やりたいこと
ワトソンの音声認証(Speech to text)を試してみます。
下記デモサイトのサンプルを実行してみる
(https://www.ibm.com/blogs/watson/2016/07/getting-robots-listen-using-watsons-speech-text-service/)
背景
動画の音声を、リアルタイムでテキスト化できるRaspberryPiロボ作成に向け、watsonの音声認証(Speech to Text)
を試してみる。
下図のような、Raspberry Pi3×Julius×Watson(Speech to Text)で音声認証&文字おこしが最終ゴール。
(http://qiita.com/nanako_ut/items/1e044eb494623a3961a5)
今回は下図の④部分のwatson音声認証方法を模索する。
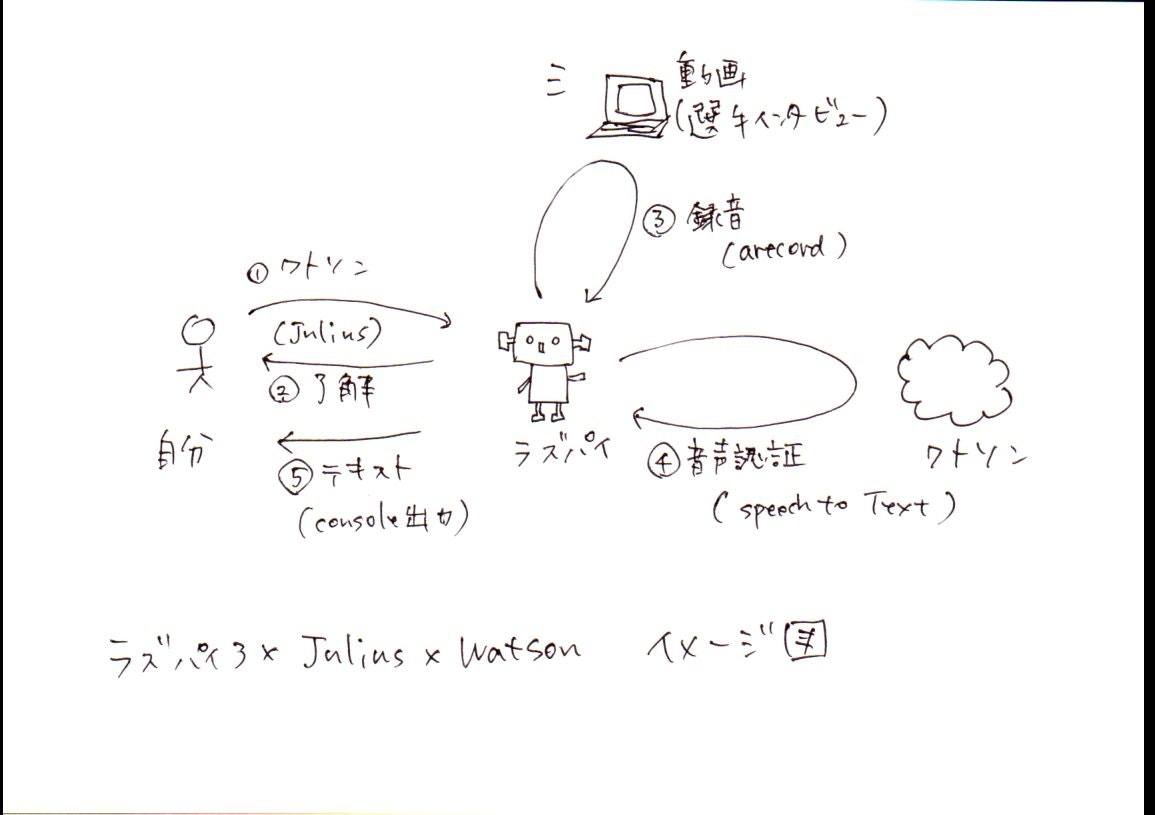
環境
- Raspberry Pi3
- Python 2.7.9
前提
以下は準備済とします。
- watsonへのユーザ登録(登録後1カ月間はすべてのサービスを無償で利用できるようです)
- watsonでSpeech to Textのサービス作成、資格情報取得済
※.watsonでSpeech to Textのサービス作成・資格情報取得方法は別途投稿します。
手順
1.curlで接続(音声ファイルアップロード)
2.pythonで接続その1(音声ファイルアップロード)
3.pythonで接続その2(WebSocket接続でリアルタイム音声解析)
■ curlで接続(音声ファイルアップロード)
1.1 音声ファイルをアップロード
音声ファイル(test.wat)を指定して、HTTP接続でwatsonへアップロード
※.username:passward には、資格情報のユーザ名とパスワードを指定
curl -X POST -u username:passward --header "Content-Type: audio/wav" --header "Transfer-Encoding: chunked" --data-binary @test.wav "https://stream.watsonplatform.net/speech-to-text/api/v1/recognize?model=ja-JP_BroadbandModel"
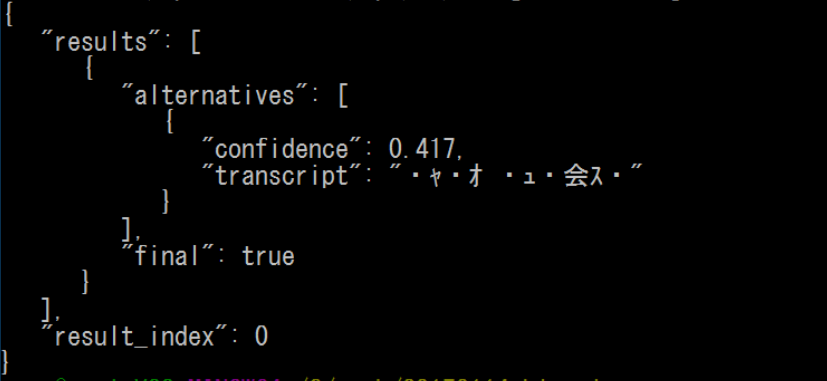
1.2 実行結果
何かは返ってきた。が、、、文字化けしている、、、
ラズパイがUTF-8で、日本語の解析結果(S-JIS?)のために文字化けした??
■ pythonで接続その1(音声ファイルアップロード)
こちらのサンプルソースを参考に実装
Getting robots to listen: Using Watson’s Speech to Text service
2.1 環境整備
watson用pythonライブラリ watson-developer-cloud-0.23.0 インストール
