この記事は「【リアルタイム電力予測】需要・価格・電源最適化ダッシュボード構築記」シリーズの五日目です
Day1はこちら | 全体構成を見る
前回は電力消費量・気象情報・日付情報を統合したデータセットを使って、LightGBMを試し、決定係数が訓練データで 87.8%、テストデータで 86.8% でした。
今回はさらなる精度改善を狙い、GRU(Gated Recurrent Unit)モデル を使ってみます。
GRUで予測する理由
GRU は、RNN 系列モデルの一種で、以下のような特徴を持っています。
- 過去の情報を保持する「ゲート機構」を持つ
- シンプルなRNNの弱点だった 勾配消失 を軽減できる
- LSTM よりパラメータが少なく、計算が軽い
電力需要のように、
- 時間帯(朝・昼・夜)
- 曜日(平日・休日)
- 季節(夏・冬)
といった過去のパターンを直接系列として入力できる GRU のほうが、表形式の特徴量しか扱えない LightGBM より有利になる可能性があります。
LightGBMでは、次のような「1 行 = 1 時点」の表形式特徴量を直接入力していました。
- 月(raw)
- 時間(raw)
- 年(カテゴリカル)
- 祝日フラグ
- 湿度
- 気温
- 気温絶対値(18.1℃からの距離)
一方、GRUでは、過去24ステップ分の特徴量(今回は12時間分)の系列をまとめて入力し、その系列全体から 次の1ステップの需要を予測するという形となります。そのため、LightGBM で効いた特徴量が、そのまま GRU でも効くとは限りません。
GRUとスケーリング
LightGBMは木構造モデルなので、スケール(値の大きさ)にほとんど影響を受けないですが、GRUのようなニューラルネットワークは、
- 入力値のスケールがバラバラだと勾配が不安定になりやすい
- 特に目的変数のスケールが大きいと、MSE の勾配が巨大になって学習が発散しやすい
という性質があります。
実際、目的変数(電力消費量)を生の値のまま入れたときは、全く収束しませんでした。誤差の桁が大きすぎて、損失関数(MSE)の値も勾配も大きくなり、ロスが数億単位になり学習が進みませんでした(-_-;)
そこで今回の GRU では、
- 目的変数 y は必ずスケーリング(標準化 or 正規化)する
- 入力特徴量 X についても、「かける / かけない」をパターン分けして実験する
という方針にしています。
前処理と実験の設計
前回と同様のdfを使っていきます。

前回と同じように
- 2016-04-01〜2024-03-31 → 学習データ
- 2024-04-01〜2025-03-31 → テストデータ
と分割し、最終的に
X_train.shape, y_train.shape, X_test.shape, y_test.shape
→ (140256, 7) (140256,) (17520, 7) (17520,)
という形にしています(30分解像度)。
実装は実験しやすいように
- どの特徴量を使うか(feature_cols)
- どの列にスケーリングをかけるか(scaled_cols)
- sin/cos 変換をするかどうか(use_sin_cos=True/False)
を引数で切り替えられるようにしています。
それぞれの設定で学習 → 評価した結果を results 辞書に溜めておき、最後に DataFrame で比較でいます。
今回実験したパターンは以下の3ポイントです。
- 特徴量として何を入れるか
- 特徴量に対して 標準化(StandardScaler) / 正規化(MinMaxScaler)をかけるかどうか
- 月と時間に対して sin, cos 変換を入れるかどうか
実装コード
前処理
import numpy as np
import pandas as pd
from sklearn.preprocessing import StandardScaler, MinMaxScaler
def add_time_sin_cos(df: pd.DataFrame,
month_col: str = "month",
hour_col: str = "hour",
add_month: bool = True,
add_hour: bool = True) -> pd.DataFrame:
df = df.copy()
if add_month and month_col in df.columns:
df["month_sin"] = np.sin(2 * np.pi * df[month_col] / 12)
df["month_cos"] = np.cos(2 * np.pi * df[month_col] / 12)
if add_hour and hour_col in df.columns:
df["hour_sin"] = np.sin(2 * np.pi * df[hour_col] / 24)
df["hour_cos"] = np.cos(2 * np.pi * df[hour_col] / 24)
return df
def scale_features(
train_X: pd.DataFrame,
test_X: pd.DataFrame,
train_y: pd.Series,
test_y: pd.Series,
scaled_cols: list | None,
scaler_X: StandardScaler | None = None,
scaler_y: StandardScaler | None = None,
):
train_X = train_X.copy()
test_X = test_X.copy()
# === 特徴量のスケーリング ===
if scaled_cols:
# 実在する列だけを対象にする
scaled_cols = [c for c in scaled_cols if c in train_X.columns]
non_scaled_cols = [c for c in train_X.columns if c not in scaled_cols]
# スケーラーの fit / transform
if scaler_X is None:
scaler_X = StandardScaler()
X_train_scaled = scaler_X.fit_transform(train_X[scaled_cols])
else:
X_train_scaled = scaler_X.transform(train_X[scaled_cols])
X_test_scaled = scaler_X.transform(test_X[scaled_cols])
# DataFrame に戻す
X_train_scaled_df = pd.DataFrame(X_train_scaled, columns=scaled_cols, index=train_X.index)
