本記事は、TensorFlow Advent Calendar 2018 の23日目の記事です。
12/25に公開する予定でしたが、12/23が空いていてすでに記事を書き終えてしまったため、少しフライングして公開します。
TensorFlowのGoogle Groupのアナウンス によると、2018年末~2019年初にかけてTensorFlow 2.0が公開される予定です。
とはいえ、執筆時点でr1.13のブランチが切られていることから、TensorFlow 2.0の前に、TensorFlow 1.13が公開される可能性が高そうです。このため、TensorFlow 2.0の公開は2019年になるものと考えられます。
TensorFlow 2.0の機能は、tensorflow/community のページにて公開されているDesign Documentから確認することができます。
本記事では、公開されているDesign Documentから確認できるTensorFlow 2.0の変更点についてまとめたいと思います。
なお本記事で示す変更点については、TensorFlow 2.0への移行準備という謳い文句で、TensorFlow 1.xの時点ですでに追加されているものもあります。
また、本記事を執筆している間にも、TensorFlow 2.0に向けた修正はTensorFlowのリポジトリに入ってきていますし、Design Documentも更新され続けています。
変更を確認次第、本記事も更新していきます。
TensorFlow 2.0における主な変更点
TensorFlowのアナウンスにもある通り、TensorFlow 2.0における大きな変更点は以下の3つになります。
- Eager Mode1のデフォルト化
- より多くのプラットフォームやプログラミング言語、モデルフォーマットに対応
- 古いAPIや重複したツールを整理
特にEager Modeのデフォルト化は、Graph Mode2をデフォルトとしていた既存のTensorFlowの使い勝手を大きく変えるものであり、Design DocumentにもEager Mode関連のドキュメントが多数存在します。
Eager Modeをデフォルトで採用するPyTorchの使い勝手の良さが注目されていることもあり、長らくデフォルト化し続けてきたGraph ModeからEager Modeへのデフォルト化に舵を切ったのでしょう。
古いAPIや重複したツールの整理も、TensorFlow 2.0における大きな変更点の1つです。
特にその中でも変更の影響が大きいのは、contribディレクトリ の廃止かと思います。
contribディレクトリには、公式にサポートされていない数多くの第3者が開発した拡張機能やツールが置かれています。
contribディレクトリは公式でメンテナンスされていないため、すでにコアとして取り込まれているのにもかかわらずcontribディレクトリに残っている機能や、長らくメンテナンスされていなくDeprecatedな機能が多数存在しています。
このため、TensorFlow 2.0ではこれらの大掃除が行われる見込みで、contribディレクトリに置かれた機能を利用しているプログラムは動作しなくなることが考えられます。
TensorFlow 2.0の変更詳細
tensorflow/community のページにて公開されているDesign Documentから、TensorFlow 2.0における変更の詳細をまとめます。
Design Documentで示されている変更内容の粒度は、Design Documentごとに大きく異なります。
ここでは変更内容別に、影響範囲順に具体的な変更内容を示します。
Eager Modeのデフォルト化
Functions, not sessions (Design Document)
Eager Modeのデフォルト化に向けた変更の中核である、Design Documentです。
Design Documentによって提示されている変更内容は、以下の通りです。
- Eager Modeをデフォルトで有効化
-
tf.functionデコレータで修飾された関数を実行した場合、従来のGraph Modeで実行可能(計算グラフ最適化処理も適用される) - TensorFlow 2.0における、SavedModelやチェックポイント対応
Eager ModeとGraph Modeの使い分け
tf.function でデコレートされた関数内はGraph Modeで実行され、それ以外のPythonプログラム部分はEager Modeで実行されます。
Graph Modeで実行される箇所については、従来のTensorFlowのGraph Modeの仕組みを利用するため、計算グラフの最適化や最適化グラフのキャッシュ機構により、2度目以降はEager Modeと比較して高速に実行することができます。
import tensorflow as tf
def f(x):
x = x + 5
x = tf.sqrt(x)
return x
v = tf.Variable(4.0)
init = tf.global_variables_initializer()
# Graph Modeで実行される
with tf.Session() as sess:
sess.run(init)
print(sess.run(f(v)))
import tensorflow as tf
# Graph Modeで実行される
@tf.function
def f(x):
x = x + 5
x = tf.sqrt(x)
return x
# Eager Modeで実行される
v = tf.Variable(4.0)
y = f(v)
print(y)
Variableの生存期間
Variableの生存期間が変更され、Variableが削除されるタイミングが以下のように変更されます。
Sessionの生存期間とVariableの生存期間が一致していたTensorFlow 1.xと比べて、TensorFlow 2.0ではPythonの振る舞いに近くなります。
- v1.x:
Sessionオブジェクトがcloseされた時 - v2.0:
tf.Variableを保持する変数が削除された時
チェックポイントの保存
TensorFlow 1.xでは、Sessionに保存されている全てのVariableが保存されるようになっていました。
TensorFlow 2.0ではSessionが廃止されたことにより、プログラムで明示的に指定したVariableのみを保存するように変更されます。
import tensorflow as tf
v = tf.Variable(4.0)
train_op = v.assign(1.0)
init = tf.global_variables_initializer()
saver = tf.train.Saver()
# チェックポイント保存
with tf.Session() as sess:
sess.run(init)
sess.run(train_op)
saver.save(sess, "/tmp/ckpt/checkpoint")
# チェックポイント読み込み
with tf.Session() as sess:
sess.restore(sess, "/tmp/ckpt/checkpoint")
