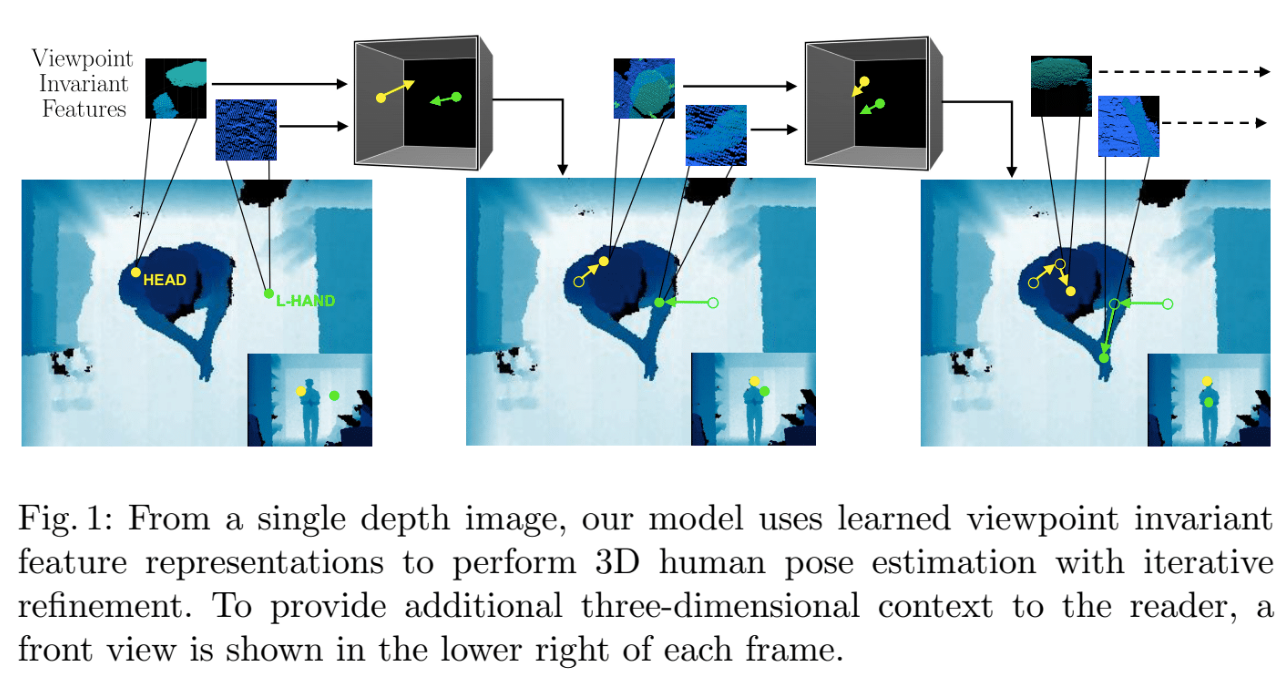
頭上にあるデプスカメラの情報から人間の位置姿勢を推定する
先行研究と比べて何がすごい?
- 天井からの視点
ポーズ推定を正面視点や側面視点のカメラで行うような研究は活発であるが、多くのカメラは高い位置に付いている。(ex. 商店や病院など) 上部視点からの認識はオクルージョンのために従来手法で検出が難しく、あまり研究されていない。 本手法は天井視点という困難な問題に対して、単一のデプスカメラによって人間の三次元位置推定をおこなう。
技術の手法や肝は?
