AWS SageMakerとは
機械学習システムでよくある課題を解消し、データサイエンティストやエンジニアが素早くプロセスを回せるようにするためのサービス。
※今回はSageMakerの提供する機能のうち、開発→学習→推論の機能について記載する。
※(追記)本記事の内容は、下記でより詳細に記載しています。(PyTorch版ですが)
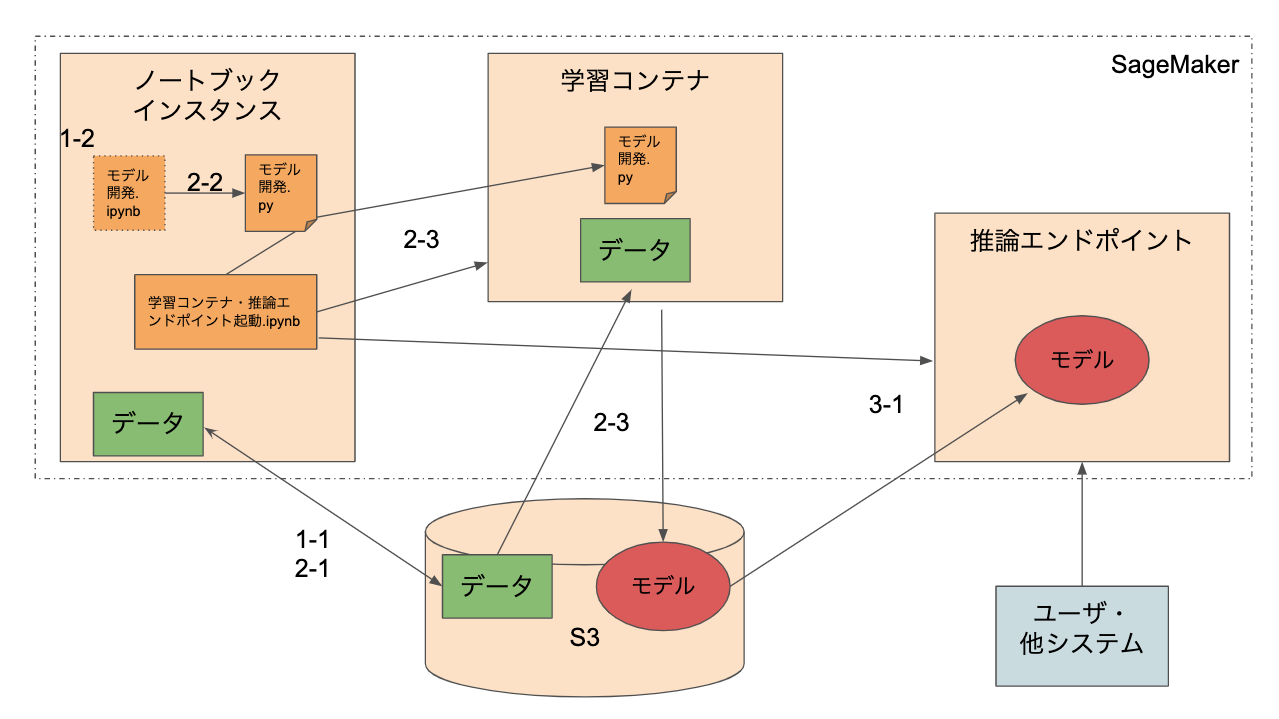
AWS SageMakerでの機械学習モデル開発フロー(PyTorch)構成図
-
SageMakerによる開発の流れ
- 1-1. データ準備(ノートブックインスタンス)
- S3等でrawデータを管理しておき、そのデータを開発用に一時的にダウンロード→加工する。
- 1-2. モデル開発
- ノートブックインスタンスにて、通常通りモデル開発する。
- 2-1. データ準備(S3)
- 1-1,2で加工したデータを、学習コンテナから読み込めるようにS3にアップロードする。
- 2-2. モデル定義スクリプトファイル化
- 1-2で開発したモデル定義を、学習コンテナから読み込めるようにスクリプト化する。
- 2-3. 学習コンテナ起動
- ノートブックインスタンスのノートから、学習コンテナを起動する。(2-1のデータ、2-2のモデル定義を利用して学習し、S3にモデルをアップロードする)
- 3-1. 推論エンドポイント起動
- ノートブックインスタンスのノートから、推論エンドポイントを起動する。(2-3のモデルをダウンロードして利用する)
- 1-1. データ準備(ノートブックインスタンス)
実装例(minimum)
1-1. データ準備(ノートブックインスタンス)
※今回はKaggleのコンペDogs vs. Catsのデータを利用する。(猫と犬の画像)
- S3でrawデータを管理する。(rawディレクトリを切る)
- ノートブックインスタンスのローカルにダウンロードする。
ターミナル
# S3からローカル(SageMakerインスタンス)にコピー
# ノートブックから先頭に!をつけて実行でも可
$ aws s3 cp s3://bucket-sagemaker01/data/dogscats/raw/train/ ./data/dogscats/local/train --recursive
$ aws s3 cp s3://bucket-sagemaker01/data/dogscats/raw/test/ ./data/dogscats/local/test --recursive
- データを加工する。(※SageMaker独自ではない部分)
dogscats_code_model.ipynb(1)
import os
import numpy as np
from PIL import Image
TRAIN_DIR = "./data/dogscats/local/train/"
TEST_DIR = "./data/dogscats/local/test/"
ROWS = 64
COLS = 64
CHANNELS = 3
# os.listdir(ディレクトリ名):ディレクトリのファイル名一覧を取得
train_images = [TRAIN_DIR+i for i in os.listdir(TRAIN_DIR)]
train_dogs = [TRAIN_DIR+i for i in os.listdir(TRAIN_DIR) if 'dog' in i]
train_cats = [TRAIN_DIR+i for i in os.listdir(TRAIN_DIR) if 'cat' in i]
test_images = [TEST_DIR+i for i in os.listdir(TEST_DIR)]
# 画像ファイルをnumpyの配列に変換する
def prep_data(images):
count = len(images)
# 初期化
data = np.ndarray((count, CHANNELS, ROWS, COLS), dtype=np.uint8)
# enumerate:番号をつけていく
for i, image_file in enumerate(images):
image = Image.open(image_file)
image = image.convert("RGB")
image = image.resize((ROWS, COLS))
image = np.array(image)
data[i] = image.T #transpose mxn > nxm
# 250に1回,途中経過を表示する
if i%250 == 0: print('Processed {} of {}'.format(i, count))
return data
train = prep_data(train_images)