sess.run(train_op)
import tensorflow as tf
v = tf.Variable(4.0)
v.assign(1.0)
ckpt = tf.train.Checkpoint(W=v)
# チェックポイント保存
ckpt.save("/tmp/ckpt/checkpoint")
# チェックポイント読み込み
ckpt.restore("/tmp/ckpt/checkpoint")
計算グラフの保存
TensorFlow 1.xでは、TensorFlowの計算グラフを保存するために、グローバルに持っているGraphを保存する必要がありました。
TensorFlow 2.0では、tf.function デコレータが指定された関数(Graph Modeで実行される部分)のみを、計算グラフとして保存することが可能です。
import tensorflow as tf
v = tf.Variable(4.0)
train_op = tf.add(v, 5.0)
# 計算グラフ保存
graph_def = tf.get_default_graph().as_graph_def()
with open("/tmp/graph/graph.pb", "w") as f:
f.write(graph_def.SerializeToString())
tf.reset_default_graph()
# 計算グラフ読み込み
graph_def = tf.GraphDef()
with open("/tmp/graph/graph.pb") as f:
graph_def.ParseFromString(f.read())
tf.import_graph_def(graph_def)
import tensorflow as tf
@tf.function
def f(x):
return x + 5.0
v = tf.Variable(4.0)
graph_def = f(v).graph.as_graph_def()
# 計算グラフ保存
with open("/tmp/graph/graph.pb", "w") as f:
f.write(graph_def.SerialieToString())
SavedModelの保存
TensorFlow 2.0におけるSavedModelの扱い方については、「SavedModel Save/Load in 2.x」にて具体的な設計が書かれています。
「SavedModel Save/Load in 2.x」を参照ください。
SavedModel Save/Load in 2.x (Design Document)
注意: 本変更点に関するDesign Documentは現在レビュー中であり、内容が変更される可能性があります。
Eager Modeのデフォルト化により、SavedModelが利用していた tf.Session や tf.train.Saver が廃止されます。
このため、SavedModelを保存するための新たなAPI tf.saved_model.save が提供され、SavedModelを読み込むためのAPI tf.saved_model.load がTensorFlow 2.0に対応します。
Design Documentによって提示されている修正内容は、以下の通りです。
- TensorFlow 1.xで提供されていたSavedModelのAPIや周辺機能(TensorFlow Hub、TensorFlow Servingなど)との連携は維持
- TensorFlow 1.xで作成されたSavedModelは、TensorFlow 2.0でも読み込み可能とする
Design Documentには、SavedModelの保存/読み込みの例が示されています。
Design Documentで示されている例は、tf.train.Checkpointable を継承したクラスを作成し、クラスのメンバ変数として保持するVariable一式と、tf.function デコレータによってGraph Modeで実行されるメソッドで定義される計算グラフを、SavedModelとして保存するというものです。
import tensorflow as tf
v = tf.Variable(4.0)
x = tf.placeholder(tf.float32, shape=(None))
y = tf.add(v, x)
init = tf.global_variables_initializer()
with tf.Session() as sess:
sess.run(init)
# SavedModel保存
tf.saved_model.simple_save(
sess, "/tmp/saved_model/model",
inputs={"x": x}, outputs={"y": y})
with tf.Session() as sess:
# SavedModel読み込み
tf.saved_model.load(
sess, [tf.saved_model.tag_constants.SERVING], "/tmp/saved_model/model")
import tensorflow as tf
class Model(tf.train.Checkpointable):
def __init__(self):
self.v = tf.Variable(4.0)
@tf_function
def f(self, x):
return tf.add(self.v, x)
model = Model()
# SavedModel保存
tf.saved_model.save(model, "/tmp/saved_model/model")
# SavedModel読み込み
model = tf.saved_model.load("/tmp/saved_model/model")
Variables in TensorFlow 2.0 (Design Document)
Eager Modeがデフォルトで有効化されることで、Graph Modeに特化されていた tf.Variable の実装や扱い方が変更になります。
Design Documentによって提示されている修正内容は、以下の通りです。
-
tf.Variableの名前空間を定義する方法が変更-
tf.variable_scopeを扱う場合は、tf.compat.v1.variable_scopeを利用 -
tf.Variableに名前空間を設定する場合は、tf.name_scopeを利用
-
-
tf.Variableの実装が、RefVariableからResourceVariableへ変更- TensorFlow 1.xで採用していたRefVariableを利用した
tf.Variableを扱う場合は、tf.compat.v1.Variableを利用
- TensorFlow 1.xで採用していたRefVariableを利用した
-
tf.assign関連のAPIが削除-
tf.Variableのメソッドとして提供
-
プラットフォームのサポート拡大
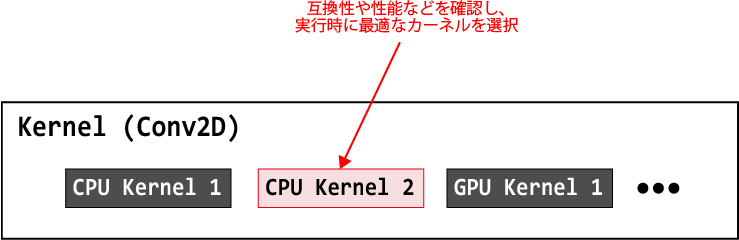
Dynamic Loading of Kernels in TensorFlow (Design Document)
