本日の目的・ゴール
目的
Week1でFastAPIを使ったAPIを作成したが、リスト保存のため、
データが一時的にしか保存されない課題があった。今回はバージョンアップして
SQLite × SQLAlchemyでDB連携させて、
永続的にデータを管理できるように進化させる。
ゴール
week1のAPIをSQLAlchemyに対応させる
学んだこと
fastapiとsqlalchemyでdb経由のcrud操作をやってみた
上記のサイトで示している方法を参考に下記のコードを作成した。
from sqlalchemy.orm import Session
from . import models
# 全タスクを取得
def get_all_tasks(db: Session):
return db.query(models.Task).all()
# タスクを新規作成
def create_task(db: Session, title: str, deadline: float, description: str = None):
task = models.Task(title=title, deadline=deadline, description=description)
db.add(task)
db.commit()
db.refresh(task)
return task
# タスクを更新
def update_task(db: Session, task_id: int, title: str, deadline: float):
task = db.query(models.Task).filter(models.Task.id == task_id).first()
if task:
task.title = title
task.deadline = deadline
db.commit()
db.refresh(task)
return task
return None
# タスクを削除
def delete_task(db: Session, task_id: int):
task = db.query(models.Task).filter(models.Task.id == task_id).first()
if task:
db.delete(task)
db.commit()
return True
return False
1. crud.py
DB操作をする(insertやdeleteなど)関数群をまとめたファイル
Sessionクラス
SQLAlchemyモジュール内のクラス、
Sessionは sessionmaker() によって作成される「トランザクションの単位」。
DB接続を保持し、クエリ実行やコミット、ロールバックを管理する。
.コマンドの使い方
from . import models
Taskクラスを利用するため、同じ階層にあるmodels.pyをインポートしている。
. SQLAlchemyを使ったinsertの方法
既存メゾット👇セッションにこのデータをInsert対象にすると指定
db.add(task)
既存メゾット👇取引を完了してDBに反映する具体的にDBにinsertされるのはこの時点
db.commit()
既存メゾット👇DBにデータが反映された最新の状態をtaskオブジェクトに反映する
db.refresh(task)
既存メゾット👇生成されたtaskオブジェクトを返す
return task
Update文
• .query() … 既存メソッド(SQLAlchemy):SELECT開始。
• .filter() … 既存メソッド(SQLAlchemy):WHERE句に相当。
• .first() … 既存メソッド(SQLAlchemy):最初の1件だけ取得。
→ 結果として「task_idに一致するタスク1件」を取得するという意味。
task = db.query(models.Task).filter(models.Task.id == task_id).first()
2.main.py
DAY1 で作成したmain.pyのAPIを本格的にDBと連携できるようにさせる
ここではday1で作成したmain.pyに依存関係注入(Dependency Injection)という機能を追加した。
依存関係注入(Dependency Injection)とは、DB接続のためのセッションの準備・利用・完了までを一括管理すること。
まず最初に
def get_db():
db = SessionLocal()
try:
yield db
finally:
db.close()
このようにget_db()関数でSessionLocal()(database.pyで作成した関数)を生成し、yieldで一時的に渡して各エンドポイントの処理が完了したら自動でclose()することができる。
Depends(get_db)
@app.get("/tasks/")
def read_tasks(db: Session = Depends(get_db)):
return crud.get_all_tasks(db)
各エンドポイントで関数を動かすときは上記のように書くことで「このAPI関数が呼ばれるとき、get_db()を先に実行して、その結果(db)をこの引数に入れる」という処理にすることができる。
@app.get("/tasks/")
def read_tasks():
db = SessionLocal()
tasks = crud.get_all_tasks(db)
db.close()
return tasks
上記のように各エンドポイントでセッション情報をとってきて、処理してDBを閉じるという流れを作ることもできるが、毎度書くと面倒だし保守性を考えても今回のように全てのAPIで共通のDB接続管理を自動化できる依存関係注入は便利だと思った。
躓いたところ
サーバーを一度起動させてからdeadlineの項目を出したため、すでに存在している SQLite ファイル(task.db)には自動で反映されなかった。そのため、docsでcreat_taskを実行した時にerror500(サーバー内エラー)が発生した。
SQLAlchemy の create_all() は「存在しないテーブルを新規作成する」動作のみで、既存テーブルのマイグレーションには Alembic を使う必要がある。
一度サーバーを停止してすでに作成されているtask.dbを削除して、もう一度サーバーを再起動させた。
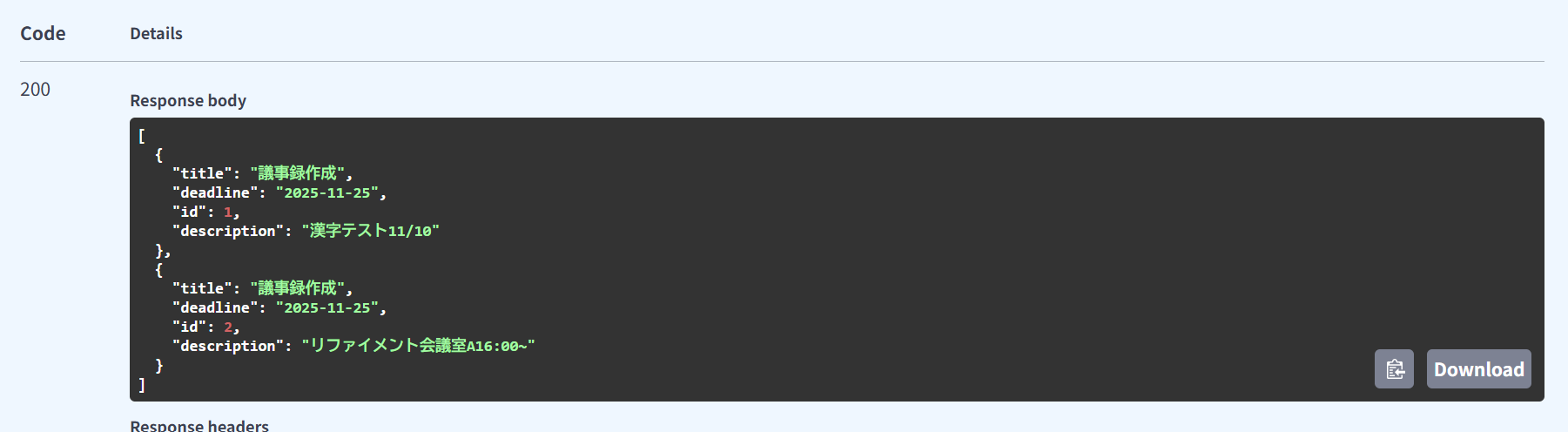
無事deadline項目を追加してタスクを登録できた!
所感
今回の学習を通じて、FastAPIの「依存関係注入」が保守性に直結する仕組みであることを実感した。
これまでAPI実装では機能単位でコードを書いていたが、DB接続処理を関数化・共通化することで「責務の分離」が明確になった。
今後は create_all() の限界を踏まえて、Alembicを使ったマイグレーション管理にも挑戦したい。
業務上の要件定義においても、「再利用性」や「変更容易性」を意識して設計することが、最終的にシステム全体の品質向上につながると感じた。