概要
一般人投稿サイト「wear」からファッションの画像とラベルのデータを取ってくる。
足りないライブラリはエラーログを見てpipでinstallすればよい。
注意
wearからとってきた画像の著作権は投稿ユーザーおよびwearの保有物なので使用する場合は注意が必要だ。
また、クローリングをする場合は待ち時間を持たせアクセス先のサイトに負担を掛けないよう心掛けること。
内容
おすすめコーディネートから画像を持ってきてリンク先のhttp://wear.jp/yuumi557188/11259208/ などのサイトから「トップス (ブラック系)」などのラベルを取ってくる。
clo.py
import time
import sys
import requests
from bs4 import BeautifulSoup
import re
import os
import shutil
start = time.time()
url = 'http://wear.jp/coordinate/'
res = requests.get(url)
soup = BeautifulSoup(res.content,'lxml')
i = 0
b = 0
di = 1
db = 6
g = 0
def labels(url):
fa = "http://wear.jp"+url
res = requests.get(fa)
soup = BeautifulSoup(res.content,'html.parser')
global g
with open('labels.txt', 'a+') as f:
f.write("%d\n"%g)
g+=1
for a in soup.find_all("a",href=re.compile("/category/")):
try:
h1_text = a.string
if(h1_text!="カテゴリ一覧"):
if(not '×' in h1_text):
if(not 'その他' in h1_text):
print(h1_text)
with open('labels.txt', 'a+') as f:
f.write(h1_text+"\n")
except Exception as e:
print(e)
def label_get():
global db,di
for a_tag in soup.find_all("a",attrs={"class": "over"}):
try:
if(db == 186):
break
if(di == db):
href_str = a_tag.get("href")
print(href_str)
labels(href_str)
db+=4
#print(b)
except Exception as e:
print(e)