X_test_scaled_df = pd.DataFrame(X_test_scaled, columns=scaled_cols, index=test_X.index)
# 非スケーリング列と結合
train_X_final = pd.concat([train_X[non_scaled_cols], X_train_scaled_df], axis=1)
test_X_final = pd.concat([test_X[non_scaled_cols], X_test_scaled_df], axis=1)
else:
# スケーリングなし
train_X_final = train_X
test_X_final = test_X
# === 目的変数 y のスケーリング ===
if scaler_y is None:
scaler_y = StandardScaler()
y_train_scaled = scaler_y.fit_transform(train_y.values.reshape(-1, 1))
else:
y_train_scaled = scaler_y.transform(train_y.values.reshape(-1, 1))
y_test_scaled = scaler_y.transform(test_y.values.reshape(-1, 1))
# === ログ出力(任意) ===
print("train_X_final:\n", train_X_final.head())
print("test_X_final:\n", test_X_final.head())
return train_X_final, test_X_final, y_train_scaled, y_test_scaled, scaler_X, scaler_y
import torch
def create_sequences(data: torch.Tensor,
targets: torch.Tensor,
sequence_length: int):
"""
data : (N, num_features)
targets : (N,) or (N,1)
"""
if targets.ndim == 1:
targets = targets.unsqueeze(-1)
sequences = []
labels = []
for i in range(len(data) - sequence_length):
seq = data[i:i+sequence_length] # (seq_len, num_features)
label = targets[i+sequence_length] # (1,)
sequences.append(seq)
labels.append(label)
return torch.stack(sequences), torch.stack(labels)
前処理実行
def prepare_gru_data(
train_df: pd.DataFrame,
test_df: pd.DataFrame,
feature_cols: list,
target_col: str,
scaled_cols: list | None,
sequence_length: int,
use_time_sin_cos: bool = False,
month_col: str = "month",
hour_col: str = "hour",
scaler: StandardScaler | None = None,
):
"""
train_df, test_df : 時系列順にソート済みの DataFrame
feature_cols : モデルに使いたい特徴量の列名
target_col : 目的変数(realized_demand)
scaled_cols : 標準化したい列名(feature_cols の部分集合)
sequence_length : GRU の入力長(例: 24, 48 など)
use_time_sin_cos : month/hour に対して sin,cos を追加するかどうか
"""
# 必要な列だけ抜き出し
train_X = train_df[feature_cols].copy()
test_X = test_df[feature_cols].copy()
train_y = train_df[target_col].copy()
test_y = test_df[target_col].copy()
# 時間の sin/cos を追加する場合
if use_time_sin_cos:
train_X = add_time_sin_cos(train_X, month_col=month_col, hour_col=hour_col)
test_X = add_time_sin_cos(test_X, month_col=month_col, hour_col=hour_col)
# スケーリング
train_X_final, test_X_final, y_train_scaled, y_test_scaled, scaler_X, scaler_y = scale_features(
train_X, test_X, train_y, test_y, scaled_cols=scaled_cols
)
print("train_X_final shape:", train_X_final.shape)
print("test_X_final shape:", test_X_final.shape)
# Tensor へ変換
data_train = torch.tensor(train_X_final.values, dtype=torch.float32)
data_test = torch.tensor(test_X_final.values, dtype=torch.float32)
targets_train = torch.tensor(y_train_scaled, dtype=torch.float32)
targets_test = torch.tensor(y_test_scaled, dtype=torch.float32)
# シーケンス作成
train_sequences, train_labels = create_sequences(data_train, targets_train, sequence_length)
test_sequences, test_labels = create_sequences(data_test, targets_test, sequence_length)
print("train_sequences:", train_sequences.shape)
print("train_labels :", train_labels.shape)
