RubyでK-means法でクラスタ分析してみた
K-means法とは
下記のサイトが分かりやすくアルゴリズムを解説しています。
コード
require 'set'
# クラスタをランダムに割り振る
def random_clusterize data, cluster_num
data_num = data.size
clusters = []
cluster_num.times do |i|
_start = (i*data_num/cluster_num).to_i
_end = (i!=cluster_num-1) ? ((i+1)*data_num/cluster_num).to_i : data_num
clusters[i] = data[_start..._end]
end
clusters
end
# クラスタの中心座標を取得
def get_center_point cluster
result = [0.0, 0.0]
cluster_size = cluster.size.to_f
cluster.each do |point|
result[0] += point[0]
result[1] += point[1]
end
result[0] /= cluster_size
result[1] /= cluster_size
result
end
# 点の距離を取得
def distance point1, point2
(point1[0]-point2[0])**2 + (point1[1]-point2[1])**2
end
# dataをcluster_numにクラスタライズ
def clusterize data, cluster_num
center_points = []
# ランダムに分割
data.shuffle!
clusters = random_clusterize data, cluster_num
# 仮中心を作る
clusters.each_with_index do |cluster,i|
center_points[i] = get_center_point cluster
end
# 終わるまでループ
while(true) do
tmp_clusters = []
cluster_num.times do |cluster_index|
tmp_clusters[cluster_index] = []
end
data.each do |datum|
tmp_min_distances = Float::INFINITY
minimum_index = 0
center_points.each_with_index do |center_point, center_point_index|
# 重心との距離を計算
dist = distance(center_point, datum)
if distance(center_point, datum) < tmp_min_distances
tmp_min_distances = dist
minimum_index = center_point_index
end
end
# 近い重心を判断
tmp_clusters[minimum_index] << datum
end
# 仮中心を決定
cluster_num.times do |index|
center_points[index] = get_center_point tmp_clusters[index]
end
# クラスタの決定
if tmp_clusters.to_set == clusters.to_set
break
end
clusters = tmp_clusters
end
# クラスタを返却
clusters
end
使い方
require 'csv'
# さっきのコード...
# 3つのクラスタに分類
cluster_num = 3
# 元データを読み込む
data = CSV.read("test.csv").map do |datum|
[datum[0].to_f, datum[1].to_f]
end
# クラスタリング
clusters = clusterize data, cluster_num
# クラスタ後のデータごとにcsvとして吐き出す
cluster_num.times do |i|
CSV.open("myfile#{i}.csv", "w") do |csv|
clusters[i].each do |row|
csv << row
end
end
end
動かしてみた
元データを以下のようにある程度クラスタが見える程度に配置して作ってみました。
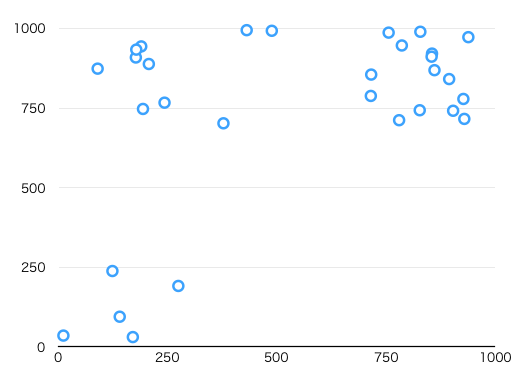
これをCSVデータとして、さっきのコードに読み込ませてクラスタ毎に色分けして出力しました。
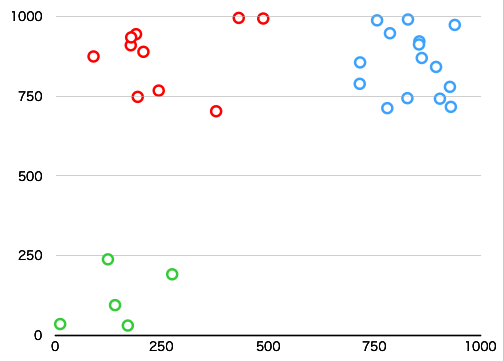
ちゃんとクラスタに分かれてることが分かります!!
まとめ
今回は2次元にしましたが、ちょっと変えれば、n次元のクラスタ分析もできます!
何か、大きいデータを分類しなきゃいけないなどがあれば、是非、お試しください。