iTunes楽曲データ3万曲分析したい
高校の頃第2世代iPodを買ってから自分はiTunesのファンになったわけですが、そのころからせっせと自分の音楽CDをiTunesに取り込んでいったわけです。途中何度かクラッシュして再度音楽を入れ直すという苦行を強いられバックアップの大切さをはじめて知らしめてくれた存在でも有りました。
そんなiTunesも10年来の付き合いなので、曲数も溜まりに溜まってます。iTunesはtsvで曲ごとの再生回数などのデータを書き出すことができるので今回Pandasに取り込んでデータの分析をしてみます。
プレイリストの書き出し方法
Macでは
メニューバー→ライブラリ→プレイリストを書き出しでtsv形式のテキストデータで書き出すことが可能です。
書き出し形式は標準テキストやunicode、XMLなどが選択できます1
iTunesライブラリデータ全体の概要を把握する
まず今回使うデータとモジュールを準備します。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
file = 'MyAlliTunesSongs.xlsx'
# 1つ以上の値を列を持つデータを読み込み
df = pd.read_excel(file, header=0).dropna(how='all', axis=1)
# 後の処理のためにNaN変換
df = df.fillna({'再生回数': 0,'スキップ回数': 0, 'ジャンル': 'NoGenre'})
iTunesが各楽曲に対して保持しているデータは下記のとおりです。
名前、アーティスト、作曲者、アルバム、グループ、作品、楽章番号、楽章数、楽章名、ジャンル、サイズ、時間、ディスク番号、ディスク数、トラック番号、トラック数、年、変更日、追加日、ビットレート、サンプルレート、音量調整、種類、イコライザ、コメント、再生回数、最後に再生した日、スキップ回数、最後にスキップした日、ラブ、保存場所