TensorFlowでは、Adding a New Op に従ってユーザ独自のOperationやその実装(カーネル)を追加することができます。
しかし追加可能なOperationは、TensorFlowに存在しない新たなOperationであり、Conv2DやAddなどの既存のOperationのカーネルを容易に置き換えることはできませんでした。
これはTensorFlow内部で、Operationとデバイスをkeyとして1つのカーネルを結びつけ、同じOperationかつ同じデバイスに対して2つ以上のカーネルを登録できない内部実装による制限です。
本修正により、同じデバイスかつ同じデバイスであっても複数のカーネルを登録できるように改良され、ランタイムでカーネルが読み込まれるようになります。
ランタイムでカーネルを読み込むときに、ハードウェアやコンパイルオプションなどの互換性をチェックする機能も追加され、様々なバックエンドやカーネル実装に対応することができるようになります。
More Flexible Concurrency (Design Document)
注意: 本変更点に関するDesign Documentは現在レビュー中であり、内容が変更される可能性があります。
TensorFlowの計算グラフで定義された一連のOperationを実行する時、Operation間は異なるスレッドで実行されます。
計算グラフの中で実行可能になったOperation1つに対して1つのスレッドを割り当てて実行することで、Operation間は並列に実行されるというのが、TensorFlowが採用するスレッドスケジューリングです。
Operationへのスレッド割り当て方式はTensorFlowでは固定されているため、ユーザが制御することはできませんでした。
TensorFlow 2.0では、Operation間のスレッドスケジューリングの実装をプラグイン的に追加できるようになり、これまで制御が難しかったOperation間のスレッド制御が容易になります。
API整理
Sunsetting tf.contrib (Design Document)
注意: 本変更点に関するDesign Documentは現在レビュー中であり、内容が変更される可能性があります。
tf.contrib には、公式でサポートしないTensorFlowの拡張機能などが置かれています。
しかし、時間とともに tf.contrib に置かれている機能が肥大化し、中には重複する機能やメンテナンスされていない機能も含まれるようになりました。
TensorFlow 2.0では tf.contrib を廃止し、tf.contrib 関連のソースコードは以下のいずれかの扱いを受けることになります。
当然のことながら、本変更によってAPIのエンドポイントも変わる予定です。
- コアへ移動し、TensorFlowで公式にメンテナンスされる
- 例:
tf.contrib.lite、tf.contrib.eager
- 例:
- Addonリポジトリ3へ移動
- 例:
tf.contrib.probability-> tensorflow/probability
- 例:
- 削除
具体的にどのソースコードが上記のどのパターンに当てはまるかは、Design Document に一覧で示されています。
TensorFlow Namespaces (Design Document)
度重なるTensorFlowのアップデートにより、重複が生じているAPIや、APIのエンドポイントが適切でないものが目立つようになってきました。
このためTensorFlow 2.0では、提供されるPython APIが整理されます。
なお、TensorFlow 1.10.0 においても新しい名前空間が追加されており、ここで示されている名前空間への移動も行われます。
TensorFlow 2.0において追加されるAPIのエンドポイントは Design Document (Appendix 1: Additional Endpoints)、削除されるエンドポイントは Design Document (Appendix 2: Deprecated Endpoints) にまとまっています。
多くのAPIのエンドポイントが変更になりますが、TensorFlow 2.0において新たに追加・削除される名前空間は、以下の通りです。
追加される名前空間
-
tf.random- 乱数関連のAPI
-
tf.version- バージョン関連のAPI
削除される名前空間
-
tf.logging- 名前空間
tf.manipへ統合される
- 名前空間
Unify RNN Inteface (Design Document)
RNN関連のAPIは、TensorFlowとKerasの両方で提供され、両方から提供されるAPIを合わせるとその数は数十個にもなります。
このため、APIの中には異なるエンドポイントとして提供されているにもかかわらず機能が重複していることもあるため、ユーザがどの
APIを利用したらよいかを判断するのが、わかりづらい状況になっています。
この状況を省みて、TensorFlow 2.0ではRNN関連のAPIを統合・削除することで、ユーザが直感的に使えるAPIとなるように整理されます。
具体的な修正はDesign Documentによって提示され、以下のような修正が行われます。
- APIの利用頻度、性能、Kerasにおける同様の機能を持つAPIのサポート状況を考慮してAPIを整理
-
tf.contribに配置されているRNNのAPIも整理の対象で、必要に応じてコア4に移動
-
- cuDNN版RNNのAPIを統合
- API内部でcuDNNの利用可否を判断
API整理
TensorFlowやKerasで提供されるAPIのGoogle社内での利用頻度や、APIの性能に基づいて、APIを以下のパターンで整理します。
具体的にどのAPIがどのパターンに当てはまるかは、Design Document にまとめられています。
-
tf.v1.compatとして残す - 削除
- コアに移動
- Addonリポジトリ3に移動
Optimizer unification (Design Document)
TensorFlowとKerasのそれぞれで、Optimizer関連のAPIが提供されています。
TensorFlow 2.0では、Eager Modeのデフォルト化とDistribution Strategyのサポート範囲拡大により、TensorFlowのOptimizer APIを利用することが今後は推奨されます。
しかし、Kerasが提供するOptimizer関連のAPIは、TensorFlowのAPIには存在しない機能を持つものもあるため、TensorFlowとKerasで統一化したOptimizer APIを提供するように、APIが整理されます。
Design Documentには、より詳細な変更内容が書かれており、以下のように変更されることが示されています。
- Optimizer APIの仕様変更
- Optimizerの各パラメータ、ハイパーパラメータを取得/設定するためのメソッドを追加
- 複数の計算グラフ間でOptimizerを流用することの禁止
- Optimizer APIを
tf.keras.optimizersに移動
具体的な変更については、Design Document を参照してください。
