Invertible Grayscaleという論文を読んだので、ざっくりと実装した。
Menghan Xia and Xueting Liu and Tien-Tsin Wong, Invertible Grayscale,SIGGRAPH ASIA 2018
自分が行った実験以外の画像はすべて論文からの引用です。
Invertible Grayscale

概要
カラー画像は一度グレースケールにしてしまえば元のカラー画像は復元できません。そこで、この論文ではタイトルの通り、カラー画像が復元できるグレースケール画像を生成する方法を提案しています。とは言っても、万能なわけではなく専用のエンコーダ・デコーダが必要です。
提案手法
手法は至ってシンプルで、上記で述べたとおり専用のエンコーダ・デコーダをCNNを用いて学習します。エンコーダネットワークはカラー画像をグレースケールに変換し、デコーダネットワークはエンコーダネットワークによって生成されたグレースケール画像をカラー画像に変換します。
損失関数
適切な損失関数を設計することで可逆なグレースケールを生成しています。エンコーダを$E$、デコーダを$D$、入力するカラー画像を$I$、出力となるグレースケールを$G$、グレースケールから再構成したカラー画像を$R$とします。そうすると
$$
G = E(I)
$$
$$R = D(G) = D(E(I))$$
という関係が成り立ちます。
提案されている損失関数${\cal L}(E, D)$は
{\cal L}(E, D) = {\cal L}_{V}(E, D) + \omega_{1}{\cal L}_C(E) + \omega_{2}{\cal L}_Q(E)
となります。
右辺第一項目からそれぞれ、Invertibility Loss、 Grayscale Conformity Loss、Quantization Lossとなります。
Invertibility Loss
これは元のカラー画像$I$と復元後のカラー画像$R$が似るようにするためのもので、まさに$R = D(G) = D(E(I))$の式の意味です。単純に$I$と$R$のピクセル毎の平均二乗誤差となります。$|| \cdot ||_2$はL2ノルム(MSE)、${\cal I}$はデータセットです。
{\cal L}_V(E, D) = {\mathbb{E}}_{I \in \cal I}\{{||R-I||_2}\}
Grayscale Conformity Loss
個人的にこれが一番重要な損失関数で、エンコーダによって生成される画像をグレースケールにするためのものです。Grayscale Conformity Lossは更に3つの損失関数構成されます。
L_C (E) = \ell_l (E) + \alpha \ell_c (E) + \beta \ell_s (E)
右辺第一項目からそれぞれ、Lightness Loss、Contrast Loss、Local Structure Lossとなります。これらについてもそれぞれ見ていきます。なお、$\alpha$と$\beta$は$\alpha = 10 {\rm e}-7$、$\beta=0.5$となっています。
Lightness Loss
生成されるグレースケールの輝度値が元のカラー画像と同じになることを保証するためのものです。もとのカラー画像が明るいところはグレースケールでも明るく、暗いところは暗くなるようにします。
{\ell}_l(E) ={\mathbb{E}}_{I \in \cal I}\{{||max{|G −L(I)| − M_{\theta},M_0}||_1}\}
$ || { \cdot } ||_1 $はL1ノルムです。輝度値の差が$M_{\theta} $以下に抑えられるようになっています。$M_0$は画像と同じサイズの零行列です。つまり、この損失関数は輝度値の差が$M_{\theta}$以上あれば誤差とみなされるということです。単純に、二乗誤差を取らないのはカラー画像の情報を埋め込む余裕を作るためです。なお論文では$\theta=70$となっていて、かなりの余裕をもたせています。
Contrast Loss
元のカラー画像$I$とグレースケール画像$G$のコントラストを保存するためのものです。学習済みのVGGを使用します。
\ell_c (E) = {\mathbb{E}}_{I \in \cal I}\{||VGG_k(G) - VGG_k(I_c)||_1\}
Perceptual Lossと言われるやつです。$k$は使用するVGGのレイヤーでconv4_4を使用します。$c$はカラーチャンネルです。
Local Structure Loss
元のカラー画像の局所的な構造をグレースケール画像で保存するためのものです。カラー画像中で滑らかな部分はグレースケールでも滑らかになっていてほしいです。こういった局所的な構造をカラー画像と比較するためにLocal Variationを用います。
\ell_s (E) = {\mathbb{E}}_{I \in \cal I}\{\|Var(G) - Var(I_c)\|_1\}
$Var(\cdot)$はLocal Variationの平均値を表します。
