EMRのバージョンが 5.0.0 になって、デフォルトのアプリケーションで Zeppelin 0.6.1 が使えるようになっていたので試してみました。
ERMの設定は、アプリケーションで spark を選択するだけなので省略します。
RDSとの接続
Interpreterインストール
Zeppelinはjdbcが使えるので、jdbcのinterpreterをインストールします。
cd /usr/lib/zeppelin/
sudo ./bin/install-interpreter.sh --name jdbc
その他のinterpreterは、以下で見る事が出来ます。
./bin/install-interpreter.sh --list
Interpreter設定
mysql用のjdbcドライバーをダウンロードしておきます。 mysql-connector-java-5.1.39-bin.jar
これをパスの通った所に置いておく必要があります。
私は、 /usr/lib/zeppelin/lib/ に配置しました。
それから画面右上のメニューで、Interpreterという所を開きます。
右上の +Create を押して、Name には JDBC などの適当な名前を入力します。
Interpreter group で、 jdbcを選択します。
あとは接続設定を作ります。
Properties
| name | value |
|---|---|
| mysql.driver | com.mysql.jdbc.Driver |
| mysql.url | URLを入れてください。例(jdbc:mysql://hoge.ap-northeast-1.rds.amazonaws.com:3306/fuga) |
| mysql.user | ユーザ名を入れてください |
| mysql.password | パスワードを入れてください |
(mysqlの所がplefixになりますが、任意の名前でも大丈夫です。)
Dependencies
| artifact |
|---|
| mysql:mysql-connector-java:5.1.39 |
Interpreter有効化
今度は、画面右上の歯車からInterpreterを有効化します。
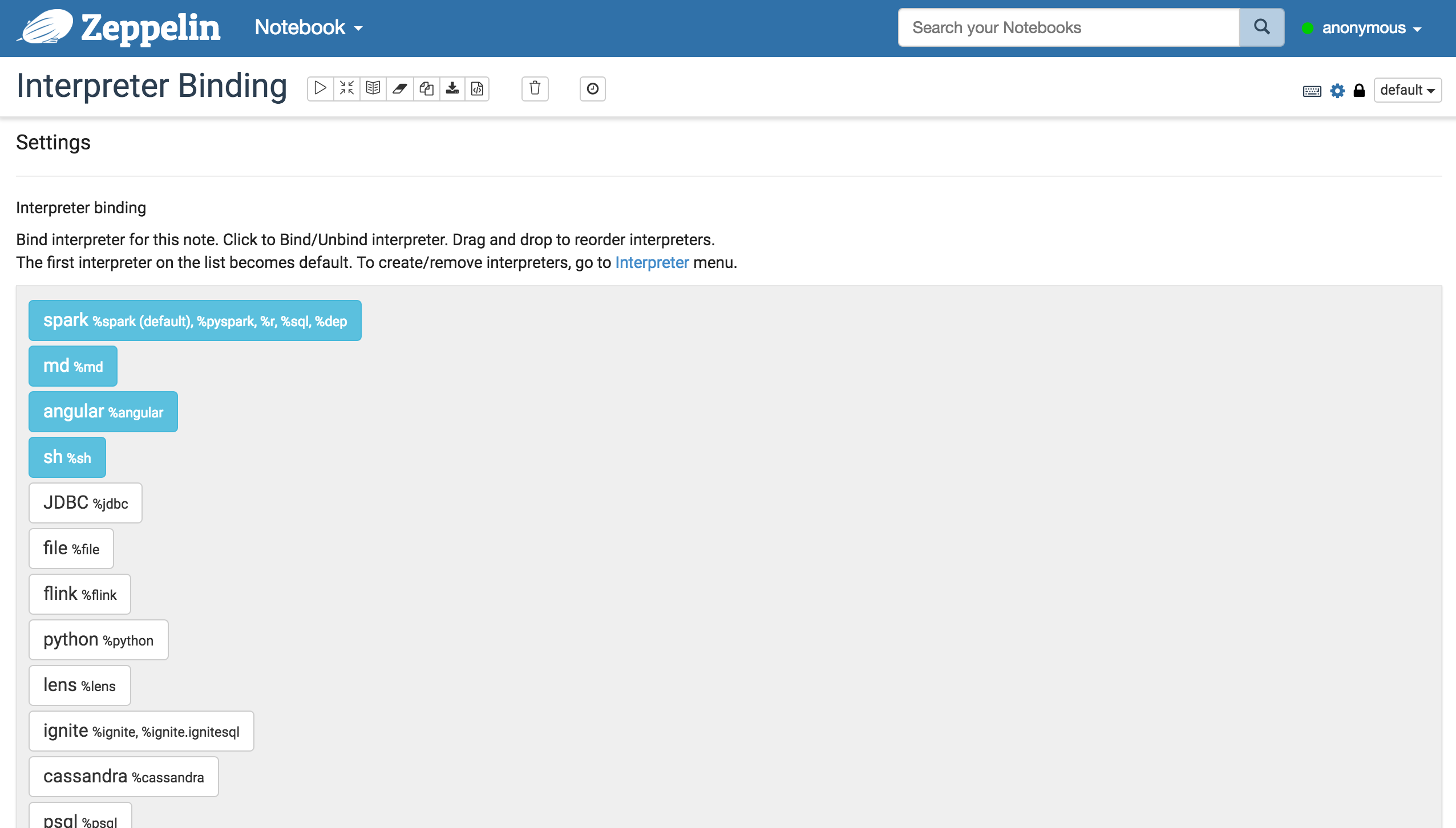