finally:
di+=1
db = 6
di = 1
def download_img(url, file_name):
r = requests.get(url, stream=True)
if r.status_code == 200:
with open(file_name, 'wb') as f:
r.raw.decode_content = True
shutil.copyfileobj(r.raw, f)
def download():
global b,i
for a_tag in soup.find_all("img"):
try:
href_str = a_tag.get("data-original")
if b%2 !=0 :
download_img(href_str, '%d.jpg' %i)
print(href_str)
i+=1
b+=1
#resources.append(href_str)
except Exception as e:
print(e)
finally:
time.sleep(1)
b = 0
try:
for y in range(1,223):
if y != 1:
url = 'http://wear.jp/coordinate/?pageno=%d'%y
res = requests.get(url)
soup = BeautifulSoup(res.content,'html.parser')
while(True):
if soup.find("img" ,attrs={"src": "/common/img/blank.gif"}):
print(y)
download()
label_get()
elapsed_time = time.time() - start
print("time:{0}".format(elapsed_time))
break
else:
print("error")
url = 'http://wear.jp/coordinate/?pageno=%d'%y
res = requests.get(url)
soup = BeautifulSoup(res.content,'html.parser')
else:
print(y)
download()
label_get()
elapsed_time = time.time() - start
print("time:{0}".format(elapsed_time))
except Exception as e:
print(e)
結果
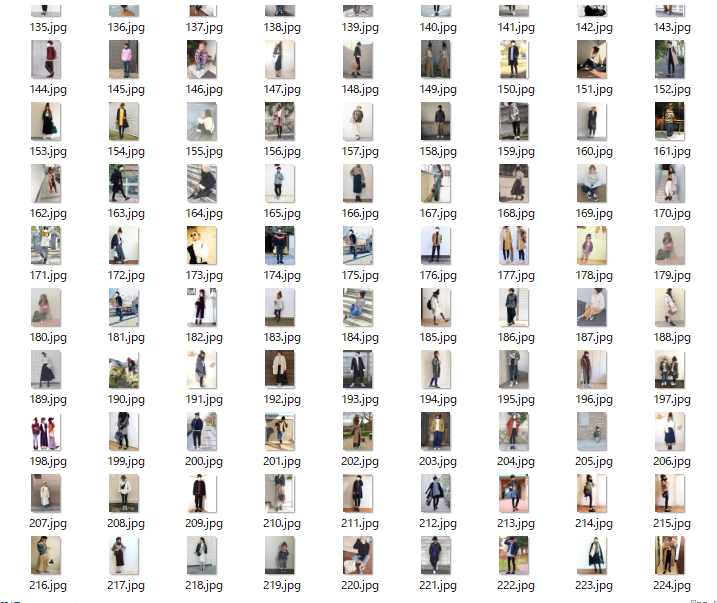
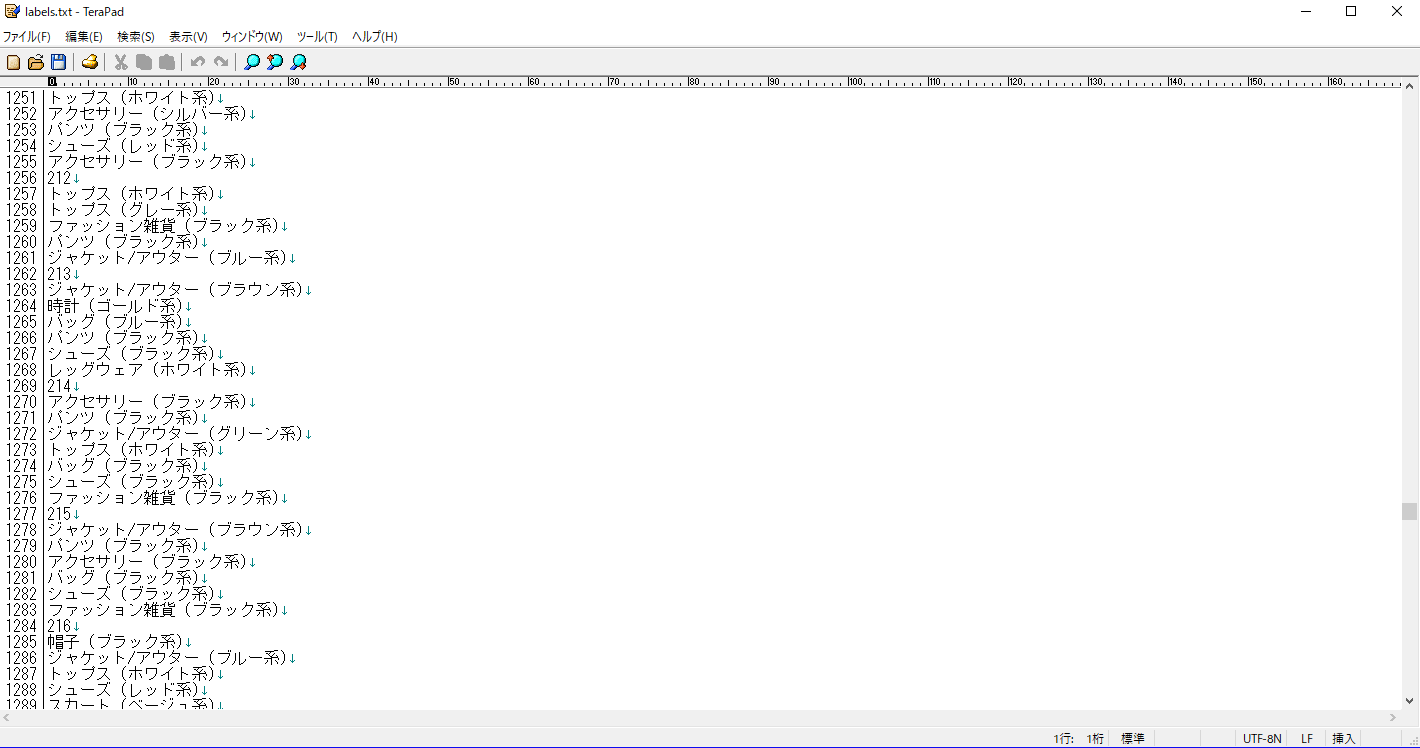
画像とその番号に準じたlabels.txtが上記の通り作られた。