print("test_sequences :", test_sequences.shape)
print("test_labels :", test_labels.shape)
return (
train_sequences,
train_labels,
test_sequences,
test_labels,
scaler_X,
scaler_y
)
<details><summary>モデル定義</summary>
```python
# モデル定義
class GRUModel(nn.Module):
def __init__(self, input_size: int, hidden_size: int, output_size: int = 1,
num_layers: int = 1, dropout: float = 0.0):
"""
input_size : 特徴量の次元数(1タイムステップあたりの特徴量数)
hidden_size: GRUの隠れ状態の次元
output_size: 出力次元(今回は1: 需要の1ステップ予測)
num_layers : GRUの層数
dropout : GRU層間のdropout率(num_layers > 1 のとき有効)
"""
super().__init__()
self.gru = nn.GRU(
input_size=input_size,
hidden_size=hidden_size,
num_layers=num_layers,
batch_first=True,
dropout=dropout if num_layers > 1 else 0.0,
)
self.fc = nn.Linear(hidden_size, output_size)
def forward(self, x):
# x: (batch, seq_len, input_size)
out, _ = self.gru(x) # out: (batch, seq_len, hidden_size)
out = out[:, -1, :] # 最後の時間ステップのみ取り出し → (batch, hidden_size)
out = self.fc(out) # → (batch, output_size)
return out
モデル初期化
def initialize_gru_model(
input_size: int,
hidden_size: int,
num_layers: int,
learning_rate: float,
dropout: float = 0.0,
device: str = "cuda",
):
model = GRUModel(
input_size=input_size,
hidden_size=hidden_size,
output_size=1,
num_layers=num_layers,
dropout=dropout,
).to(device)
criterion = nn.MSELoss()
optimizer = torch.optim.AdamW(model.parameters(), lr=learning_rate)
return model, criterion, optimizer
# Early Stopping クラス
class EarlyStopping:
def __init__(self, patience=5):
self.patience = patience
self.best_loss = float('inf')
self.trigger_times = 0
def check(self, current_loss):
if current_loss < self.best_loss:
self.best_loss = current_loss
self.trigger_times = 0
return False # Early Stoppingしない
else:
self.trigger_times += 1
return self.trigger_times >= self.patience # 改善が見られなければTrue
訓練と検証の1epoch
# 訓練処理
def train_one_epoch(model, dataloader, criterion, optimizer, scaler_y, device="cuda"):
model.train()
total_loss = 0.0
all_predictions = []
all_targets = []
for batch_X, batch_y in dataloader: # 入力データのバッチと対応するラベル(ターゲット値)のバッチを取得
batch_X, batch_y = batch_X.to(device), batch_y.to(device)
outputs = model(batch_X) # モデルで予測
loss = criterion(outputs, batch_y) # 出力とラベルの損失を計算
# パラメータに対する勾配を初期化(デフォルトで各バッチの計算で勾配が累積される)
optimizer.zero_grad()
# 逆伝播を実行し、モデルのすべてのパラメータに対する損失の勾配を計算
loss.backward()
# 学習率を用いてoptimizer(torch.optim.Adam)が計算された勾配を使用してパラメータを更新
optimizer.step()
total_loss += loss.item() # 各バッチの損失を累積
all_predictions.append(outputs.detach())
all_targets.append(batch_y.detach())
predictions = scaler_y.inverse_transform(torch.cat(all_predictions).cpu().numpy())
targets = scaler_y.inverse_transform(torch.cat(all_targets).cpu().numpy())
rmse = np.sqrt(mean_squared_error(targets, predictions))
return total_loss / len(dataloader), rmse, predictions, targets # エポック全体の平均損失(loss)を計算
# 検証処理
def evaluate(model, dataloader, criterion, scaler_y, device="cuda"):
model.eval()
total_loss = 0.0
all_predictions = []
all_targets = []
with torch.no_grad():
for batch_X, batch_y in dataloader:
