以前、Coursera Machine Learningの講座を受けたのですが、Pythonを使って実践してみようにもPython自体やライブラリ・実行環境といった周辺に対して知識が足りていないため、そのギャップを埋める為に講座の演習課題(ex1)をTensorFlowを使って実装してみました。
演習課題内容
線形回帰(linear regression)により、レストランの利益を予測するプログラムを実装します。具体的には、以下のように人口10,000人あたりの利益の学習データを元に、新しい店舗に対して予測するプログラムを実装する課題となります。
実行環境
Mac上の以下の環境で実行しています。
- python (3.6.0)
- numpy (1.12.0)
- matplotlib (2.0.0)
- jupyter (1.0.0)
- notebook (4.3.1)
- tensorflow (1.0.0)
環境は、すでにpyenvが入っていたので、その上でMinicondaを使って構築しています。
name: tensorflow
dependencies:
- python=3.6.0
- numpy=1.12.0
- matplotlib=2.0.0
- jupyter=1.0.0
- notebook=4.3.1
- six=1.10.0
- pip:
- tensorflow==1.0.0
$ pyenv install miniconda3-3.19.0
$ pyenv local miniconda3-3.19.0
$ conda env create --file env.yaml
$ pyenv local miniconda3-3.19.0/envs/tensorflow
なお、環境を作成した際に表示されるsource activate tensorflowをそのまま実行するとシェルごと落ちてしまうため、pyenvとanacondaを共存させる時のactivate衝突問題の回避策3種類を参考にpyenv localを使って環境を切り替えています。
TensorFlowでの実装
この演習では、人口$x$が与えられた際に利益を予測する仮説関数 (hypothesis) として、以下を仮定します。
h_{\theta}(x) = \theta_0 + \theta_1 x
また、最適なパラメーター$\theta_0$と$\theta_1$を求めるために、上記による予測が実際の学習データからどのくらいかけ離れているのかを表すコスト関数 (cost function) を以下のように定義します。これは、人口$x$に対する予測値と実際の利益$y$との差を2乗したものを、全学習データに対して平均を取ったものになります1。演習では、このコスト関数が最小となるような$\theta_0$と$\theta_1$を求めます。
J(\theta) = \frac{1}{2m}\sum^{m}_{i=1}(h_{\theta}(x^{(i)}) - y^{(i)})^2
- $x^{(i)}$: 学習データ内の$i$番目の人口データ
- $y^{(i)}$: 学習データ内の$i$番目の利益データ
- $m$: 学習データ数
コスト関数を最小化するために、最急降下法 (gradient descent) を使用します。これは、コスト関数の勾配を求めるために$\theta_0$と$\theta_1$の偏微分を取り、値が小さくなる方向へ$\theta_0$と$\theta_1$の値を更新していくことでコスト関数が最小となる点を求めます。
元の演習では、コスト関数と、コスト関数を$\theta_0$と$\theta_1$で偏微分することで勾配を求める関数をMATPLOT/Octaveの関数として実装して、その関数をfminuncといった最小値を求める関数に渡すことで、コスト関数を最小化する$\theta_0$と$\theta_1$を求めていました。
一方でTensorFlowを使う場合、このような関数を実装する代わりに、コスト関数や勾配に対するデータフローグラフを作成します。データフローグラフを作成した後、学習データを入力としてグラフを実行することで学習を実施します。
なんか前置きが長くなってしまいましたが、実際の処理を以降に記載します。
データの読み込み
まずは、以下のように人口と利益の値がカンマで区切られた学習データをファイルから読み込みます。
6.1101,17.592
5.5277,9.1302
8.5186,13.662
7.0032,11.854
5.8598,6.8233
8.3829,11.886
...
