背景
データ基盤は意思決定に使われて初めて価値を発揮する。データ基盤が適切に開発/運用されているかどうかをモニタリングしたい場合は、データ基盤が組織の意思決定にどの程度貢献したかを測定したい。が、それを測定するのは困難。
なので、今回はBigQueryを利用したデータ基盤において、それがどの程度利用されているかをモニタリングできるようにし、意思決定への貢献度の雰囲気とか空気感くらいはわかるようにしたい。
メタデータテーブルの永続化の必要
BigQueryの利用度をモニタリングする上で重要なのが、メタデータの永続化。
例えば、クエリジョブに関するメタデータを保存するビュー INFORMATION_SCHEMA.JOBS_BY_* は180日しか保存されない。長期スパンでのモニタリングを行うためにはこの辺りを永続化しておく必要がある。デイリーで、前日分のログを貯めておくなど。
モニタリング
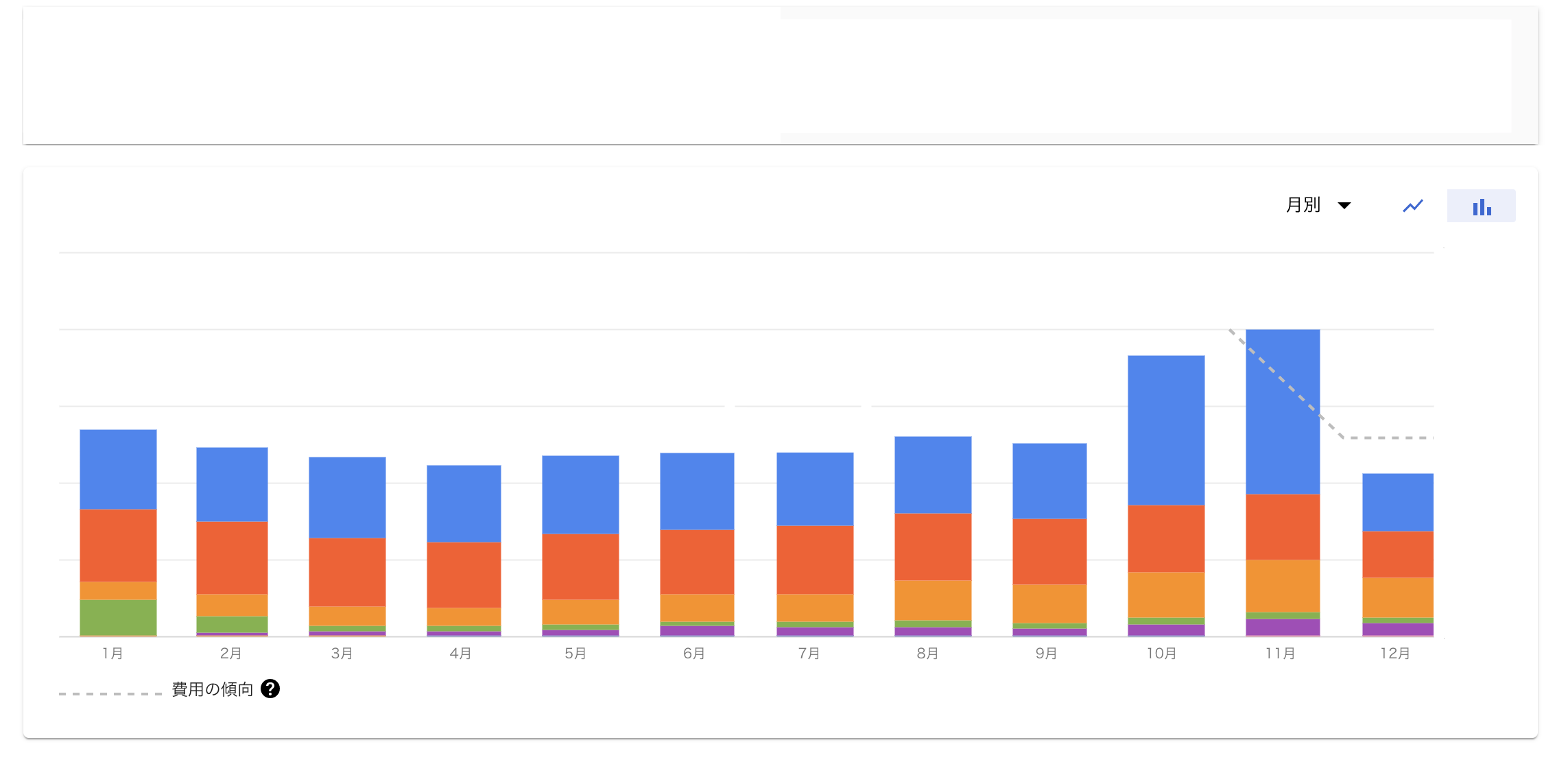
1.コストのモニタリング
コストのモニタリングは、GCPのお支払いレポートで十分だと思う。プロダクト毎のコストの推移や、デイリーのコストの推移も見れる。
2. ダッシュボード数 & ダッシュボードPV
データ基盤の活用が組織に広まると、活用される機会が多くなるダッシュボード。
定期的に参照されているダッシュボードが何個あって、どの程度PVがあるかを棚卸ししておくと活用度の推移が見えやすい。
TableauにはPV機能があるのでそれを利用。 Data Portalの場合はGAが埋め込めるのでそれを利用する。
3. クエリ実行UU
クエリを実行したアカウントのユニーク数をカウント。毎月何人くらいがBigQueryを参照しているか。
SELECT
DATE_TRUNC(DATE(creation_time, "Asia/Tokyo"), MONTH),
COUNT(distinct(user_email)) as uu,
FROM `region-us`.INFORMATION_SCHEMA.JOBS_BY_PROJECT
WHERE job_type = "QUERY"
AND state = "DONE"
GROUP BY 1
ORDER BY 1 ASC
4. クエリ量の推移
1ヶ月でどの程度スキャンされたか。別にこれが多いからいいとか、少ないからダメってわけではない。推移を見ながら利用がどう広がっているかは把握できる。
WITH base_tables as (
SELECT
job_id,
creation_time,