Deprecating collections (Design Document)
注意: 本変更点に関するDesign Documentは現在レビュー中であり、内容が変更される可能性があります。
Eager Modeがデフォルト化されることに伴い、TensorFlow 1.xで計算グラフに紐づいて管理されていたCollection関連のAPIが廃止されます。
つまり tf.GraphKeysで提供されていたCollection は、TensorFlow 2.0で利用できなくなります。
例えば、TensorFlow 1.xではグローバルな tf.Variable 一式を取得するために tf.get_collection(tf.GraphKeys.GLOBAL_VARIABLES) を利用していましたが、TensorFlow 2.0からは tf.Variable の管理はユーザ責任となります。
New tf.print (Design Document)
注意: 本変更点に関するDesign Documentは現在レビュー中であり、内容が変更される可能性があります。
TensorFlow 1.xのAPIである tf.Print は、計算グラフの中にテンソルを出力するOperationとしてPrintを追加するものでした。
このため、計算グラフの構造によっては期待した値が出力されない ことや、Pythonの組み込み関数であるprint関数をOperationに対して実行して混乱する ことがあるなどの混乱を招くAPIの1つとなっていました。
TensorFlow 2.0ではEager Modeがデフォルトで採用されることに伴い、tf.Print の機能はPythonの組み込み関数である print 関数に取って代わられ、引数に指定された値の中身がグラフを実行せずとも、print 関数実行時にテンソルの中身を確認できるようになります。
また、フォーマット文字列を指定可能な tf.string.Format も提供されます。
以下では、TensorFlow 1.xの tf.Print の出力と、TensorFlow 2.0の print の出力を比較したものを示します。
>>> import tensorflow as tf
>>>
>>> a = tf.constant([[1.5, 8.9], [2.5, 3.4]])
>>> b = tf.constant([[2.6, 8.4], [1.9, 0.4]])
>>> output = a + b
>>> print_op = tf.Print(output, [output])
>>>
>>> with tf.Session() as sess:
>>> sess.run(print_op)
[[4.1 17.3][4.4]...]
>>> import tensorflow as tf
>>>
>>> a = tf.constant([[1.5, 8.9], [2.5, 3.4]])
>>> b = tf.constant([[2.6, 8.4], [1.9, 0.4]])
>>> output = a + b
>>> print(output)
tf.Tensor(
[[ 4.1 17.3 ]
[ 4.4 3.8000002]], shape=(2, 2), dtype=float32)
Distribution Strategy - Revised API (Design Document)
複数GPUを利用した訓練など、複数GPU/複数計算ノード環境下での演算を容易に行えるようにするため、TensorFlowではDistribution Strategy APIを提供しています。
Distribution Strategy APIは、TensorFlow 1.xではKerasやEstimatorを通して利用することが推奨されていましたが、TensorFlow 2.0では通常のTensorFlow APIからも使えるように拡張されます。
また、これに伴ってDistribution Strategy APIは tf.contrib からコアに移動します。
Distribution Strategyを通常のTensorFlow APIから使う例が、Design Documentに示されています。
# Distribution Strategyの1つである「MirroredStrategy」を作成
strategy = tf.distribute.MirroredStrategy(...)
session_config = strategy.update_session_config()
# 学習の入力となるデータのイタレータ(InputIterator)を取得
input_iterator = strategy.make_input_iterator(input_fn)
# 演算のレプリカを作成
per_replica_losses = strategy.run(step_fn, input_iterator)
# 各デバイスの演算結果を集約
mean_loss = strategy.reduce(per_replica_losses)
with tf.Session(config=session_config) as session:
# MirroredStrategyの初期化処理
session.run(strategy.initialize())
# InputIteratorの初期化
session.run(input_iterator.initialize())
# MirroredStrategyオブジェクトの設定に沿って学習演算実行
for _ in range(num_train_steps):
loss = session.run(mean_loss)
# MirroredStrategyの終了処理
session.run(strategy.finalize())
Estimator Head (Design Document)
tf.contrib で提供されている TensorFlow Estimator のHead APIを、コアに移動します。
Head APIは、Estimatorで学習演算している途中で行う評価やLoss値の確認のための演算を、ユーザから登録できるようにしたAPIです。
Estimatorは、Head APIを使ってユーザから登録された各演算を実行し、それぞれの結果をユーザに返します。
この時、ユーザはEstimatorの詳細を意識する必要はありません。
Design Documentには、Head APIを使ったサンプルが紹介されています。
# 学習演算の途中に実行したい演算の定義(ここでは、マルチラベル分類と2項分類を学習演算中に実施)
head_a = tf.estimator.multi_label_head(n_classes=3)
head_b = tf.estimator.binary_classification_head()
my_head = tf.estimator.multi_head([head_a, head_b])
# Estimatorオブジェクトの作成
my_estimator = tf.estimator.DNNEstimator(
head=my_head,
feature_columns=[embedding_a, embedding_b],
hidden_units=...)