test = prep_data(test_images)
# ラベル付け
labels = []
for i in train_images:
if 'dog.' in i:
labels.append(1)
else:
labels.append(0)
1-2. モデル開発
- ノートブックインスタンスにて、通常通りモデル開発する。(※SageMaker独自ではない部分)
dogscats_code_model.ipynb(2)
from keras.models import Sequential
from keras.layers import Input, Dropout, Flatten, Conv2D, MaxPooling2D, Dense, Activation
from keras.optimizers import RMSprop
from keras.callbacks import ModelCheckpoint, Callback, EarlyStopping
from keras.utils import np_utils
# RMSprop:勾配降下法の一つ
optimizer = RMSprop(lr=1e-4)
# どれくらい正解と離れているか
objective = 'binary_crossentropy'
# モデルを返り値に持つ関数
def catdog():
model = Sequential()
model.add(Conv2D(32, (3, 3), padding='same', input_shape=(3, ROWS, COLS), activation='relu'))
model.add(Conv2D(32, (3, 3), padding='same', activation='relu'))
model.add(MaxPooling2D(data_format="channels_first", pool_size=(2, 2)))
model.add(Conv2D(64, (3, 3), padding='same', activation='relu'))
model.add(Conv2D(64, (3, 3), padding='same', activation='relu'))
model.add(MaxPooling2D(data_format="channels_first", pool_size=(2, 2)))
model.add(Conv2D(128, (3, 3), padding='same', activation='relu'))
model.add(Conv2D(128, (3, 3), padding='same', activation='relu'))
model.add(MaxPooling2D(data_format="channels_first", pool_size=(2, 2)))
model.add(Conv2D(256, (3, 3), padding='same', activation='relu'))
model.add(Conv2D(256, (3, 3), padding='same', activation='relu'))
# 色の情報を持っていることを伝える
model.add(MaxPooling2D(data_format="channels_first", pool_size=(2, 2)))
# これまでの出力を一直線に並べる
model.add(Flatten())
model.add(Dense(256, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(256, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(1))
model.add(Activation('sigmoid'))
model.compile(loss=objective, optimizer=optimizer, metrics=['accuracy'])
return model
model = catdog()
# 大きくすると学習が早くすすむ
# 収束しない場合は増やす
# 過学習の場合は減らす
nb_epoch = 3
batch_size = 1
# 途中の損失について記録しておく
class LossHistory(Callback):
def on_train_begin(self, logs={}):
# トレーニングの最初に初期化する
self.losses = []
self.val_losses = []
def on_epoch_end(self, batch, logs={}):
self.losses.append(logs.get('loss'))
self.val_losses.append(logs.get('val_loss'))