これらの損失関数の有無によるグレースケール画像の違いです。

言ってしまえば、グレースケールに見えれば多少正確でなくても良いってことです。
Quantization Loss
実際の画像は8bitですが、グレースケールや復元後のカラー画像は32bitの浮動小数点になっており、これは量子化時にアーティファクトを生むそうです。Quantization Lossはそれを抑えるためのものです。
{\cal L}_Q (E) = {\mathbb{E}}_{I \in \cal I}\langle\|\min_{d=0}^{255}\{\left|G - M_d\right|\}\|_1\rangle
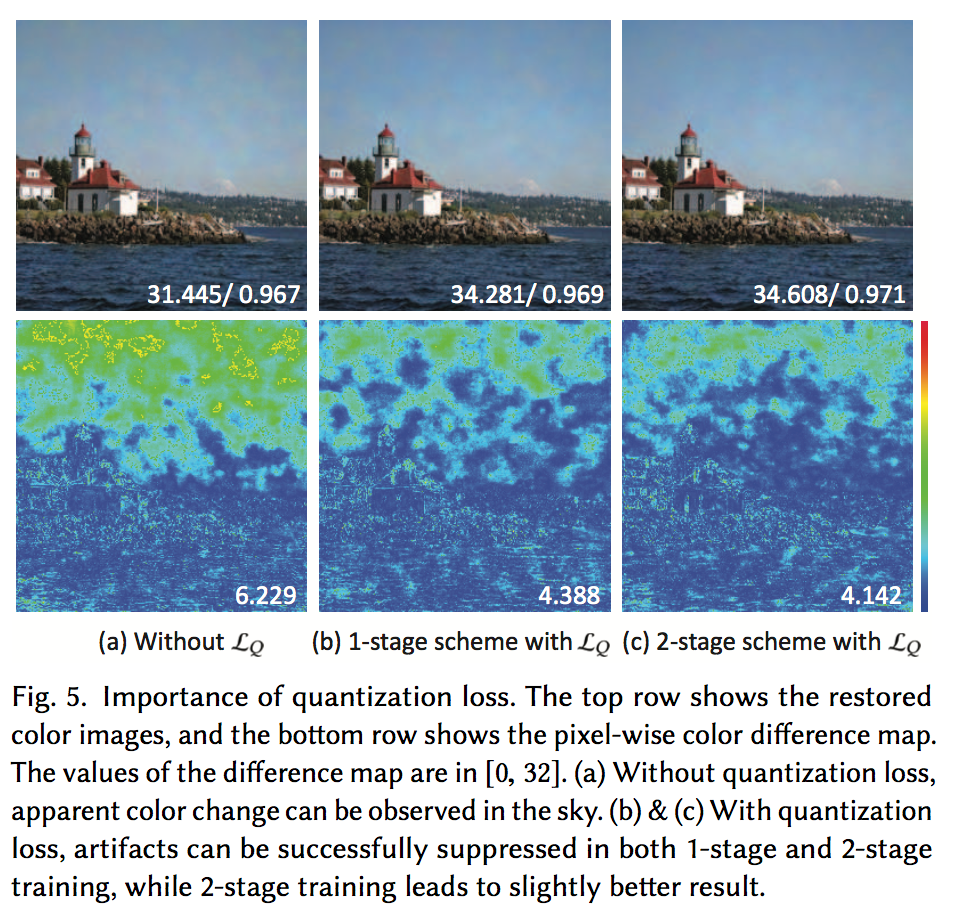
$\min { \cdot }$は要素毎の最小値という意味です。つまり、生成されたグレースケールと、それを整数値にしたときの差が誤差になるということです。
以上がInvertible grayscale に必要な誤差関数です。
学習
使用したデータセットはVOC2012。また、学習は2ステージに分けて行っています。別に分ける必要はないのですが、分けたほうが時間が短く、かつ誤差がより減ったそうです。また、Quantization Lossがメモリを多く使用するとのことですが、実装の問題の気がしています(自分がQuantization Lossを勘違いしているかもしれません)。
ステージ毎に損失関数の重みが違います。
| Stage | $\omega_1$ | $\omega_2$ | Epochs |
|---|---|---|---|
| Ⅰ | 1.0 | 0.0 | 90 |
| Ⅱ | 0.5 | 10.0 | 30 |
$\alpha$と$\beta$は学習全体を通して変更しません。最適化アルゴリズムはAdamで初期学習率は0.0002、120epochを通して0.000002まで減らしていきます。
評価
vs Colorization
SOTAのCNN着色手法との比較です。確かに、しっかりと復元できていますが、正直当然の結果という気がします。
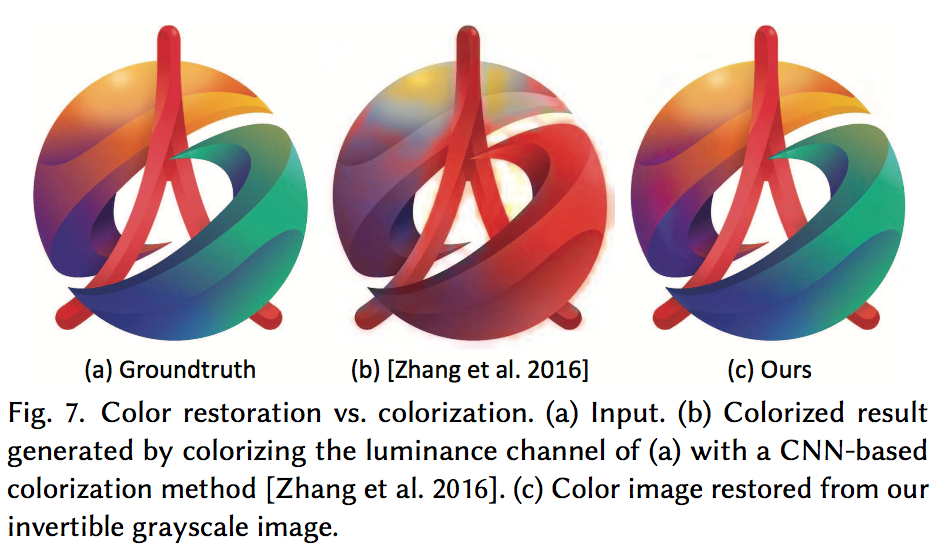
論文にはその他に、PSNRといった一般的な評価指標や、ユーザスタディーによる評価もあります。
制限
この手法は独自のパターンでカラー画像に変換できるグレースケールに落とし込んでいるため、カラー画像への再変換の制度はグレースケールが正確に独自のパターンを再現している必要があります。そのため、回転やJPEG圧縮などをするとこの独自パターンが崩れ、カラー画像を再現できません。まあ、当然といえば当然ですね。

少し面白いのが、カラー画像をエンコーダでグレースケールに変換後、それを紙にプリントして写真に撮り、デコーダを用いてカラー画像に変換してもそこそこ元に戻せたことです。写真で撮るときに光などのノイズ乗るにもかかわらず思ったより色が正確ですね。

実験
chainerで実装して学習をしてみました。なお、著者の実装はこちらです。
損失関数が少し面倒でしたが、実装は簡単でした。Quantization Lossが少々不安ですが。初期値依存がかなり激しく、多少探索する必要がありました。

画像はランダムに選びました。正直微妙なのが選択された気がします。一番左の馬の画像を見るとそこそこうまくいっているようのに見えますが、自転車の画像を見ると青色の精度が良くないのがわかります。もしかしたら学習不足、実装のミスなどがあるかもしれません。一応ネットワークと損失関数部分のコードを貼っておきます。入力はカラー画像とグレースケールです。chainerのextensionsを用いて90epochでstage_twoをTrueにします。
import numpy as np
import chainer
from chainer import functions as F, links as L, Variable as V
from chainer.backends import cuda
class Block(chainer.Chain):
def __init__(self, out_ch):
super(Block, self).__init__()
with self.init_scope():
self.conv1 = L.Convolution2D(None, out_ch, 3, pad=1)
self.conv2 = L.Convolution2D(None, out_ch, 3, pad=1)
def __call__(self, x):
h = F.relu(self.conv1(x))
h = self.conv2(h)
return h + x
class IGEncoder(chainer.Chain):
def __init__(self):
super(IGEncoder, self).__init__()
with self.init_scope():
self.conv1 = L.Convolution2D(None, 64, 3, pad=1)
self.block2 = Block(64)
self.block3 = Block(64)