Functional cond (Design Document)
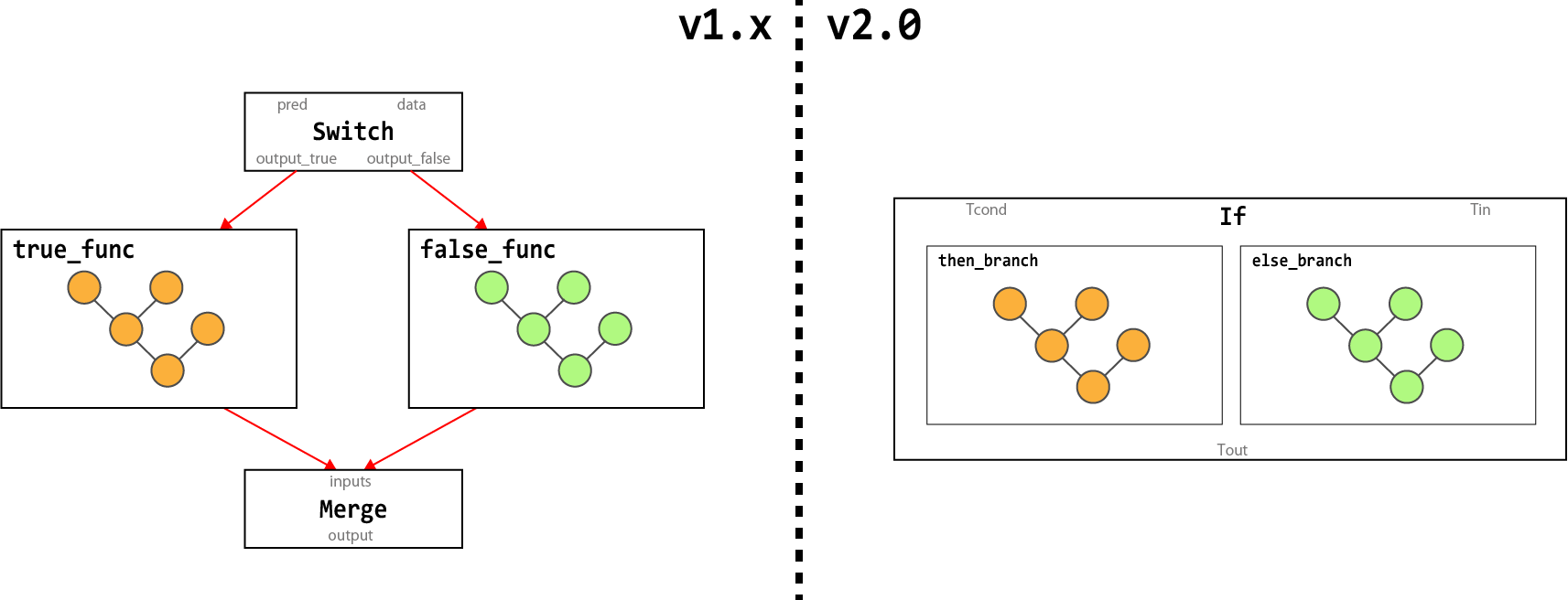
TensorFlow 1.xにおける条件分岐を実現する tf.cond は、SwitchとMergeの2つのOperationから構成されています。
しかし、計算グラフの最適化を積極的に行うTensorFlow XLAにおいて、SwitchとMergeから構成される計算グラフは2つのOperationから構成されるため、非常に扱いづらいものでした。
そこでTensorFlow 2.0では、計算グラフの最適化処理で扱いやすい計算グラフとするため、1つのOperation「If」から構成するように、内部の実装を変更します。
ただし、本変更によりAPI tf.cond のシグネイチャが変わることはありません。
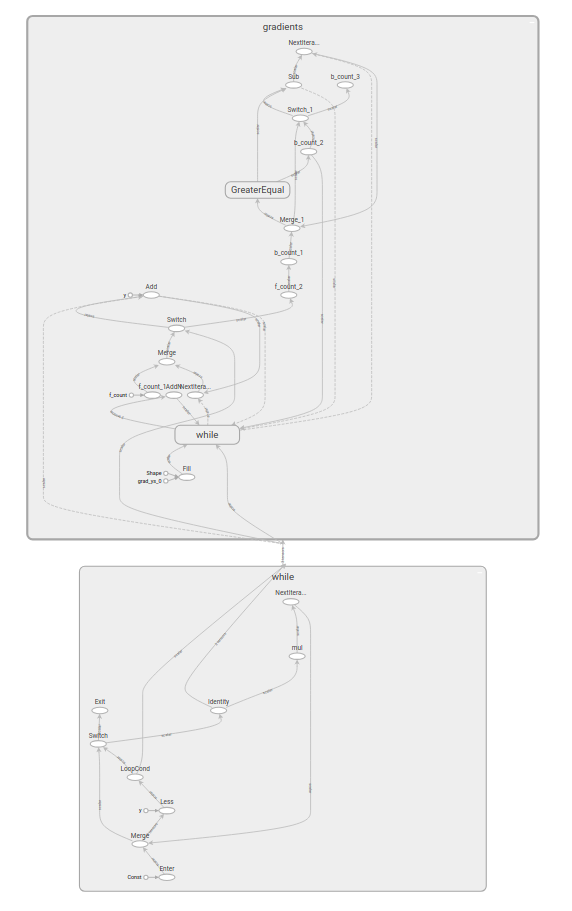
Functional while_loop (Design Document)
Functional cond の tf.while_loop 版です。
TensorFlow 1.xにおいてループ処理を実現するためには、API tf.while_loop を利用しますが、
tf.while_loop は6つのOperation(Switch、Merge、Enter、Exit、NextIteration、LoopCond)から構成されます。
TensorFlow 2.0では、計算グラフの最適化処理で扱いやすい計算グラフとするため、1つのOperation「While」から構成されるように、内部の実装を変更します。
内部実装の変更であるため、tf.cond と同様 tf.while_loop のシグネイチャが変わることはありません。
TensorFlow v1.x
TensorFlow v2.0