ラブの有無はtsvで書き出しされません。これはAppleはAppleMusicを運営しているので他社に流用されないようにしておきたい情報ということでしょう。こういうところからも企業戦略が伺えます。
Pandasのinfo()で概略を見ます。
print(df.info()
'''
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 30415 entries, 0 to 30414
Data columns (total 25 columns):
名前 30415 non-null object
アーティスト 30374 non-null object
作曲者 8806 non-null object
アルバム 30355 non-null object
グループ 605 non-null object
作品 30 non-null object
ジャンル 28863 non-null object
サイズ 30415 non-null int64
時間 30415 non-null int64
ディスク番号 23703 non-null float64
ディスク数 23256 non-null float64
トラック番号 30255 non-null float64
トラック数 25345 non-null float64
年 29626 non-null float64
変更日 30415 non-null datetime64[ns]
追加日 30415 non-null datetime64[ns]
ビットレート 30415 non-null int64
サンプルレート 30400 non-null float64
音量調整 55 non-null float64
種類 30415 non-null object
コメント 653 non-null object
再生回数 4272 non-null float64
最後に再生した日 4274 non-null datetime64[ns]
スキップ回数 4806 non-null float64
最後にスキップした日 4734 non-null datetime64[ns]
dtypes: datetime64[ns](4), float64(9), int64(3), object(9)
memory usage: 5.8+ MB
'''
30,415曲...我ながらよくエンコしたものです。
この中にはTOEICのCDなんかも入っていて多少水増しされていますが、それでも大量です。
floatやNaNになっていると不具合のある箇所があるため手直しします。
df = df.fillna({'再生回数': 0,'スキップ回数': 0, 'ジャンル': 'NoGenre'})
df['再生回数'] = df['再生回数'].astype(int)
df['スキップ回数'] = df['スキップ回数'].astype(int)
3万曲以上も持っていて一体どのくらい聴いているのか気になったので調べました。
# 再生回数が1回以上の曲を書き出す
playtimes = 1
print(F"{len(df):,}曲中{(len(df[(df['再生回数'] >= playtimes)])):,}曲が{playtimes:,}回以上再生しています。")