self.conv4 = L.Convolution2D(None, 128, 3, stride=2, pad=1)
self.conv5 = L.Convolution2D(None, 128, 3, stride=1, pad=1)
self.conv6 = L.Convolution2D(None, 256, 3, stride=2, pad=1)
self.conv7 = L.Convolution2D(None, 256, 3, stride=1, pad=1)
self.block8 = Block(256)
self.block9 = Block(256)
self.block10 = Block(256)
self.block11 = Block(256)
self.block12 = Block(256)
self.block13 = Block(256)
self.conv14 = L.Convolution2D(None, 128, 3, stride=1, pad=1)
self.conv14_2 = L.Convolution2D(None, 128, 3, stride=1, pad=1)
self.conv15 = L.Convolution2D(None, 64, 3, stride=1, pad=1)
self.conv15_2 = L.Convolution2D(None, 64, 3, stride=1, pad=1)
self.block16 = Block(64)
self.block17 = Block(64)
self.conv18 = L.Convolution2D(None, 1, 3, stride=1, pad=1)
def __call__(self, x):
h = self.conv1(x)
h = self.block2(h)
h1 = self.block3(h)
h = self.conv4(h1)
h2 = F.relu(self.conv5(h))
h = self.conv6(h2)
h = F.relu(self.conv7(h))
h = self.block8(h)
h = self.block9(h)
h = self.block10(h)
h = self.block11(h)
h = F.resize_images(h, h2.shape[2:])
h = self.conv14(h)
h = F.relu(self.conv14_2(h)) + h2
h = F.resize_images(h, h1.shape[2:])
h = self.conv15(h)
h = F.relu(self.conv15_2(h)) + h1
h = self.block16(h)
h = self.block17(h)
h = F.tanh(self.conv18(h))
return h
class IGDecoder(chainer.Chain):
def __init__(self):
super(IGDecoder, self).__init__()
with self.init_scope():
self.conv = L.Convolution2D(None, 64, 3, pad=1)
for i in range(8):
setattr(self, f"block{i}", Block(64))
self.conv8 = L.Convolution2D(None, 256, 3, pad=1)
self.conv8_2 = L.Convolution2D(None, 3, 1)
def __call__(self, x):
h = self.conv(x)
for i in range(8):
h = getattr(self, f"block{i}")(h)
h = self.conv8(h)
h = F.tanh(self.conv8_2(h))
return h
class InvertibleGray(chainer.Chain):
def __init__(self):
super(InvertibleGray, self).__init__()
self.alpha = 1e-7
self.beta = 0.5
self.stage_two = False
with self.init_scope():
self.encoder = IGEncoder()
self.decoder = IGDecoder()
self.vgg = L.VGG19Layers()
self.wh = self.xp.array([[[[1], [-1]]]], dtype="f")
self.ww = self.xp.array([[[[1, -1]]]], dtype="f")
self.mean = np.array([103.939, 116.779, 123.68], dtype="f").reshape(1, 3, 1, 1)
def to_gpu(self, device=None):
super(InvertibleGray, self).to_gpu(device)
with cuda._get_device(device):