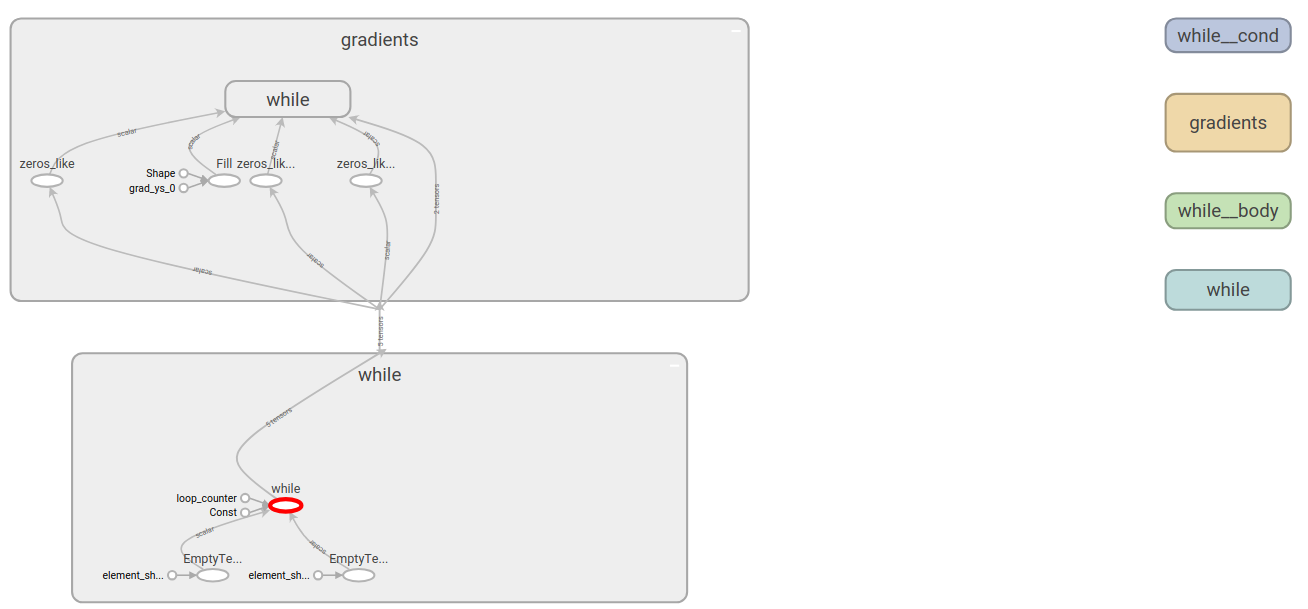
その他
TensorForest Estimator (Design Document)
ランダムフォレストのTensorFlow実装であるTensorForestが tf.contrib からコアに移動することを契機に、直感的かつメンテナンスしやすいようにAPIが修正されます。
また、Estimatorとの連携などを考慮したAPIとなるように修正されます。
Design Documentでは、回帰のためのランダムフォレストのAPIである TensorForestClassifier と分類のためのAPIである TensorForestReressor の2つが提供される予定です。
Design Documentでは、TensorForestClassifier と TensorForestRegressor の使い方の説明が書かれていますので、それぞれ紹介します。
なお、各APIの引数については、TensorForestClassifier については ここ を、TensorForestRegressor については、ここ を参照してください。
TensorForestClassifier
classifier = estimator.TensorForestClassifier(...)
classifier.train(input_fn=input_dataset_train)
classifier.predict(input_fn=input_dataset_predict)
metrics = classifier.evaluate(input_fn=input_dataset_eval)
TensorForestRegressor
regressor = estimator.TensorForestRegressor(...)