batch_X, batch_y = batch_X.to(device), batch_y.to(device)
outputs = model(batch_X) # モデルの予測値を計算
loss = criterion(outputs, batch_y)
# 検証(evaluate)ではモデルの性能を確認するだけでパラメータの更新を行わない
total_loss += loss.item()
all_predictions.append(outputs)
all_targets.append(batch_y)
predictions = scaler_y.inverse_transform(torch.cat(all_predictions).cpu().numpy()) # すべてのバッチの予測値を1つのテンソルにしてからスケールを元に戻sす
targets = scaler_y.inverse_transform(torch.cat(all_targets).cpu().numpy())
rmse = np.sqrt(mean_squared_error(targets, predictions))
return total_loss / len(dataloader), rmse, predictions, targets
訓練と検証の実行
def train_and_evaluate(
model,
train_loader,
test_loader,
criterion,
optimizer,
num_epochs: int,
patience: int,
scaler_y,
device: str = "cuda",
):
train_losses = []
train_rmses = []
test_losses = []
test_rmses = []
early_stopping = EarlyStopping(patience=patience)
best_state_dict = None
best_test_loss = float("inf")
best_epoch = -1
for epoch in range(num_epochs):
# 1エポック学習
train_loss, train_rmse, _, _ = train_one_epoch(
model, train_loader, criterion, optimizer, scaler_y, device
)
# 検証
test_loss, test_rmse, _, _ = evaluate(
model, test_loader, criterion, scaler_y, device
)
train_losses.append(train_loss)
train_rmses.append(train_rmse)
test_losses.append(test_loss)
test_rmses.append(test_rmse)
print(
f"Epoch {epoch+1}/{num_epochs} | "
f"Train Loss: {train_loss:.4f}, Train RMSE: {train_rmse:.4f} | "
f"Test Loss: {test_loss:.4f}, Test RMSE: {test_rmse:.4f}"
)
# ベストモデルを記録
if test_loss < best_test_loss:
best_test_loss = test_loss
best_state_dict = model.state_dict()
best_epoch = epoch + 1
if early_stopping.check(test_loss):
print(f"Early stopping triggered at epoch {epoch+1}")
break
if best_state_dict is not None:
print(f"Loading best model from epoch {best_epoch} (val loss={best_test_loss:.4f})")
model.load_state_dict(best_state_dict)
# ベストモデルで train / test を再評価
_, _, train_pred, train_tgt = evaluate(
model, train_loader, criterion, scaler_y, device
)
_, _, test_pred, test_tgt = evaluate(
model, test_loader, criterion, scaler_y, device
)
train_r2 = r2_score(train_tgt, train_pred)
train_rmse_final = np.sqrt(mean_squared_error(train_tgt, train_pred))
test_r2 = r2_score(test_tgt, test_pred)
test_rmse_final = np.sqrt(mean_squared_error(test_tgt, test_pred))
return (
train_losses, # 学習中の loss カーブ用
train_rmses, # 学習中の RMSE カーブ用
test_losses,
test_rmses,
train_pred, # ベストモデルでの train 予測
train_tgt,
test_pred, # ベストモデルでの test 予測
test_tgt,
train_r2,
train_rmse_final,
test_r2,
test_rmse_final,
best_epoch,
best_test_loss,
)
def plot_loss_curve(
train_losses,
test_losses,
train_r2,
train_rmse,
test_r2,
test_rmse,
):
plt.figure(figsize=(10, 5))
plt.plot(train_losses, label="Train Loss")
plt.plot(test_losses, label="Test Loss")
plt.xlabel("Epochs")
plt.ylabel("Loss (MSE)")
plt.title(
"Loss Curve\n"
f"train RMSE: {train_rmse:.3f}, R2: {train_r2:.3f}\n"
f"test RMSE: {test_rmse:.3f}, R2: {test_r2:.3f}"
)
plt.legend()
plt.show()
seed設定
# random seed
def set_seed(seed):
torch.manual_seed(seed)