print(F"{len(df):,}曲に対する再生率(最低でも{playtimes}回は聴いた)は{len(df[(df['再生回数'] >= playtimes)]) / len(df) * 100:,.1f}%です。")
'''
30,415曲中4,272曲が1回以上再生しています。
30,415曲に対する再生率(最低でも1回は聴いた)は14.0%です。
'''
14%でした。何回かクラッシュしているのと、iTunesの再生回数管理は曲の末端まで行った瞬間に1カウントなので実際はもっとちゃんと聴いている(はず)です。
続いてライブラリ全体の相関を散布図マトリクスとヒートマップで見ていきます。
plt.figure(figsize=(20, 12))
sns.pairplot(df,markers="+").savefig('seaborn_pairplot')
plt.figure(figsize=(20, 12))
cr = 'サイズ 時間 ディスク番号 ディスク数 トラック番号 トラック数 年 ビットレート 再生回数 スキップ回数'.split()
cr_matrix = df[cr].corr()
sns.heatmap(cr_matrix,annot=True,square=True,fmt='.2f',annot_kws={'size': 10},yticklabels=cr,xticklabels=cr,cmap='Blues')
plt.savefig('seaborn_heatmap_dataframe')

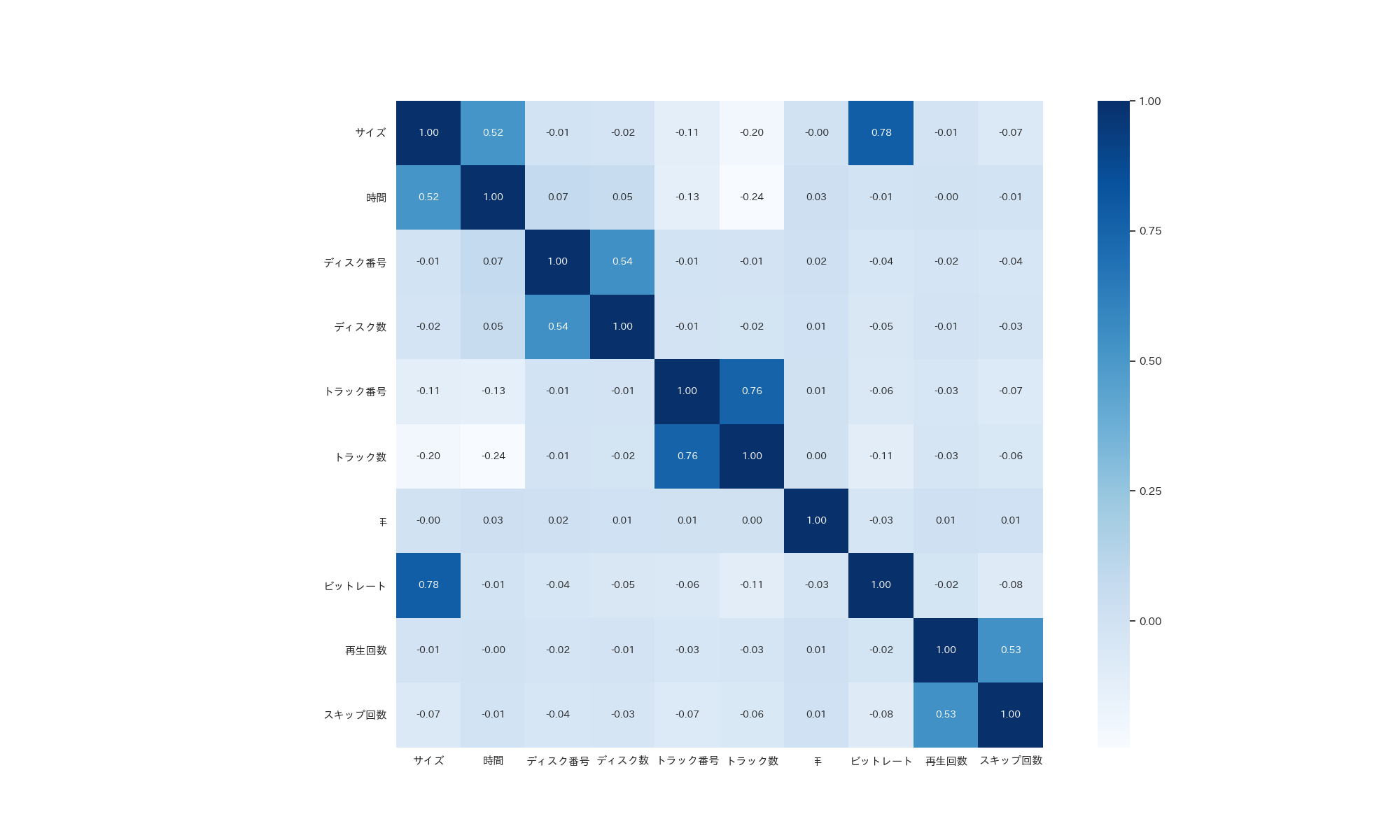
眺めてみるとサイズと時間、サイズとビットレート、トラック数とトラック番号、再生回数とスキップ数に強い相関が出ているようですが、これは当然の結果ですね。
しかし、エンコードの種類には
Mpeg3AACLossless