regressor.train(input_fn=input_dataset_train)
regressor.predict(input_fn=input_dataset_predict)
metrics = regressor.evaluate(input_fn=input_dataset_eval)
Generalizing tf.data batching using windowing and reducers (Design Document)
tf.data は、TensorFlowにおける入力パイプラインを構築するためのデファクトスタンダードになりつつあるAPI群です。
しかし、データセットからバッチを作る時に使用するAPI batch や padded_batch については、バッチを作るルールが少ないことから、柔軟性が低いことが指摘されています。
そこでTensorFlow 2.0では、バッチをより柔軟に作るために window と reduce の新たな2つのAPIが、tf.dataに追加される予定です。
以下では、新たに追加された tf.data.window と tf.data.reduce の使い方について示します。
tf.data.window
tf.data.window は、引数に指定された値をもとにスライディングウィンドウを作り、ウィンドウをスライドさせながら新たなデータセットを作成するAPIです。
tf.data.window は、以下のようなインタフェースになる予定です。
def window(size, shift=1, stride=1, drop_remainder=True)
各パラメータの説明するかわりに、ここでは具体的に tf.data.window を使った例を以下に示します。
具体的なパラメータの意味は、Design Document を参照してください。
tf.data.range(4).window(2) => {{0, 1}, {1, 2}, {2, 3}, {3, 4}}
tf.data.range(7).window(3, 2) => {{0, 1, 2}, {2, 3, 4}, {4, 5, 6}}
tf.data.range(4).window(1, 2, 2) => {{0, 2}, {1, 3}}
tf.data.reduce
tf.data.reduce は、データセットに対してReduce処理を容易に実現するために提供されるAPIです。
tf.data.reduce は、以下のようなインタフェースになる予定です。
def reduce(init_fn, reduce_fn)
引数 init_fn に初期値設定の関数、reduce_fn にデータセットの各要素を走査したときに呼び出される関数を指定します。
ここでは、データセットの要素数をカウントアップする例を示します。
具体的なパラメータの意味は、Design Document を参照してください。
# 初期値を設定する
def init_fn(_):
return 0
# データセットの各要素を走査した時にカウントアップする
def reduce_fn(state, value):
return state + 1
dataset = tf.data.Dataset.range(10)
value = dataset.reduce(init_fn, reduce_fn)
with tf.Session() as sess:
print(sess.run(value)) # データセットの要素数 = 10が出力される
TensorFlow Dockerfile Assembler (Design Document)
TensorFlowで提供されているdocker imageは、全てのユーザが利用するとは限らないパッケージなどが含まれるため、パッケージを利用しない人にとっては無駄にディスク容量を消費してしまうという問題がありました。
そこでTensorFlow 2.0では、複数の小さいDockerfileを組み合わせてdocker imageを作ることにより、必要なものだけがインストールされたdocker imageを作れるようになります。
なお、TensorFlow 1.xで採用されていた単一のDockerfileからdocker imageを作る方法は、Deprecatedになります。