np.random.seed(seed)
random.seed(seed)
# PyTorchのCuDNNライブラリ(NVIDIA GPU専用)での動作を制御する設定
torch.backends.cudnn.deterministic = True
torch.backends.cudnn.benchmark = False
実験の実行
def run_experiment(
train_sequences: torch.Tensor,
train_labels: torch.Tensor,
test_sequences: torch.Tensor,
test_labels: torch.Tensor,
scaler_y,
hidden_size: int = 128,
num_layers: int = 1,
num_epochs: int = 100,
batch_size: int = 128,
learning_rate: float = 0.002,
dropout: float = 0.0,
patience: int = 15,
device: str = "cuda",
):
"""
train_sequences: (N_train, seq_len, input_size)
train_labels : (N_train, 1) or (N_train,)
test_sequences : (N_test, seq_len, input_size)
test_labels : (N_test, 1) or (N_test,)
"""
set_seed(42)
# ラベルの形を (N,1) に揃えておく(MSELossが扱いやすいように)
if train_labels.ndim == 1:
train_labels = train_labels.unsqueeze(-1)
if test_labels.ndim == 1:
test_labels = test_labels.unsqueeze(-1)
input_size = train_sequences.shape[-1]
model, criterion, optimizer = initialize_gru_model(
input_size=input_size,
hidden_size=hidden_size,
num_layers=num_layers,
learning_rate=learning_rate,
dropout=dropout,
device=device,
)
train_dataset = TensorDataset(train_sequences, train_labels)
test_dataset = TensorDataset(test_sequences, test_labels)
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False)
(
train_losses,
train_rmses,
test_losses,
test_rmses,
train_pred,
train_tgt,
test_pred,
test_tgt,
train_r2,
train_rmse,
test_r2,
test_rmse,
best_epoch,
best_test_loss,
) = train_and_evaluate(
model,
train_loader,
test_loader,
criterion,
optimizer,
num_epochs=num_epochs,
patience=patience,
scaler_y=scaler_y,
device=device,
)
# プロット用にはメトリクスだけ渡す
plot_loss_curve(
train_losses,
test_losses,
train_r2,
train_rmse,
test_r2,
test_rmse,
)
# 比較用に全部返す
results = {
"model": model,
"train_losses": train_losses,
"train_rmses": train_rmses,
"test_losses": test_losses,
"test_rmses": test_rmses,
"train_pred": train_pred,
"train_tgt": train_tgt,
"test_pred": test_pred,
"test_tgt": test_tgt,
"train_r2": train_r2,
"train_rmse": train_rmse,
"test_r2": test_r2,
"test_rmse": test_rmse,
"best_epoch": best_epoch,
"best_test_loss": best_test_loss,
}
return results
上記のコードを以下のコードで調整しながら実験しました。
Scalerが StandardScaler になっているので、その点だけ変える必要があります。
feature_cols_A = ["month", "hour", "is_holiday", "humidity", "temperature", "temperature_abs"]
scaled_cols_A = ["month", "hour", "humidity", "temperature", "temperature_abs"]
train_seq_A, train_lab_A, test_seq_A, test_lab_A, scaler_X_A, scaler_y_A = prepare_gru_data(
train_df=train_df,
test_df=test_df,
feature_cols=feature_cols_A,
target_col="realized_demand",
scaled_cols=scaled_cols_A,
sequence_length=24,
use_time_sin_cos=False,
)
results_A = run_experiment(
train_seq_A, train_lab_A, test_seq_A, test_lab_A, scaler_y_A
)
最後のresults_Xには辞書型でmetricsが入るので、最後にdf化すると実験比較に便利です。
目的変数 y をスケーリングしないとどうなるか
すでに書いた通り、目的変数を生の値のまま入れるとMSE の値がとにかく大きく、エポックを重ねてもロスがほぼ減らないという状態でした。
これは
- 予測値と実測値の差が「万kW」単位で出る
- その差を二乗する MSE は、誤差が少し大きく出るだけで一気に巨大になる
- その巨大なロスに対する勾配もまた巨大になる
という悪循環によるもので、目的変数だけは必ずスケーリングすべき、という良い反例になりました!