self.vgg = L.VGG19Layers().to_gpu()
self.wh = self.xp.array([[[[1], [-1]]]], dtype="f")
self.ww = self.xp.array([[[[1, -1]]]], dtype="f")
self.mean = cuda.to_gpu(self.mean)
return self
def __call__(self, x):
# x = [color_img, gray_img]
t_color, t_gray = x
y_gray = self.encoder(t_color)
y_color = self.decoder(y_gray)
invertible_loss = F.mean_squared_error(y_color, t_color)
lightness_loss = self.calc_lightness_loss(y_gray, t_gray)
contrast_loss = self.calc_contrast_loss(y_gray, t_color)
local_structure_loss = self.calc_local_structure_loss(y_gray, t_gray)
combind_loss = local_structure_loss + contrast_loss * self.alpha + lightness_loss * self.beta
report = {
"invertible": invertible_loss,
"lightness": lightness_loss,
"contrast": contrast_loss,
"local_structure": local_structure_loss,
}
if not self.stage_two:
loss = invertible_loss * 3 + combind_loss
else:
quantization_loss = self.calc_quantization_loss(y_gray)
report["quantization"] = quantization_loss
loss = invertible_loss * 3 + combind_loss * 0.5 + quantization_loss * 10
chainer.report(report, self)
return loss
def calc_lightness_loss(self, x, gray):
diff = F.absolute_error((x + 1) / 2, (gray + 1) / 2)
loss = F.mean(F.maximum(diff - 70/127, self.xp.zeros(x.shape).astype("f")))
return loss
def calc_contrast_loss(self, x, t):
y_rgb = F.broadcast_to(x, (len(x), 3, x.shape[2], x.shape[3]))
y_conv4_feature = self.vgg((y_rgb + 1) / 2 * 255 - self.mean, ["conv4_4"])["conv4_4"]
t_rgb = t
t_conv4_feature = self.vgg((t_rgb + 1) / 2 * 255 - self.mean, ["conv4_4"])["conv4_4"]
loss = F.mean_absolute_error(y_conv4_feature, t_conv4_feature)
return loss
def calc_local_structure_loss(self, x, t):
tv_loss_h = F.mean_absolute_error(F.depthwise_convolution_2d(x, self.wh), F.depthwise_convolution_2d(t, self.wh))
tv_loss_w = F.mean_absolute_error(F.depthwise_convolution_2d(x, self.ww), F.depthwise_convolution_2d(t, self.ww))
loss = tv_loss_h + tv_loss_w
return loss
def calc_quantization_loss(self, x):
img_255 = (x + 1) / 2 * 255
quantized_grayscale = self.xp.clip(img_255.data.round(), 0, 255)
return F.mean_absolute_error(img_255, quantized_grayscale)
感想
可逆なグレースケールといえばその通りなのですが、専用のエンコーダ・デコーダを用いるのでうーんといった感じです。ただ、Grayscale Conformity Lossの考え方はなるほどと思うところがあります。別に人間がグレースケールに見えれば良いんですよね。また、何か実装してみようと思います。