学習データのサイズが小さいため、一度にすべてのデータをメモリ上に読み込んでいます。
import numpy as np
data = np.genfromtxt('data/ex1/ex1data1.txt', delimiter=',')
input_X = data[:, 0]
input_y = data[:, 1]
np.genfromtxt()を実行すると、サイズが$m \times 2$の行列(numpyの2次元配列)としてdataに格納されます。numpyのスライス表記を使って、0列目と1列目をinput_Xとinput_yに代入しています。
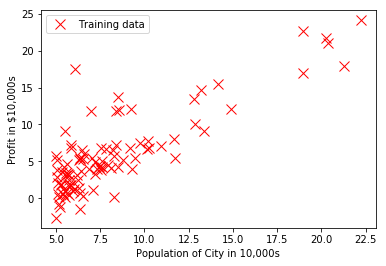
その結果をMatplotlibの散布図を使って表示します。
import matplotlib.pyplot as plt
plt.plot(input_X, input_y, 'rx', markersize=10)
plt.xlabel('Profit in $10,000s')
plt.ylabel('Population of City in 10,000s')
plt.plot()
plt.show()
データフローグラフの構築
次に、データフローグラフに対する入力データの人口Xと利益yをプレースホルダーとして定義します。また、学習されるパラメーターbiasとweightを変数として定義します。正確な説明ではありませんが、プレースホルダーはグラフの実行時に入力データを格納する入れ物を、変数は学習によって更新されていくパラメーターを表しています。
なお、TensorFlowのサンプル等に合わせて、前述の$\theta_0$をbias、$\theta_1$をweightという名前で定義しています。
import tensorflow as tf
X = tf.placeholder(tf.float32, name='X')
y = tf.placeholder(tf.float32, name='y')
weight = tf.Variable(0.0, dtype=tf.float32, name='weight')
bias = tf.Variable(0.0, dtype=tf.float32, name='bias')
これらのプレースホルダーと変数を使って、仮説関数を表すデータフローグラフを構築します。なお、データフローグラフをTensorBoardで可視化した際に分かりやすくするためにwith tf.namescope('hypothesis'):で囲ってグルーピングしていますが、必須ではありません2。
with tf.name_scope('hypothesis'):
h = weight * X + bias
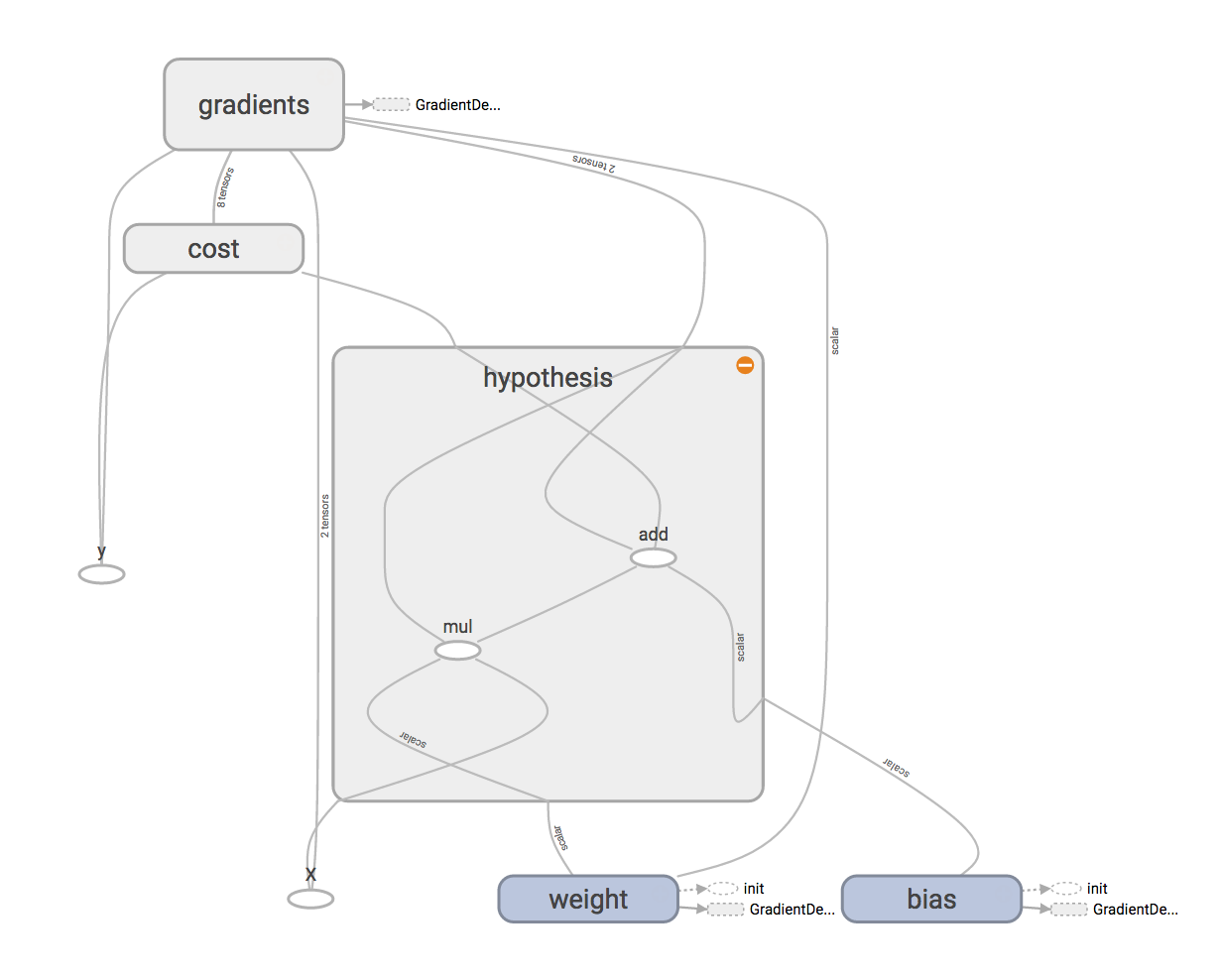
続いて、コストを計算するデータフローグラフを構築します。仮説関数による予測値と実際の値の差を2乗したものを平均しています1。TensorFlowでは、平均したり最大値を求めたりといった次元を削減する操作には、reduce_xxxという名前が付けられているようです。
with tf.name_scope('cost'):
square_delta = tf.square(h - y)
loss = tf.reduce_mean(square_delta) / 2
最後に、最急降下法を実行するデータフローグラフを構築します。ここでは、学習率$\alpha$として0.01を指定しています。この値が大きすぎると学習の結果は発散し、小さすぎると収束するまで時間がかかるようになります。