pipインストール
既にpipがインストールされれいる場合は不要。ラズパイ3に RASPBIAN JESSIE LITE を入れた為か、使用しているラズパイに入っていなかった。。。
$ python -m pip -V
/usr/bin/python: No module named pip
$ sudo apt-get install python-pip
Reading package lists... Done
Building dependency tree
~途中略~
$ python -m pip -V
pip 1.5.6 from /usr/lib/python2.7/dist-packages (python 2.7)
アップデート
$ sudo pip install -U pip
Downloading pip-9.0.1-py2.py3-none-any.whl (1.3MB): 1.3MB downloaded
Installing collected packages: pip
Found existing installation: pip 1.5.6
Not uninstalling pip at /usr/lib/python2.7/dist-packages, owned by OS
Successfully installed pip
Cleaning up...
$ python -m pip -V
pip 9.0.1 from /usr/local/lib/python2.7/dist-packages (python 2.7)
watson-developer-cloudインストール
$ sudo pip install --upgrade watson-developer-cloud
Collecting watson-developer-cloud
Downloading watson-developer-cloud-0.23.0.tar.gz (52kB)
~途中略~
Successfully installed pysolr-3.6.0 requests-2.12.5 watson-developer-cloud-0.23.0
2.2 実行プログラム
参考にしたサイトをコピペ
※.test1.wavは英語の音声を録音
from watson_developer_cloud import SpeechToTextV1
import json
stt = SpeechToTextV1(username="username", password="password")
audio_file = open("test1.wav", "rb")
print json.dumps(stt.recognize(audio_file, content_type="audio/wav"), indent=2)
2.3 実行
何か返ってきた。文章が返ってきている模様。
ただ、、もっと長い音声だったはずだが、途中で文章が切られてしまっている!??