# monitor: 監視対象
# patience: 訓練が停止し,値が改善しなくなってからのエポック数.
# val_lossを監視して,一定のロスに達したら学習を停止する
early_stopping = EarlyStopping(monitor='val_loss', patience=3, verbose=1, mode='auto')
history = LossHistory()
# 固定のエポック数でモデルを訓練する
# 最適化の処理を呼び出す -> モデルのパラメータが更新される
# validation_split:25%は検証に回す(テストとは違う)
model.fit(train, labels, batch_size=batch_size, epochs=nb_epoch,
validation_split=0.25, verbose=0, shuffle=True, callbacks=[history, early_stopping])
# Debug
%matplotlib inline
import matplotlib.pyplot as plt
loss = history.losses
val_loss = history.val_losses
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.title('CatdogNet Loss Trend')
plt.plot(loss, 'blue', label='Training Loss')
plt.plot(val_loss, 'green', label='Validation Loss')
plt.xticks(range(0,nb_epoch)[0::2])
plt.legend()
plt.show()
predictions = model.predict(test, verbose=0)
# Debug
for i in range(0,10):
if predictions[i, 0] >= 0.5:
print('I am {:.2%} sure this is a Dog'.format(predictions[i][0]))
else:
print('I am {:.2%} sure this is a Cat'.format(1-predictions[i][0]))
plt.imshow(test[i].T)
plt.show()
2-1. データ準備(S3)
- 1-1,2で加工したデータを、学習コンテナから読み込めるようにS3にアップロードする。
- 後から一意に特定(検索)できるようにする
- 例)processed-201902101530
- 後から一意に特定(検索)できるようにする
ターミナル
# S3からローカル(SageMakerインスタンス)にコピー
# ノートブックから先頭に!をつけて実行でも可
$ aws s3 cp ./data/dogscats/local/train s3://bucket-sagemaker01/data/dogscats/processed-201902101530/train/ --recursive
$ aws s3 cp ./data/dogscats/local/test s3://bucket-sagemaker01/data/dogscats/processed-201902101530/test/ --recursive
2-2. モデル定義スクリプトファイル化
- 1-2で開発したモデル定義を、学習コンテナから読み込めるようにスクリプト化する。
- インプット(引数の受け取り方)とアウトプット(モデルのsave)部分を修正する。
- モデルの定義を変えるごとにスクリプトファイルを分ける。
- 後から一意に特定(検索)できるようにする
- 例)dogscats_201902101600.py
- 後から一意に特定(検索)できるようにする
- kerasは、tensorflow.python.kerasを使うこと
dogscats_201902101600.py
import os, random
import numpy as np
from PIL import Image
from tensorflow.python.keras.models import Sequential
from tensorflow.python.keras.layers import Input, Dropout, Flatten, Conv2D, MaxPooling2D, Dense, Activation
from tensorflow.python.keras.optimizers import RMSprop
from tensorflow.python.keras.callbacks import ModelCheckpoint, Callback, EarlyStopping
from tensorflow.python.keras.utils import np_utils
# 追加でインポート
import argparse
from tensorflow.python.keras import backend as K
# coding under this function
if __name__ == '__main__':
# input for sagemaker
##########
parser = argparse.ArgumentParser()
parser.add_argument('--epochs', type=int, default=10)
parser.add_argument('--batch-size', type=int, default=100)
parser.add_argument('--learning_rate', type=float, default=0.01)
parser.add_argument('--num-classes', type=int, default=10)
parser.add_argument('--model-dir', type=str, default=os.environ['SM_MODEL_DIR'])
parser.add_argument('--train-dir', type=str, default=os.environ['SM_CHANNEL_TRAIN'])