なお、元の演習では、偏微分により勾配を求める関数を実装していましたが、TensorFlowの場合には、optimizer.minimize()を実行することで自動的に計算してくれます。
alpha = 0.01
optimizer = tf.train.GradientDescentOptimizer(alpha)
train = optimizer.minimize(loss)
データフローグラフの実行
データフローグラフが構築されたため、実際にグラフを実行します。構築したグラフを実行するには、まずセッションを作成します。また、変数を利用する前に初期化が必要であるため、セッションの作成後にグラフ内のすべての変数を初期化します。
sess = tf.Session()
init = tf.global_variables_initializer()
sess.run(init)
これでデータフローグラフを実行する準備が整ったので、実際に学習する前に、とりあえず初期状態でのコストを計算してみます。コストを計算するには、コストを表すグラフの要素lossを指定してsess.run()を呼び出すことでグラフを実行します。feed_dictには、データフローグラフ内のプレースホルダーを読み込んだ学習データで置き換えるためのディクショナリを指定します。
feed_dict = {X: input_X, y: input_y}
print(sess.run(loss, feed_dict=feed_dict))
32.072735
続いて、実際に学習を実施します。この演習では、最急降下法による学習を1500回繰り返しています。
max_iterations = 1500
for i in range(max_iterations):
sess.run(train, feed_dict=feed_dict)
学習後にコストを計算してみると、約4.48となり、初期値に対するコスト32.07より小さくなっています。
print(sess.run(loss, feed_dict=feed_dict))
4.4833884
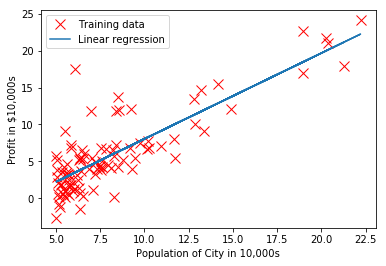
元のデータに対して仮説関数による予測結果をプロットしてみると、直線により近似されているのが分かるかと思います。また、学習後の仮説関数を使うことで、実際の予測ができます。
def predict(x):
return sess.run(h, feed_dict={X: x})
plt.plot(input_X, input_y, 'rx', markersize=10)
plt.xlabel('Profit in $10,000s')
plt.ylabel('Population of City in 10,000s')
plt.plot(input_X, predict(input_X), '-')
plt.legend(['Training data', 'Linear regression'])
plt.show()
predict1 = predict(3.5) * 10000
print('For population = 35,000, we predict a profit of %f' % predict1)
predict2 = predict(7.0) * 10000
print('For population = 70,000, we predict a profit of %f' % predict2)
For population = 35,000, we predict a profit of 4519.758224