{
"results": [
{
"alternatives": [
{
"confidence": 0.438,
"transcript": "so we know it's coming Julio just say yeah lost me grow mandatory right here shone like a great kid fifth grader etan Allemand planning his fifth critics "
}
],
"final": true
}
],
"result_index": 0
}
■ pythonで接続その2(WebSocket接続でリアルタイム音声解析)
webSocketというものを使うと、リアルタイムで音声解析ができるらしい。
3.1 webSocketとは
(https://www.html5rocks.com/ja/tutorials/websockets/basics/)
WebSocket 仕様は、ウェブ ブラウザとサーバー間に「ソケット」接続を確立する API を定義しています。
簡単に言うと、クライアントとサーバーの間に持続的接続があり、どちらの側からでも、いつでもデータの送信を開始できます。
らしい。
(http://www.atmarkit.co.jp/ait/articles/1111/11/news135.html)
HTML5では、「WebSocket」と呼ばれる新たな通信規格が追加された。
特徴
サーバとクライアント間は一度でも接続が確立すると、明示的に切断しない限り通信手順を意識することなくデータのやり取りをソケット通信で実施できる
WebSocketで接続が確立しているサーバとすべてのクライアントは同じデータを共有し、リアルタイムで送受信できる
従来の通信技術は通信のたびにHTTPヘッダが付与されるので、コネクションの数に応じてデータの送受信のほかに、わずかではあるがトラフィックが発生したりリソースが消費されたりしていた。
WebSocketは最初の接続時にそれ以降そのコネクションを使い続けるためにクライアントサイドからハンドシェイク要求を送る。
サーバ側はハンドシェイク応答を返すことで1つのコネクションを使用し、続ける仕組みになっている。
らしい。
な、なるほど。。。
3.2 環境整備
webSocket用ライブラリws4pyをインストール
$ sudo pip install ws4py
Collecting ws4py
Downloading ws4py-0.3.5-py2-none-any.whl (40kB)
100% |????????????????????????????????| 40kB 661kB/s
Installing collected packages: ws4py
Successfully installed ws4py-0.3.5
3.2 実行プログラム
参考にしたサイトをコピペ
from ws4py.client.threadedclient import WebSocketClient
import base64, time
class SpeechToTextClient(WebSocketClient):
def __init__(self):
ws_url = "wss://stream.watsonplatform.net/speech-to-text/api/v1/recognize"
username = "username"
password = "password"
auth_string = "%s:%s" % (username, password)
base64string = base64.encodestring(auth_string).replace("\n", "")
try:
WebSocketClient.__init__(self, ws_url,
headers=[("Authorization", "Basic %s" % base64string)])
self.connect()
except: print "Failed to open WebSocket."
def opened(self):
self.send('{"action": "start", "content-type": "audio/l16;rate=16000"}')
def received_message(self, message):
print message
stt_client = SpeechToTextClient()
time.sleep(3)
stt_client.close()
3.3 実行
音声データが返ってきた。
$ python watson_test2.py
opend
Message received: {u'state': u'listening'}
sleep audio
Recording raw data 'stdin' : Signed 16 bit Little Endian, Rate 16000 Hz, Mono
Message received: {u'results': [{u'alternatives': [{u'confidence': 0.713, u'transcript': u'over the entire course of the scalp was it was all the guys that one rings before imagine '}], u'final': True}], u'result_index': 0}
3.4 課題
んー、、、リアルタイムと言うのに、いくら音声データを送信しても、最初の1回しかメッセージを受信できない。
何かオプションがあるのか、データの渡し方が悪いのか、、、もう少し模索する必要がありそう。
最後に
bluemixのUIもどんどん変わっていたり、Speech to textのURLもサンプルと違っていたり、、とまだまだ開発中の模様。
調べることに時間がかかってしまうのが難点。。。