MXNet で扱う主なオブジェクトの種類
MXNet で扱うオブジェクトとして、主に以下の4種類があります。
| オブジェクト | 概要 | Deep Learning における役割 |
|---|---|---|
| NDArray | 多次元配列 | データセットの保持 |
| Symbol | 多次元配列に対する操作 | ネットワークの定義 |
| Executor | Symbol に NDArray を結び付けたもの | forward/backward の実行 |
| Model | 学習済みモデル | 予測 |
上記のオブジェクトを利用して、以下の流れでモデルを作るのが(いろいろいじる場合の)基本となります。
- NDArray にデータセットを格納し、
- ネットワーク構造を Symbol で定義し、
- データセットとネットワーク構造を結び付け Executor を作成し、
- forward/backward を繰り返し学習を行い、
- 得られた学習済みモデル Model を利用して予測を行う。
各オブジェクトを使ってみる
データセットを作成する(NDArray)
a.data <- mx.rnorm(shape = c(2, 3), mean = 0, sd = 1, ctx = mx.cpu())
b.data <- mx.rnorm(shape = c(2, 3), mean = 0, sd = 1, ctx = mx.cpu())
data <- list(a = a.data, b = b.data)
> print(data)
$a
[,1] [,2] [,3]
[1,] 2.212206 0.7740038 1.0434403
[2,] 1.163079 0.4838046 0.2995635
$b
[,1] [,2] [,3]
[1,] 1.1839255 1.891711 -1.234741
[2,] 0.1530255 -1.168815 1.558071
データセットは NDArray の名前付きリストで表します。リストの各要素の名前は、この後に mx.symbol.Variable で作成する Symbol の名前と一致させます。
データセットに対する操作を定義する(Symbol)
a.sym <- mx.symbol.Variable("a")
b.sym <- mx.symbol.Variable("b")
c.sym <- a.sym * b.sym
d.sym <- a.sym + c.sym
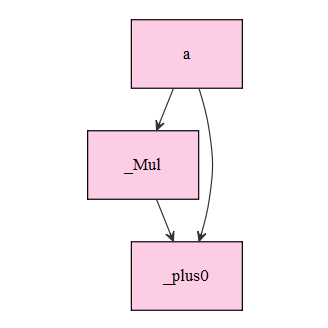
> graph.viz(d.sym$as.json(), graph.title = NULL, graph.width.px = 300, graph.height.px = 300)
mx.symbol.Variable で多次元配列のプレースホルダを作成し、それに対する操作を定義していきます。この段階では入力となる多次元配列の形状を指定する必要はありません。Symbol は多次元配列のように扱うことができるので、Symbol を仮の多次元配列とみなして + や * で式を書けば操作を定義することができます。
二項演算子の他に、mx.symbol.FullyConnected のようなネットワーク構造を定義する関数や、mx.symbol.Activation のような活性化関数なども用意されており、通常はそれらを組み合わせてネットワークを構築していきます。
Symbol は as.json で json 形式に変換できます。また、それを graph.viz に与えることで、計算グラフを可視化できます。上記の図で a だけ表示されて b が表示されないのは謎です……
図中の a _Mul _plus0 は各操作に対する名前です。名前を明示的につけなかった場合には、重複しないよう名前が自動的に割り振られます。上記の図では、_Mul や _plus0 が自動的に割り振られた名前です。
データセットと操作を結び付ける(Executor)
exec <- mx.simple.bind(symbol = d.sym, ctx = mx.cpu(), grad.req = "write", a = dim(a.data), b = dim(b.data))
mx.exec.update.arg.arrays(exec = exec, arg.arrays = data, match.name = T)
> print(exec$arg.arrays)
$a
[,1] [,2] [,3]
[1,] 2.212206 0.7740038 1.0434403
[2,] 1.163079 0.4838046 0.2995635
$b
[,1] [,2] [,3]
[1,] 1.1839255 1.891711 -1.234741
[2,] 0.1530255 -1.168815 1.558071
mx.simple.bind で入力データの形状を指定し、さらに mx.exec.update.arg.arrays で入力データを結び付けます。mx.simple.bind の grad.req には { "write", "add", "null" } の3種類を指定できるようですが、どう違うのかわかりませんでした…… null を指定すると微分できなくなります。普通は "write" を指定するっぽい。grad.req 以降には、mx.symbol.Variable で作成した Symbol の名前とその Symbol に結び付けるデータセットの形状をペアにして指定します。
計算する(forward)
mx.exec.forward(exec = exec, is.train = T)
> print(exec$outputs)
$`_plus0_output`
[,1] [,2] [,3]
[1,] 4.831294 2.23819566 -0.2449387
[2,] 1.341059 -0.08167335 0.7663047
mx.exec.forward で実際に計算を行います。mx.exec.forward の is.train は、勾配を求めるため計算過程を保持する必要がある場合に true にするものだと理解しました(要確認)。
微分する(backward)
mx.exec.backward(exec = exec, out_grad = mx.nd.ones(shape = c(2, 3), ctx = mx.cpu()))
> print(exec$grad.arrays)
$a
[,1] [,2] [,3]
[1,] 2.183926 2.8917112 -0.2347414
[2,] 1.153026 -0.1688148 2.5580711
$b
[,1] [,2] [,3]
[1,] 2.212206 0.7740038 1.0434403
[2,] 1.163079 0.4838046 0.2995635
mx.exec.backward で微分します。mx.exec.backward の out_grad には dd/dd = 1 を指定します。ちなみに、引数の out_grad という名前は僕が適当につけました。exec 以外なら、なんでもいいっぽいです(要確認)。結果を見ると、dd/da = b + 1、dd/db = a となっており、正しく微分できていることが確認できます。
Model の作り方、使い方
ToDo: 後で調べる。