total_bytes_processed,
FROM `region-us`.INFORMATION_SCHEMA.JOBS_BY_PROJECT
WHERE job_type = "QUERY"
AND state = "DONE"
)
SELECT
DATE_TRUNC(DATE(creation_time, 'Asia/Tokyo'), MONTH),
COUNT(*)
FROM base_tables
GROUP BY 1
ORDER BY 1 asc
5. スキャン量の推移
1ヶ月でどの程度スキャンされたか。別にこれが多いからいいとか、少ないからダメってわけではない。推移を見ながら利用がどう広がっているかは把握できる。
WITH base_tables as (
SELECT
job_id,
creation_time,
total_bytes_processed,
FROM `region-us`.INFORMATION_SCHEMA.JOBS_BY_PROJECT
WHERE job_type = "QUERY"
AND state = "DONE"
)
SELECT
DATE_TRUNC(DATE(creation_time, 'Asia/Tokyo'), MONTH),
SUM(total_bytes_processed)
FROM base_tables
GROUP BY 1
ORDER BY 1 asc
6. データ量
点でしか取れない。デイリーで保存して推移を見たい。
SELECT
table_id,
SUM(size_bytes) / 1000000000 as size_GB
FROM (
SELECT * FROM `datasource1.__TABLES__`
UNION ALL
SELECT * FROM `datasource2.__TABLES__`
UNION ALL
SELECT * FROM `datasource3.__TABLES__`
)
GROUP BY 1
ORDER BY 2 desc
7. レコード数
点でしか取れない。デイリーで保存して推移を見たい。
SELECT
SUM(row_count)
FROM (
SELECT * FROM `datasource1.__TABLES__`
UNION ALL
SELECT * FROM `datasource2.__TABLES__`
UNION ALL
SELECT * FROM `datasource3.__TABLES__`
)
--GROUP BY 1
ORDER BY 1 desc