以降のすべての実験では、
- y は必ず標準化または正規化
- X は「かける / かけない」の両方を試す
という前提で比較していいます。
実験
特徴量とスケーリング手法を変えたときの RMSE / R² の一覧を記載していきます。
loss はスケーリング後の MSE なので、標準化と正規化のあいだで数値を直接比較することはできません(正規化の方が値が小さく見えるのは、レンジが 0〜1 だから、というだけ)。
1. 月、時間、祝日フラグ、湿度、気温、気温絶対値差分
⇒ 月、時間、湿度、気温、気温絶対値差分に標準化または正規化をかける
| スケーリング手法 | train_rmse | train_r2 | test_rmse | test_r2 | loss |
|---|---|---|---|---|---|
| 標準化 | 1535.518 | 0.947 | 3106.969 | 0.810 | 0.152 |
| 正規化 | 2346.589 | 0.876 | 2622.683 | 0.865 | 0.004 |
- 標準化は学習データにはかなり強くフィットしているが、そのぶんテストでは過学習ぎみ
- 正規化のほうが test R² が高く、汎化性能は良い
2. 月、月(sin,cos)、時間、時間(sin,cos)、祝日フラグ、湿度、気温、気温絶対値差分
⇒ 上記すべてに標準化または正規化をかける
| スケーリング手法 | train_rmse | train_r2 | test_rmse | test_r2 | loss |
|---|---|---|---|---|---|
| 標準化 | 1424.336 | 0.954 | 3136.730 | 0.806 | 0.154 |
| 正規化 | 2000.461 | 0.910 | 2822.686 | 0.843 | 0.004 |
- ここでも、標準化は train R² が非常に高いが test R² が落ちる
- 正規化は train はやや抑えめだが、test ではより安定している
3. 月、時間、祝日フラグ、湿度、気温、気温絶対値差分
⇒目的変数のみ標準化/正規化(特徴量にはかけない)
| スケーリング手法 | train_rmse | train_r2 | test_rmse | test_r2 | loss |
|---|---|---|---|---|---|
| 標準化 | 2395.087 | 0.871 | 2832.404 | 0.842 | 0.147 |
| 正規化 | 2466.005 | 0.863 | 2762.519 | 0.850 | 0.004 |
- 特徴量をスケーリングしなくても、test の性能は大きく悪化しない
- ただし train 側は、スケーリングしたケースよりやや悪くなる
4. 月、月(sin,cos)、時間、時間(sin,cos)、祝日フラグ、湿度、気温、気温絶対値差分
⇒目的変数のみ標準化/正規化(特徴量にはかけない)
| スケーリング手法 | train_rmse | train_r2 | test_rmse | test_r2 | loss |
|---|---|---|---|---|---|
| 標準化 | 2335.582 | 0.877 | 2832.579 | 0.842 | 0.142 |
| 正規化 | 2449.147 | 0.865 | 2558.349 | 0.871 | 0.004 |
- sin,cos を追加して特徴量数は増えたが、この設定では過学習にはなっていない。
5. 月、時間、祝日フラグ、湿度、気温
⇒目的変数のみ標準化/正規化(特徴量にはかけない)
| スケーリング手法 | train_rmse | train_r2 | test_rmse | test_r2 | loss |
|---|---|---|---|---|---|
| 標準化 | 2532.816 | 0.856 | 2709.139 | 0.856 | 0.143 |
| 正規化 | 2446.226 | 0.865 | 2609.505 | 0.866 | 0.004 |
- 気温絶対値差分を抜いても、性能はほとんど変わらない
- 気温そのものがかなり効いているため、temperature_abs はあってもなくてもよい
6. 月、時間、祝日フラグ、気温
⇒目的変数のみ標準化/正規化(特徴量にはかけない)
| スケーリング手法 | train_rmse | train_r2 | test_rmse | test_r2 | loss |
|---|---|---|---|---|---|
| 標準化 | 2382.500 | 0.872 | 2699.181 | 0.857 | 0.145 |
| 正規化 | 2485.508 | 0.861 | 2569.971 | 0.870 | 0.004 |
- 湿度を抜いても test R² はほぼ変わらない
- GRU にとっては、月・時間・祝日フラグ・気温だけでもかなりの情報が含まれていることが分かる
7. 月、時間、祝日フラグ、気温
⇒気温に標準化または正規化をかける
| スケーリング手法 | train_rmse | train_r2 | test_rmse | test_r2 | loss |
|---|---|---|---|---|---|
| 標準化 | 2404.444 | 0.870 | 2601.959 | 0.867 | 0.142 |
| 正規化 | 2570.991 | 0.851 | 2807.351 | 0.845 | 0.004 |
- 気温だけスケーリングするパターンは、あまり良い結果にならなかった
- 特徴量間のスケールバランスが崩れるので、中途半端なスケーリングは逆効果になりやすい?