TensorFlow Integration Testing (Design Document)
TensorFlow 1.xでは、tf.contrib を含めたすべてのソースコードがテスト対象となっていました。
しかしTensorFlow 2.0では、tf.contribの整理によってTensorFlowのモジュール化が進むため、TensorFlowの本体とモジュール化された部分の結合テストに支障がでてくると考えられます。
そこでTensorFlow 2.0では、Nightlyビルドのパッケージである tf-nightly パッケージの提供方式を見直し、この問題に対応します。
tf-nightly パッケージの具体的な提供方法については、「tf-nightly and tf-nightly-gpu renovations」の Design Document に書かれています。
- 従来の
tf-nightlyパッケージは、TensorFlowのmasterブランチのHEADを対象にしてビルドされていたため、全てのテストが通っていないパッケージが提供されることもあった - TensorFlow 2.0では、パッケージが提供されるその日の中でテストが通った最新のコミットをベースにビルドして
tf-nightlyパッケージを提供する- テストが通ったコミットが存在しない場合は、パッケージをビルドしない
- 対象とするプラットフォームごとにパッケージ提供の可否を判断することで、一部のプラットフォームでテストが通らないときに、他のプラットフォームでパッケージが提供されない事態を防ぐ
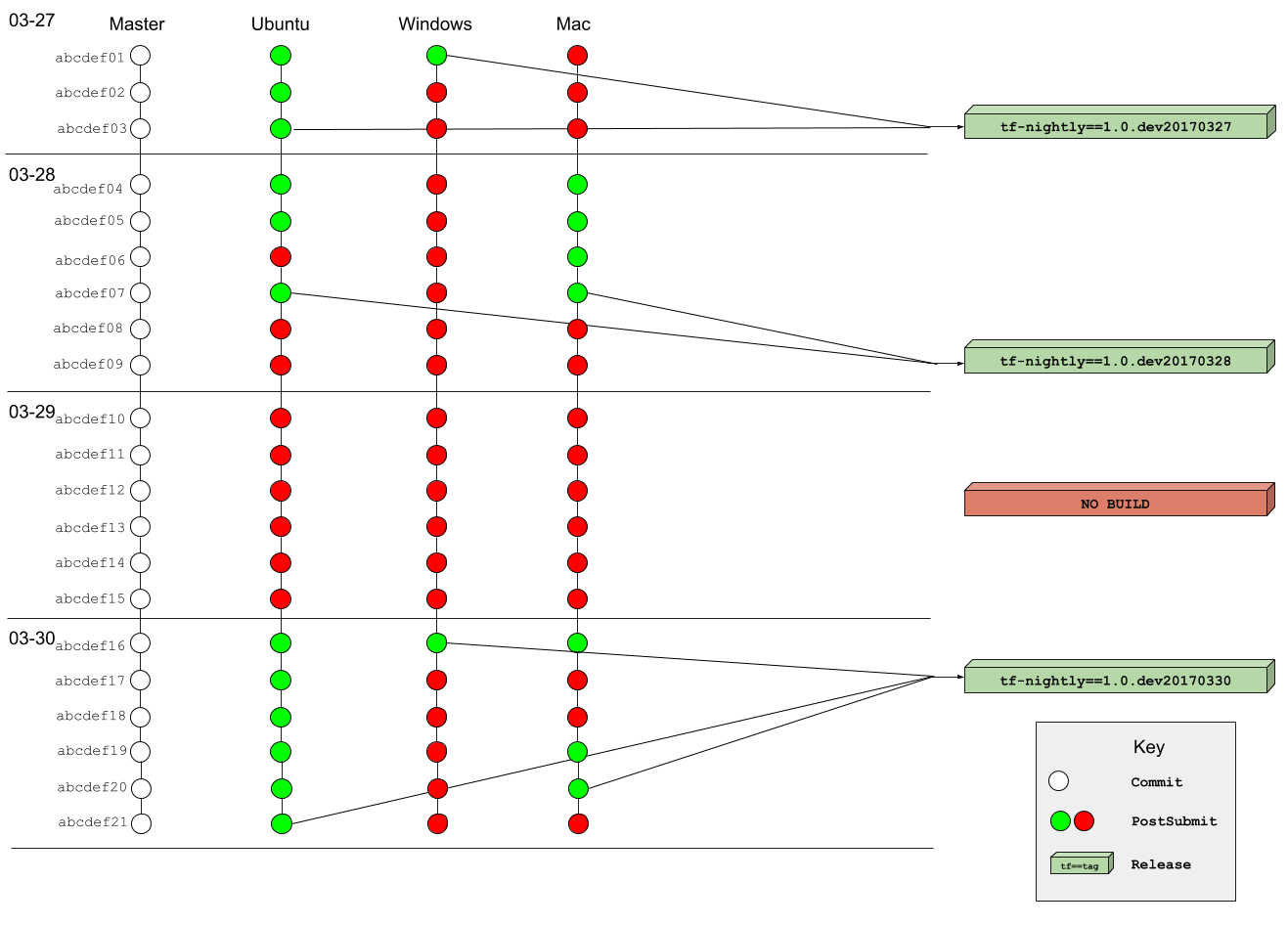
tf-nightly and tf-nightly-gpu renovations (Design Document)
内容は「TensorFlow Integration Testing」のDesignとして採用された案について、説明されています。
「TensorFlow Integration Testing」の項目を参照ください。
まとめ
ここまで、tensorflow/community にて公開されているDesign Documentから、TensorFlow 2.0の変更点をまとめてみました。
Design Documentではさまざまな変更が加えられていますが、TensorFlowチームからアナウンスされているように、やはりEager Modeのデフォルト化が一番大きな変更ではないでしょうか。
Eager Mode自体は、TensorFlow 1.5 から加わった機能でしたが、デフォルト化に伴ってこれまでGraph Modeを中心として作られていたチェックポイントなどの周辺機能は、Eager Modeが中心に考えられるようになってきています。
またTensorFlow 2.0では、大規模なソースコードの整理も行われます。
TensorFlowチームのアナウンスでは、1.xからの移行も考えられているようですが、APIのエンドポイントの変更、Addonリポジトリへの移動、削除などの大幅な変更により、TensorFlow 1.xを前提に作られていたプログラムを、そのままTensorFlow 2.0で動かすことは難しいと思われます。
TensorFlow 2.0がリリースされた後は、これまでTensorFlow 1.xを前提に作られていたプログラムの修正が必要になることはほぼ間違いないでしょう。
TensorFlow 1.xからの変更点は非常に多く、TensorFlowの内部実装に関わる身として変更に追従していくことは大変ですが、TensorFlow 2.0のリリースを楽しみにしながら待ちたいと思います。
-
計算グラフを作りながら演算を行う方式のことを指し、Defined-by-Runとも呼ばれます。 ↩
-
計算グラフを作った後に演算を行う方式のことを指し、Defined-and-Runとも呼ばれます。 ↩
-
TensorFlow 2.0からは、TensorFlowの拡張機能は別のリポジトリとして管理されます。TensorFlowのCommunityでは、「TensorFlow Special Interast Gropus (SIGs)」とも呼ばれています。 ↩
-
tf.contribが廃止されるTensorFlow 2.0において、今後もTensorFlowリポジトリに残るものをコアと呼びます。 ↩