parser.add_argument('--valid-dir', type=str, default=os.environ['SM_CHANNEL_VALID'])
parser.add_argument('--output-dir', type=str, default=os.environ['SM_OUTPUT_DATA_DIR'])
args, _ = parser.parse_known_args()
nb_epoch = args.epochs
batch_size = args.batch_size
learning_rate = args.learning_rate
TRAIN_DIR = args.train_dir
TEST_DIR = args.valid_dir
##########
ROWS = 64
COLS = 64
CHANNELS = 3
train_images = []
for x in os.listdir(TRAIN_DIR):
train_images.append(TRAIN_DIR + "/" + x)
test_images = []
for x in os.listdir(TEST_DIR):
test_images.append(TEST_DIR + "/" + x)
# under here, same as local
# 画像ファイルをnumpyの配列に変換する
def prep_data(images):
count = len(images)
# 初期化
data = np.ndarray((count, CHANNELS, ROWS, COLS), dtype=np.uint8)
# enumerate:番号をつけていく
for i, image_file in enumerate(images):
image = Image.open(image_file)
image = image.convert("RGB")
image = image.resize((ROWS, COLS))
image = np.array(image)
data[i] = image.T #transpose mxn > nxm
# 250に1回,途中経過を表示する
if i%250 == 0: print('Processed {} of {}'.format(i, count))
return data
train = prep_data(train_images)
test = prep_data(test_images)
# ラベル付け
labels = []
for i in train_images:
if 'dog.' in i:
labels.append(1)
else:
labels.append(0)
# RMSprop:勾配降下法の一つ
optimizer = RMSprop(lr=learning_rate)
# どれくらい正解と離れているか
objective = 'binary_crossentropy'
# モデルを返り値に持つ関数
def catdog():
model = Sequential()
model.add(Conv2D(32, (3, 3), padding='same', input_shape=(3, ROWS, COLS), activation='relu'))
model.add(Conv2D(32, (3, 3), padding='same', activation='relu'))
model.add(MaxPooling2D(data_format="channels_first", pool_size=(2, 2)))
model.add(Conv2D(64, (3, 3), padding='same', activation='relu'))
model.add(Conv2D(64, (3, 3), padding='same', activation='relu'))
model.add(MaxPooling2D(data_format="channels_first", pool_size=(2, 2)))
model.add(Conv2D(128, (3, 3), padding='same', activation='relu'))
model.add(Conv2D(128, (3, 3), padding='same', activation='relu'))
model.add(MaxPooling2D(data_format="channels_first", pool_size=(2, 2)))
model.add(Conv2D(256, (3, 3), padding='same', activation='relu'))
model.add(Conv2D(256, (3, 3), padding='same', activation='relu'))
# 色の情報を持っていることを伝える
model.add(MaxPooling2D(data_format="channels_first", pool_size=(2, 2)))
# これまでの出力を一直線に並べる
model.add(Flatten())
model.add(Dense(256, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(256, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(1))
model.add(Activation('sigmoid'))
model.compile(loss=objective, optimizer=optimizer, metrics=['accuracy'])
return model
model = catdog()
# 途中の損失について記録しておく
class LossHistory(Callback):
def on_train_begin(self, logs={}):
# トレーニングの最初に初期化する
self.losses = []
self.val_losses = []
def on_epoch_end(self, batch, logs={}):
self.losses.append(logs.get('loss'))
self.val_losses.append(logs.get('val_loss'))