8. 月、時間、祝日フラグ、気温
⇒月、時間、気温に標準化または正規化をかける
| スケーリング手法 | train_rmse | train_r2 | test_rmse | test_r2 | loss |
|---|---|---|---|---|---|
| 標準化 | 2250.168 | 0.886 | 2750.416 | 0.851 | 0.153 |
| 正規化 | 2472.560 | 0.862 | 2584.558 | 0.869 | 0.004 |
- 月・時間・気温にまとめてスケーリングをかけたところ、標準化と正規化で傾向が分かれた
- 標準化:train がかなり良いが、test はやや悪化
- 正規化:train は抑えめだが、test は比較的良い
ベストモデル
月、月(sin,cos)、時間、時間(sin,cos)、祝日フラグ、湿度、気温、気温絶対値差分を特徴量とし、特徴量は生のまま、目的変数のみに正規化をかけたGRU :テストデータでの決定係数 87.1%
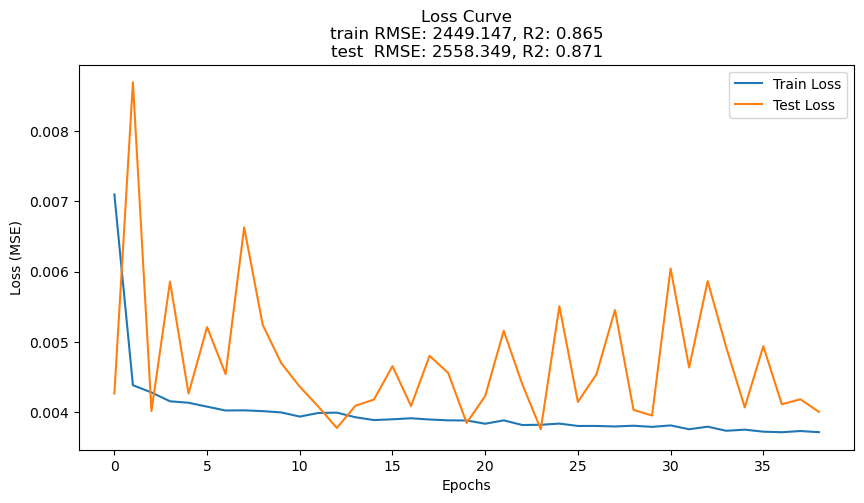
LightGBM(test R² ≒ 86.8%)とほぼ同等〜わずかに上回る精度でした。
考察
- 標準化のほうが train へのフィットは強いが、test 性能は正規化のほうが良い傾向がある
- 標準化は平均 0・分散 1 に中心化するため、年ごとの「絶対レベル」の違いが薄まりやすい ⇒ 学習データに対しては複雑な関数で強くフィットできるが、その分テストでは過学習しやすい
- 正規化は0~1に圧縮するが、比率や変化幅などの相対的な違いは維持される ⇒ train は標準化ほどは伸びないが、test ではより安定した性能を出せる
- 例えば、気温 30→35℃ の変化を考えると、標準化の場合
- 冷夏の年では 25℃ でも「高温寄り」
- 猛暑の年では 25℃ は「低温寄り」
といった形で「その年の分布」によって基準が変わる。正規化は全期間の最小値〜最大値で揃えるため、全期間を通しての相対的な暑さ/寒さが一貫したスケールで扱えるのが利点だと考えられる。
可視化
最後に実績と予測を可視化してみました。

夏だけ拡大:
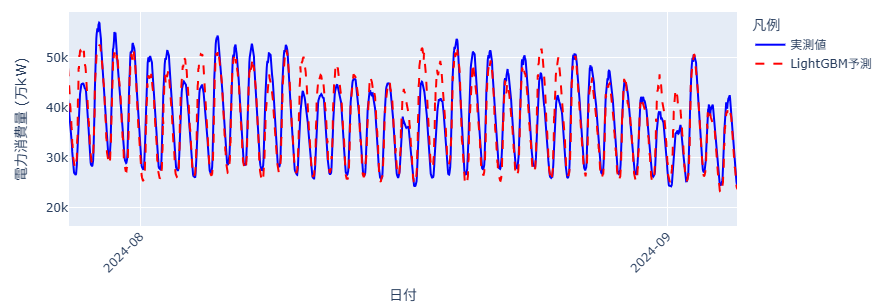
全体としては、谷と山のタイミングはよく追えています。しかし、最大需要を前日のピークからそのまま引きずって、ほんの少しだけオーバーに予測してしまっている日も見られます。
また余談
12時間 ではなく、** 24時間** を系列長で実験してみると精度が悪くなりました。
半日、日、週、季節といった複雑な周期成分を持つ電力データですが、消費電力の大きな変動は半日周期のほうが顕著であるということでしょうか。おそらく、系列長 48(=過去 24h)を入れた GRU は、不要に長い依存関係を追おうとしてノイズを拾い、学習が不安定化してしまいます。
明日
明日は残差分析を行ってどの時間帯・どの季節で外しやすいかを見ていきます!![]()