For population = 70,000, we predict a profit of 45342.440605
TensorBoardによる可視化
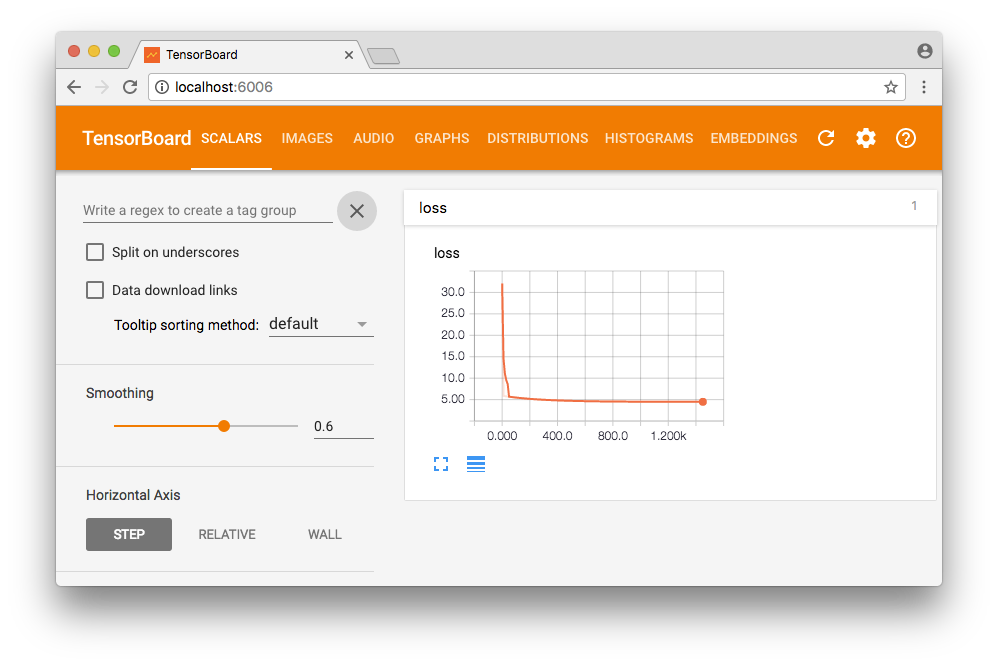
コストの可視化
TensorFlowには、TensorBoardという便利な可視化ツールが付随してきます。これを使って、10反復ごとにコストがどのように減少しているのかを可視化してみます。
可視化するには、tf.summryクラスを利用します。説明になっているのかどうかよく分かりませんが、サマリープロトコルバッファーを作成し、その内容をライターを通じてファイルに出力するという流れになります。
まずは、コストを表すlossに対するプロトコルバッファーを作成します。lossは1つの値しか持たないスカラー値なので、tf.summary.scalar()を呼び出します。その後、すべてのサマリープロトコルバッファーをマージしています3。
tf.summary.scalar('loss', loss)
merged = tf.summary.merge_all()
また、サマリーをファイルに出力するため、出力先ディレクトリを指定してファイルライターを作成します。出力先には、日時を含むディレクトリを指定しています。これにより、プログラムを複数回実行した場合でも、どの実行に対する結果をTensorBoard上で表示するかを選択できるようになります。
import os
from datetime import datetime
def subdir(base='logs'):
return os.path.join(base, datetime.now().strftime('%Y%m%d-%H%M%S'))
logdir = 'logs/ex1'
writer = tf.summary.FileWriter(subdir(logdir), sess.graph)
あとは、実際に10反復ごとにサマリーを出力するように修正します。
max_iterations = 1500
for i in range(max_iterations):
if i % 10 == 0:
summary, _ = sess.run([merged, loss], feed_dict=feed_dict)
writer.add_summary(summary, i)
sess.run(train, feed_dict=feed_dict)
学習の実行後、コマンドラインからTensorBoardを起動します。起動時に表示されたURLにブラウザでアクセスすることで、"SCALARS"タブで10反復ごとのコストのグラフを確認できます。
$ tensorboard --logdir logs/ex1
Matplotlibの結果をTensorBoardで表示
必要性があるかどうかは別にして、Matplotlibの表示結果を以下のようにイメージとして保存することで、TensorBoardの"IMAGES"上に表示させることができます。
buf = io.BytesIO()
plt.savefig(buf, format='png')
buf.seek(0)
image = tf.image.decode_png(buf.getvalue(), channels=4)
image = tf.expand_dims(image, 0)
summary_op = tf.summary.image('plot', image)
summary = self.sess.run(summary_op)
self.writer.add_summary(summary, max_iterations)