# monitor: 監視対象
# patience: 訓練が停止し,値が改善しなくなってからのエポック数.
# val_lossを監視して,一定のロスに達したら学習を停止する
early_stopping = EarlyStopping(monitor='val_loss', patience=3, verbose=1, mode='auto')
history = LossHistory()
# 固定のエポック数でモデルを訓練する
# 最適化の処理を呼び出す -> モデルのパラメータが更新される
# validation_split:25%は検証に回す(テストとは違う)
model.fit(train, labels, batch_size=batch_size, epochs=nb_epoch,
validation_split=0.25, verbose=0, shuffle=True, callbacks=[history, early_stopping])
predictions = model.predict(test, verbose=0)
# output for sagemaker
##########
sess = K.get_session()
tf.saved_model.simple_save(
sess,
os.path.join(args.model_dir, 'export/Servo/1/'),
inputs={'inputs': model.input},
outputs={t.name: t for t in model.outputs})
##########
2-3. 学習コンテナ起動
- ノートブックインスタンスのノートから、学習コンテナを起動する。(2-1のデータ、2-2のモデル定義を利用して学習し、S3にモデルをアップロードする)
- job_nameに'_'は使えないので注意。
dogscats_train_deploy_model.ipynb
# 学習
from sagemaker import Session, get_execution_role
from sagemaker.tensorflow import TensorFlow
import sagemaker
from datetime import datetime, timedelta, timezone
sagemaker_session = Session()
sagemaker_role = get_execution_role()
data_path = 's3://bucket-sagemaker01/data/dogscats/'
hyper_param = {
'epochs': 3,
'batch_size':1,
'learning_rate': 1e-4,
'num_classes': 2,
}
estimator = TensorFlow(
hyperparameters=hyper_param,
script_mode=True,
entry_point='dogscats_201902101600.py',
role=sagemaker_role,
train_instance_count=1,
train_instance_type='ml.m4.xlarge',
py_version='py3',
framework_version='1.11.0',
)
JST = timezone(timedelta(hours=+9), 'JST')
date = datetime.now(JST).strftime("%Y%m%d%H%M")
# モデルを訓練する
estimator.fit(
inputs = {'train':data_path+'train', 'valid':data_path+'test'},
job_name='dogscats-201902101600' + '-' + 'processed-20190310' + '-' + date,
)
3-1. 推論エンドポイント起動
- ノートブックインスタンスのノートから、推論エンドポイントを起動する。(2-3のモデルをダウンロードして利用する)
dogscats_train_deploy_model.ipynb
# デプロイ
predictor = estimator.deploy(initial_instance_count=1, instance_type='ml.p2.xlarge')
実装例(optional)
- ハイパーパラメータチューニング
- 学習コンテナが複数立ち上がり、最適なパラメータを探索する
dogscats_train_deploy_model.ipynb
from sagemaker.tuner import IntegerParameter, CategoricalParameter, ContinuousParameter, HyperparameterTuner
objective_metric_name = 'valid:loss'
objective_type = 'Minimize'
hyperparameter_ranges = {
'batch_size': IntegerParameter(16, 128),
'learning_rate': ContinuousParameter(1e-4, 0.2)
}
tuner = HyperparameterTuner(estimator,
objective_metric_name,
hyperparameter_ranges,
metric_definitions,
max_jobs=10,
max_parallel_jobs=1,
objective_type=objective_type,
early_stopping_type='Auto'
)
# !pip install shortuuid
import shortuuid
uuid = shortuuid.ShortUUID().random(length=5)
tuner.fit(
inputs = {'train':data_path+'train', 'valid':data_path+'test'},
job_name='alexnet-origin' + '-' + uuid
)
補足
-
Amazon SageMakerでの開発は3パターンある
- Amazon SageMakerが提供するコンテナで組み込みアルゴリズムの利用
- Amazon SageMakerが提供するコンテナで独自のアルゴリズムの利用
- 今回紹介したパターン
- デフォルトではkerasではなく、tensorflow.kerasを利用しなければならない
- パッケージを追加したいときはdependenciesを利用する
- 独自のコンテナで独自のアルゴリズムの利用
-
Amazon SageMaker Search
- Amazon SageMakerでの学習ジョブを様々な条件で素早く簡単に整理、追跡、評価することができる機能
- データ(S3パス)、モデル定義(スクリプトファイル名)、メトリクス(acc,loss,etc)、等