%jdbcを有効にしてください。
SQL実行
Interpreterの設定が出来たら、notebookのセルにクエリを書くだけで実行出来ます。
Zeppelinの良い所は、クエリの結果がそのままグラフになるところですね。
%jdbc(mysql)
SELECT created_at, sum(amount)
FROM report
GROUP BY shop
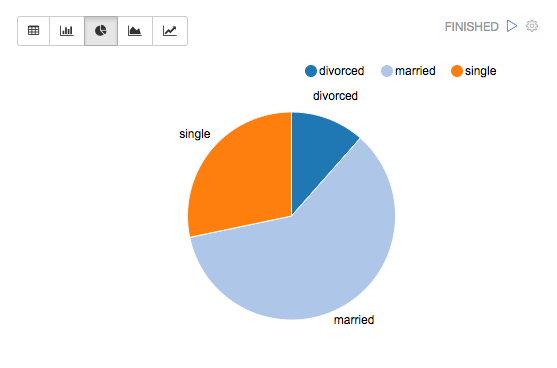
(SQLとグラフは適当なものです。イメージです。)
Redshiftとの接続
jdbcドライバー準備
%jdbcは先ほどインストールしたので、jdbcドライバーのみダウンロードして配置します。
cd /usr/lib/zeppelin/lib/
wget https://s3.amazonaws.com/redshift-downloads/drivers/RedshiftJDBC42-1.1.17.1017.jar
Interpreter設定
画面右上のメニューで、Interpreterという所を開いて、%jdbcを設定します。
Properties
| name | value |
|---|---|
| redshift.driver | com.amazon.redshift.jdbc42.Driver |
| redshift.url | URLを入れてください。例(jdbc:redshift://hoge.ap-northeast-1.redshift.amazonaws.com:5439/fuga) |
| redshift.user | ユーザ名を入れてください |
| redshift.password | パスワードを入れてください |
Dependencies
| artifact |
|---|
| /usr/lib/zeppelin/lib/RedshiftJDBC42-1.1.17.1017.jar |
SQL実行
あとは、notebookのセルにクエリを書くだけです。
%jdbc(redshift)
SELECT created_at, sum(amount)
FROM report
GROUP BY shop
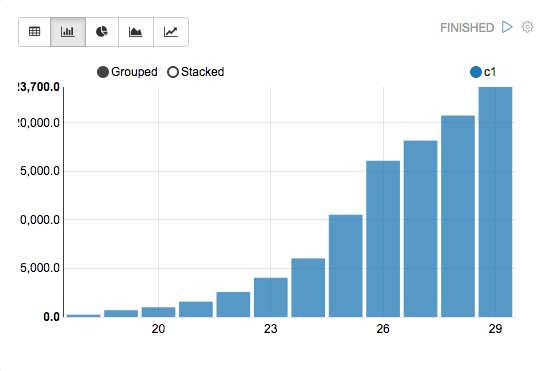