などいくつか種類があります。
これらのエンコーダの種類によって各相関に違いがあるのか見ていきます。
エンコードの種類に依る相関を見る。
一般的にビットレートとサイズの違いは比例するので、それがエンコードの種類によって変わるのか散布図と95%信頼区画の回帰直線で見ます。
sns.lmplot(x="ビットレート", y="サイズ", hue="種類", truncate=True, height=10, data=df, ci=95, markers=['+','+','+','+'])
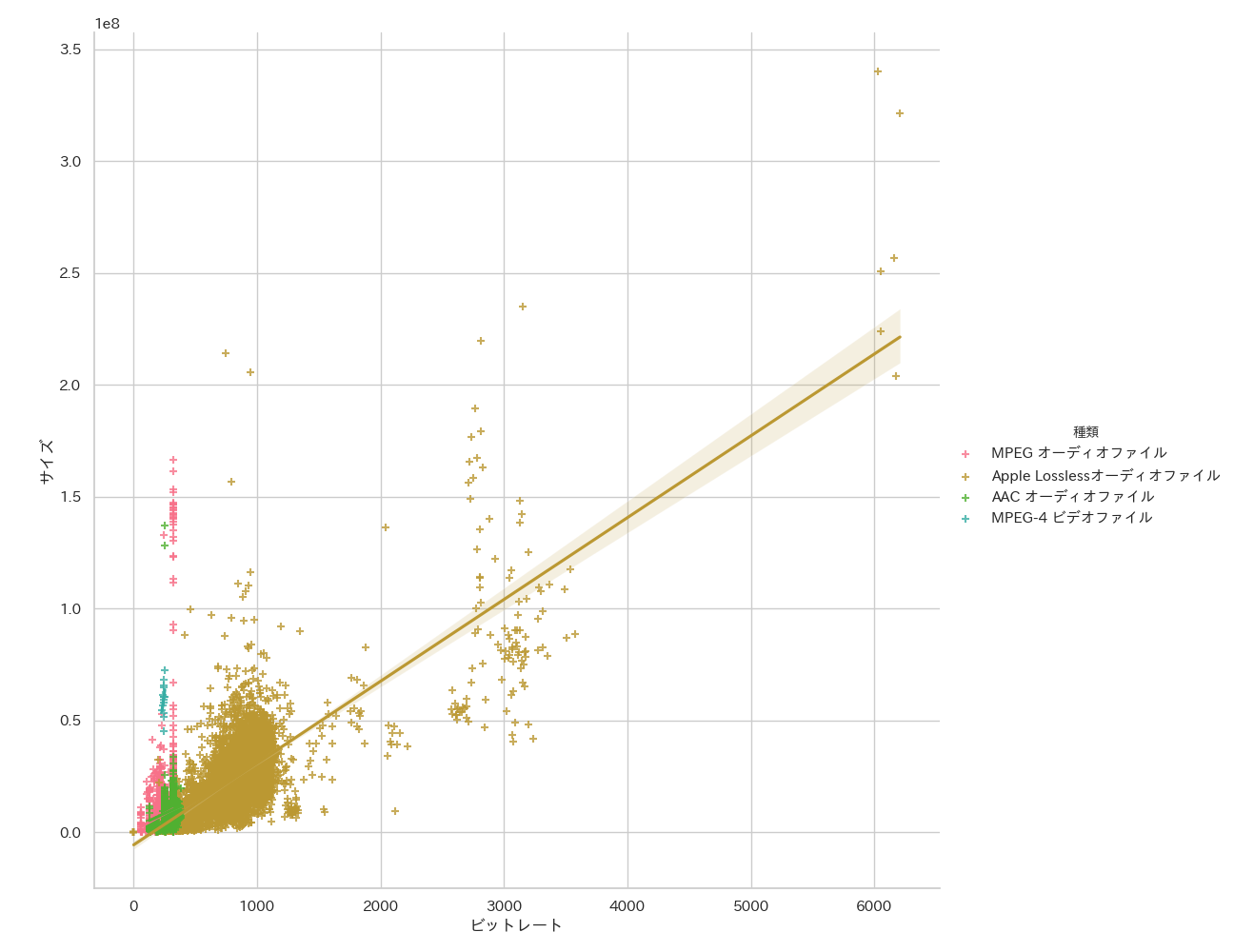
Losslessは外れ値があるためグラフが見にくくなっています。ここは1,500程度で切ってしまいましょう。
df02 = df[(df['ビットレート'] < 1_500)]
sns.lmplot(x="ビットレート", y="サイズ", hue="種類", truncate=True, height=10, data=df02, ci=95, markers=['+','+','+','+'])
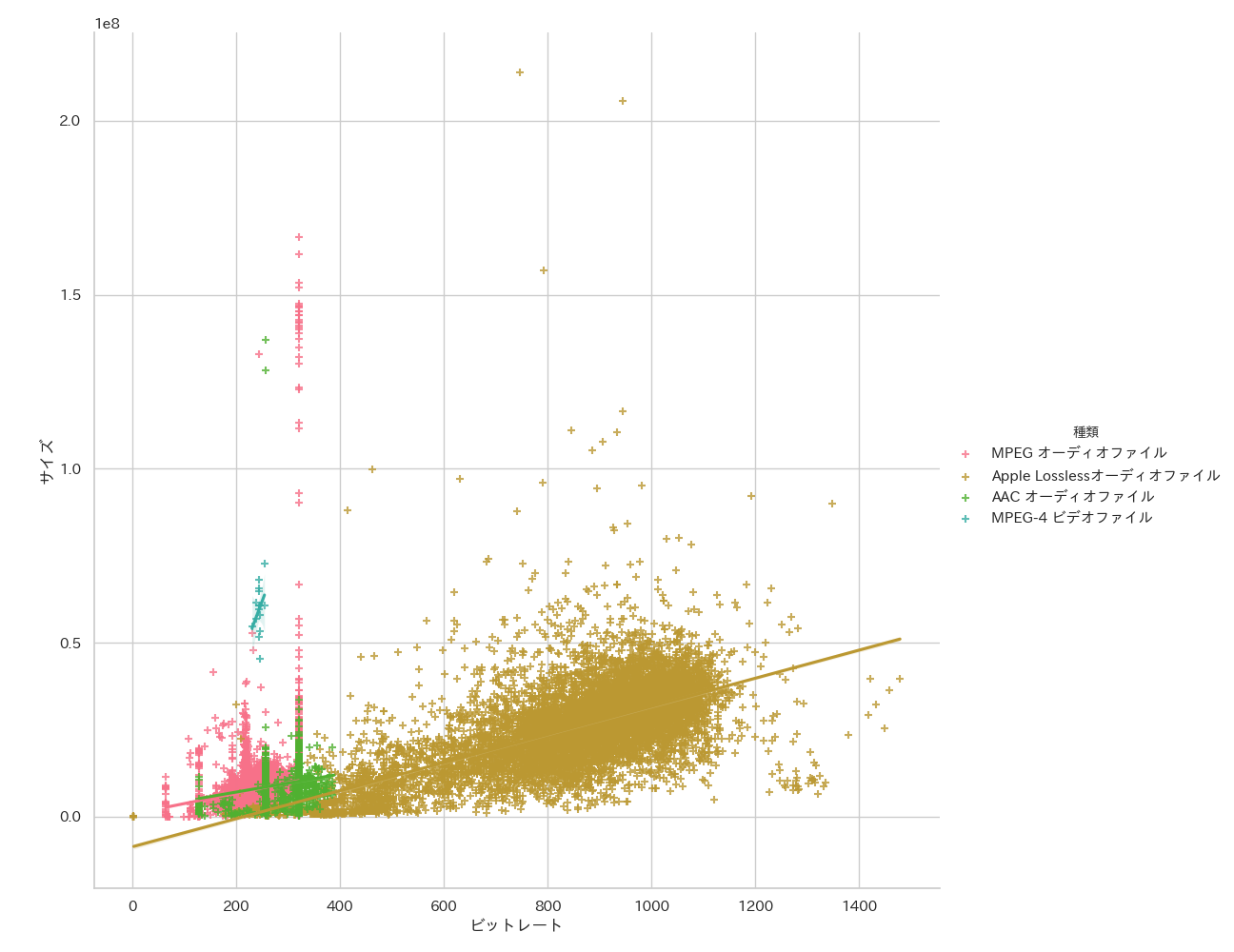
エンコードの種類によって圧縮率が変わってくることがわかりますね。
よく使われるビットレートは256~320bpsであり、イヤホンで聴く限り音質に大差がなくなるのは320bpsまで2
なので、ここはもっと良く詳細を見るために思い切って400未満、サイズは25メガ未満にしてみましょう。
df02 = df[(df['ビットレート'] < 400)&(df['サイズ'] < 25_000_000)]
