今回はlimitation知らずにちょっとはまった話です。
複数種類のcsvファイルをSplunkに取り込み、まとめて横串検索を実施していたときに出会った不可解な事象
- index時に自動でフィールド抽出済みのはずなのに、なぜかサーチしても意図したフィールド”すべて”が表示されない!
-
焦ったポイント(汗)
- 一部はフィールド抽出されている。
- 対象のcsvファイルをへらすと、事象が改善される。
-
エラーメッセージはない。
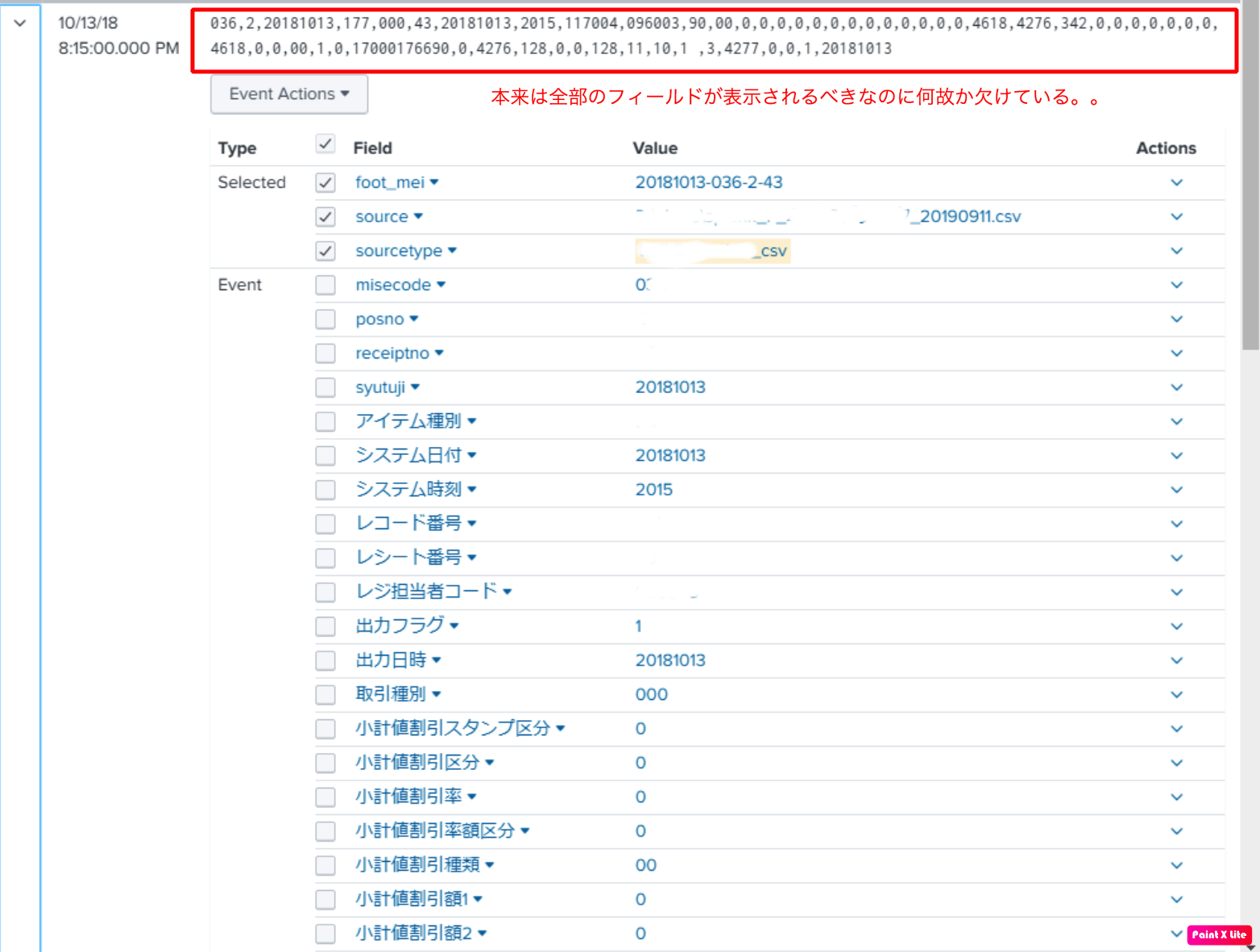 分かりにくい画像ですが、意図したフィールドすべてが抽出できない事象が発生しました。
分かりにくい画像ですが、意図したフィールドすべてが抽出できない事象が発生しました。
原因
- デフォルトのindex時フィールドの検索フィールド抽出数の上限に達していたため、結果にすべてのフィールドが表示されなかった。
- 仕様詳細はこちら
- 以下、該当箇所を抜粋
[184ページ] ⾏の数が多い構造化データファイルは、Splunkサーチで全ての抽出ファイルを表⽰しない可能性があります。
構造化データファイルを多数の⾏によってインデックス作成する(例えば、CSVファイルを300のコロンでインデックスする)と、サーチAppが戻らない、もしくはそのファイルのフィールドを全て⽰さないような問題が後々発⽣する可能性があります。全てのフィールドにインデックス作成をしてもこのような問題が発⽣するのは、サーチ時にSplunkソフトウエアのフィールドの抽出⽅法を設定しているためです。
Splunk ソフトウエアがSplunk Web上にフィールドを表⽰する前に、サーチ時フィールドの抽出を実⾏し、それらのフィールドを抽出しなければなりません。デフォルトでは、サーチ時の⾃動フィールドの抽出数は**100**に制限されています。$SPLUNK_HOME/etc/system/local の limits.conf ファイルを編集し、また limit 設定を構造化データファイルの⾏数より多い数にすることにより、この数値をより⾼く引き上げることができます。
limits.conf
[kv]
limit = 300
多数のCSVファイルで作業する場合、設定が構造化データファイルに求める⾏の最⼤数を表す数にする必要があるといえます。
回避策
- /opt/splunk/system/local/limits.confに以下を追記することで、すべてのフィールドが表示されました。
limits.conf
[kv]
limit = 300
まとめ
- 日本語のフィールド名を含むcsvファイルだし、もしかしてバグふんだか?と焦ってましたが、なんてことはない。limitationでした。
- google検索する時に「is there any limitation default csv field extraction splunk」ととりあえず英語で調べてみるとなにかしら引っかかるものです。他には「how to xxxx splunk」とかよく使います。