3Dの空間的な情報から推論するだけではなく、視点に対してもロバストなネットワークを設計した。
- multi-task learnin
-
CNN、RNN、1フレーム前に推定したポーズを組み合わせたモデル構造
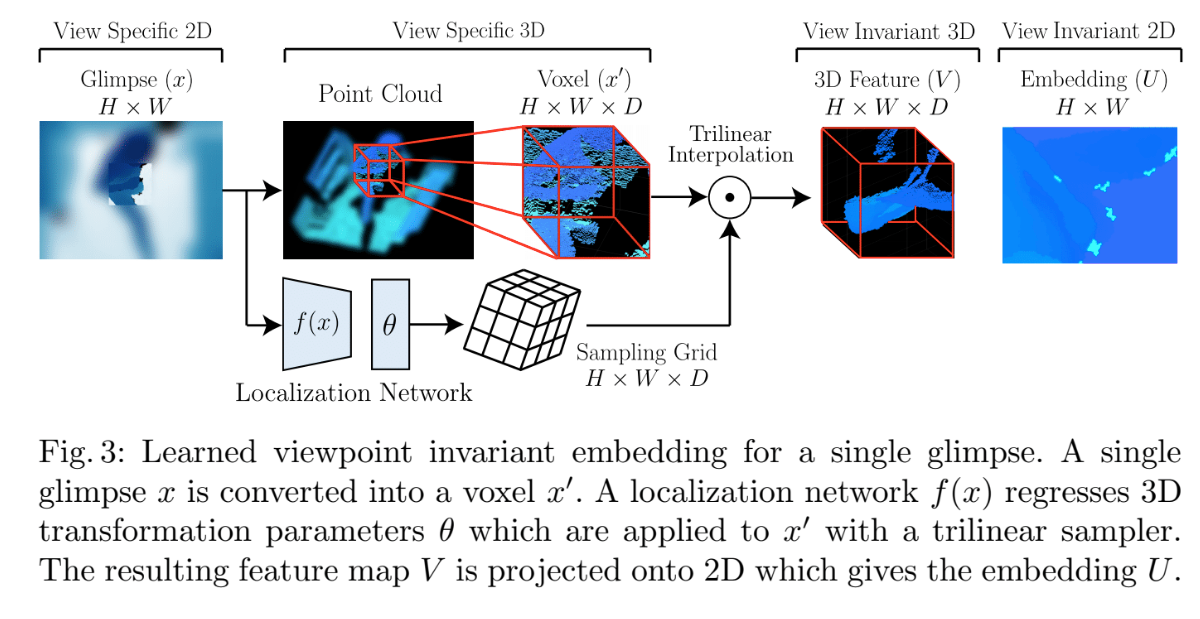
glimpse(垣間見えるという意味) [ecurrent models of visual attention. NIPS 2014]
本研究ではJ個のボディーパーツに対応するglimpse画像J枚を入力として利用する。
glimpseは特定の領域以外をぼやけさせて、強制的にモデルに対して特定の領域を重要視させる。視点に対して不変な特長空間取得
glimpsesをpoint cloudに変換するA spatial transformer [STN(NIPS15)]を用いてモデルにとって解釈しやすいように切り出される(三次元の線形変換)
人工的オクルージョンが作られる(?)移動したポイントクラウドは視点に対して不変な特長量となる

頭上カメラはオクルージョンの問題が激しいため、損失関数を工夫していた。
具体的にはオクルージョンを考慮したボディーパーツの誤差(オクルージョンがあるときはlog(p)、無いときにはlog(1-p)となる)と、一般的なLocalizationの誤差の和を用いている。
~オクルージョンには推定した時の値が入っておらず、どういう意味でつけているのかがよく分からないので、よく論文を読み込んで確かめたい。~
どうやって有効だと検証したか
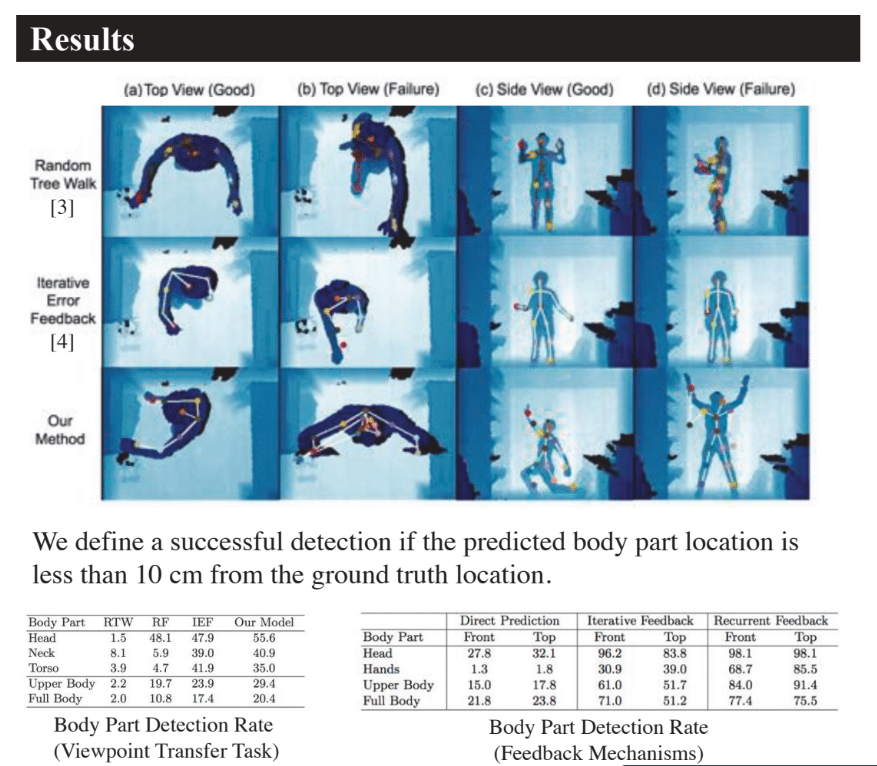
推定座標と正解座標が10cm以内であれば正しいとしている。
参考文献
http://www.eccv2016.org/files/posters/P-3B-47.pdf
https://www.alberthaque.com/
http://vision.stanford.edu/feifeili/
https://www.alberthaque.com/projects/viewpoint_3d_pose/