sns.lmplot(x="ビットレート", y="サイズ", hue="種類", truncate=True, height=10, data=df02, ci=95, markers=['+','+','+','+'])
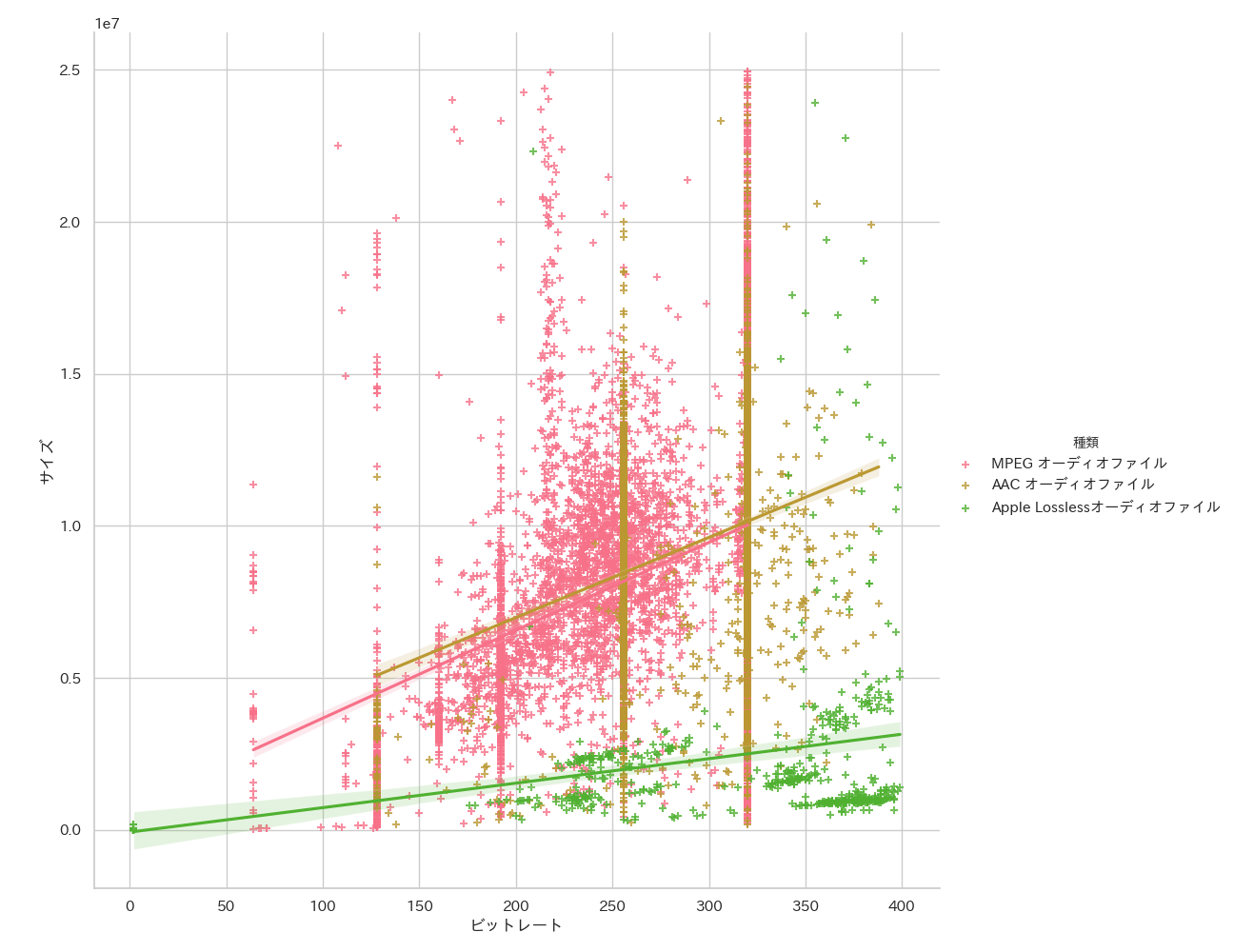
明らかにMpeg3とAACの回帰直線が似通っていますね、これはAACがMpeg3に近い圧縮率で音質はそれ以上を目指し開発された経緯からも納得できるものです。
AACとMpeg3をもっと詳しく見ていきます。
df03 = df.set_index('種類').drop(index=['Apple Losslessオーディオファイル', 'MPEG-4 ビデオファイル']).reset_index()
sns.lmplot(x="ビットレート", y="サイズ", hue="種類", truncate=True, height=10, data=df03, ci=95, markers=["+", 'o'])
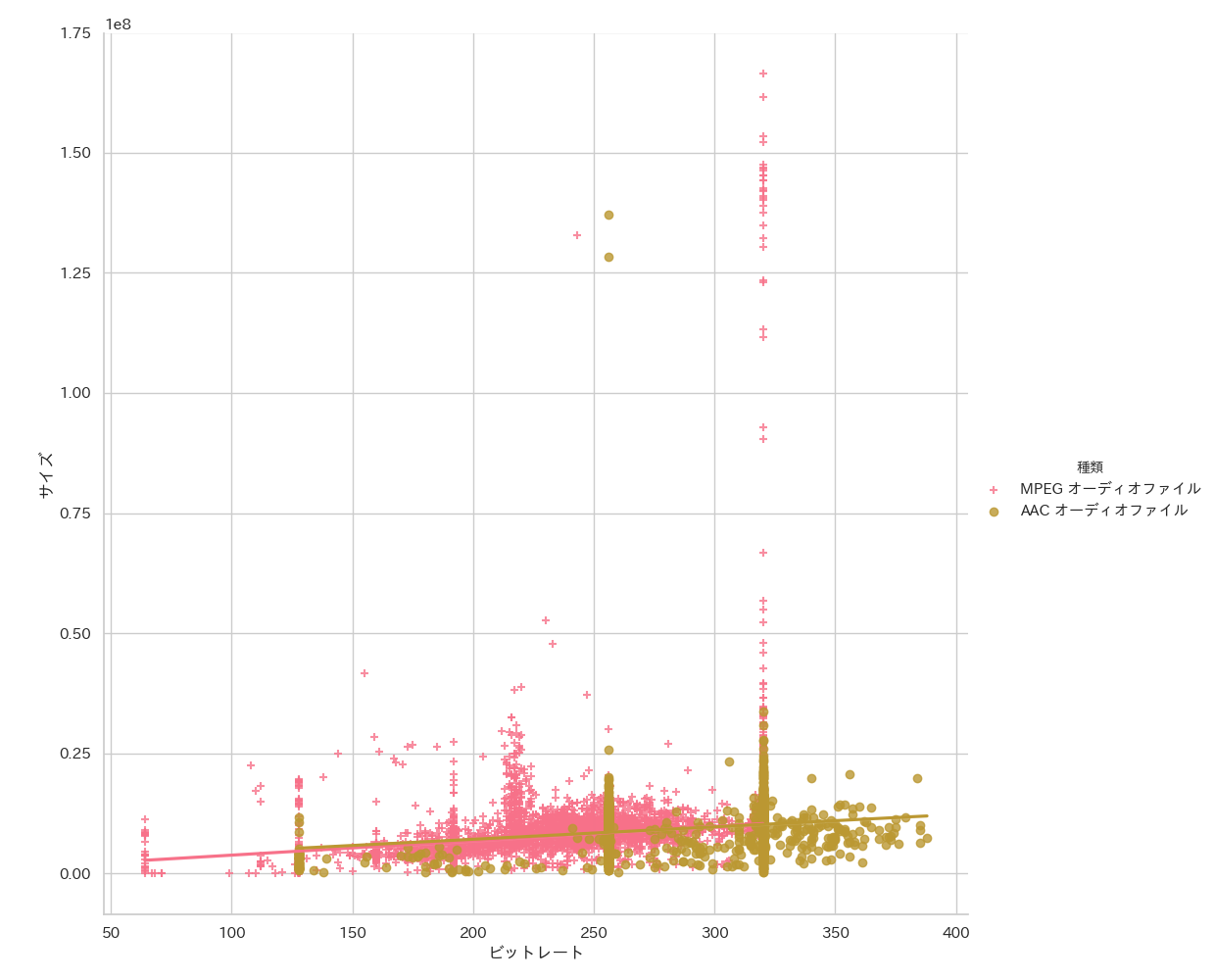
先程サイズとビットレート範囲を制限した相関は見たので今回はあえて外れ値を含んでプロットしています。
こうしてみるとMpeg3はAACと比べ320bps付近でのパフォーマンスがとても悪くなっていることがわかります。3
AACは256bps付近での品質が極端に苦手な場合があるようです。しかし総じて優秀と言えるでしょう。
しかしながらサイズは曲調やエンコーダの品質にも依るため、このデータのみでは断言することができないということを付け加えさせていただきます。
まとめ
自分が持っているライブラリだけでも結構な情報が見て取れました。
次はAppleMucicのように、自分のライブラリから趣味嗜好を分析していきたいと思います。
詰まったこと