(SQLとグラフは適当なものです。イメージです。)
ちなみに、グラフはPivot chartになってたりします。
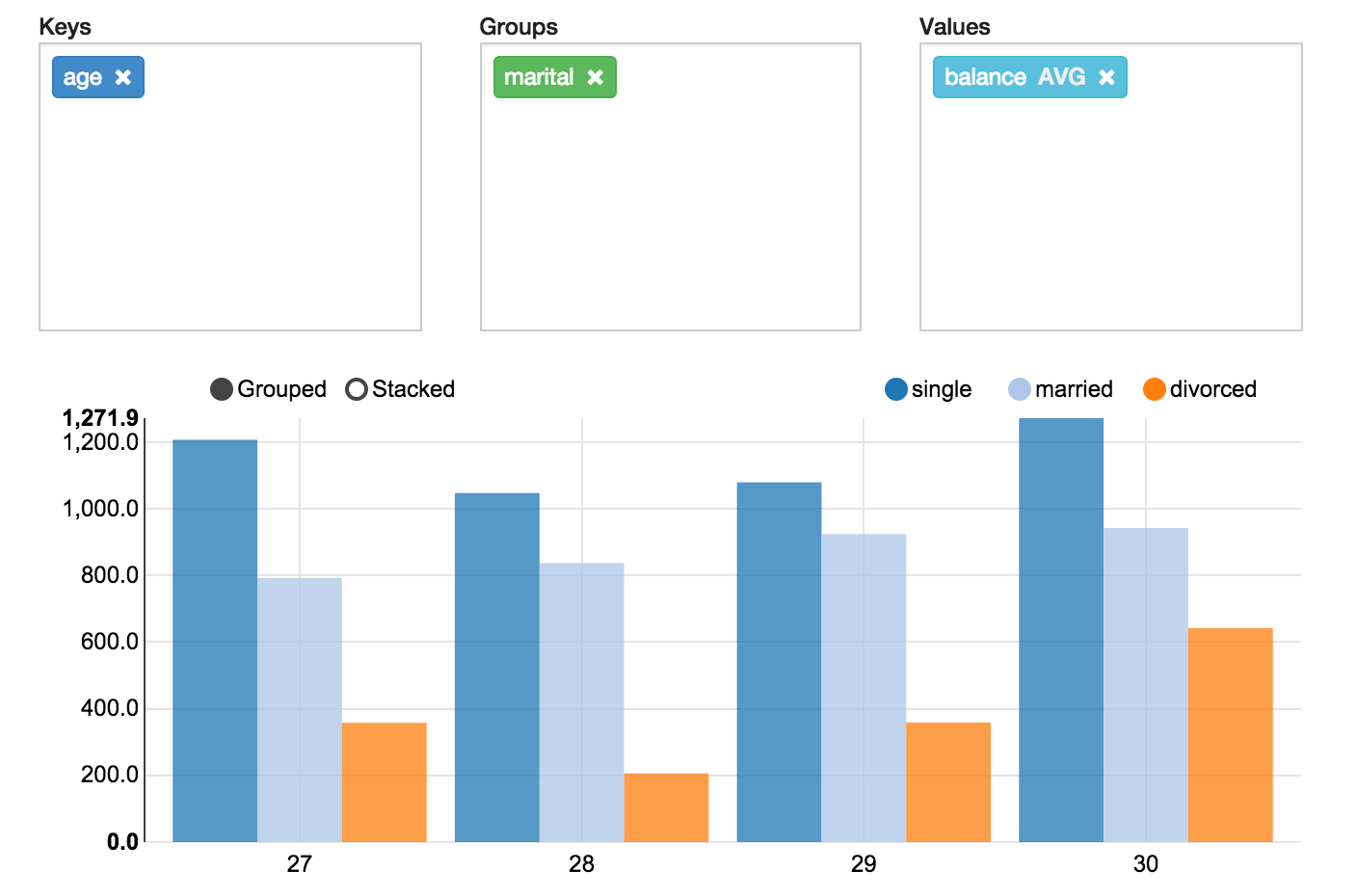
s3との接続
s3上にjsonファイルなどが配置してある場合、そのままsparkでロード出来ます。
import org.apache.spark.sql.SQLContext
val sqlContext = new SQLContext(sc)
val df = sqlContext.read.json("s3://hoge/fuga-*.gz")
パス部分には、ワイルドカートや正規表現が使えます。
gzで圧縮してあっても拡張子が付いていれば、そのまま読み込めます。
さらに、TempviewにするとSQLを使えます。
df.createOrReplaceTempView("df_view")
s3のデータをロードした、dfをviewにして
notebookのセルで、SQLを発行します。
%sql
SELECT created_at, sum(amount)
FROM df_view
GROUP BY area
(SQLとグラフは適当なものです。イメージです。)
全部混ぜる
RDSとRedshiftは、jdbcのInterpreterを使いましたが
sparkを使ってTempviewにすれば、全てを結合する事も出来ます。
val options = Map(
"driver" -> "com.mysql.jdbc.Driver",
"url" -> "jdbc:mysql://hoge.ap-northeast-1.rds.amazonaws.com:3306/fuga",
"user" -> "ユーザ名を入れてください",
"password" -> "ユーザ名を入れてください",
"dbtable" -> "テーブル名を入れてください"
)
val df = sqlContext.read.format("jdbc").options(options).load()
Zeppelinがあれば、RDS、Redshift、s3など何でも接続出来て
グフラもすぐに作れます。
EMRをVPCでprivateなネットワークに構築していれば、社内でもすぐに共有する事が出来ますね、
便利!!