Seabornの中の挙動が見えないため、インデックスの指定方法を気をつけないといけないということに気がつくまでかなりの時間を浪費してしまった。
Swarmplotやviolinplotなどテスト用のミニデータだと成功したが、本番用でデータが多すぎるとスタックしてしまうグラフもあるため、間引き方法や平均値最頻値を取るかなどその処理が課題。NaN変換、float intの変換を始めに行っておくことが大切。まず最初にデータを俯瞰することはもっと大切だと学んだ。
-
Pandasのエンコードでどう対策してもエラーになっためxlsx形式に変換したものを使用しています。 ↩
-
本来音質は同一の曲を用いて一定条件下で数値化して計測比較すべきなのですが、なぜかオーディオ雑誌でも「より深い音がする、ヌケが良い」など非常にアナログ的な表現を持って比較されているのが現状です。これはピュアオーディオファンが非常にアナログにこだわってる...産業的背景から音楽はデジタル化されてきたが音楽とは本来絵画や料理と同じアナログなものであり絶対に評価を数値化できるものではない...という強い思想が見て取れるのです。 ↩
-
また、230bps付近も圧縮が苦手な場所であると言えるでしょう。しかしながら、私は8年くらい前PCの容量が逼迫していた時Mpeg3で可変ビットレートを好んで利用していた時期があり(いまでも悔やみます)、このためAACが顕在化していないだけだとも言えそうです。市場の評価ではMpeg3は高ビットレートになればなるほど苦手になり、AACは総じて優秀だが、苦手な曲調の場合にピンポイントで極端にパフォーマンスが落ちる傾向があるようです。また320bpsであれは両エンコードとも大差は感じられなくなります。昔はAACの再生がiTunesのみであったり、DRMの縛りがあったためMpeg3勢がおしていましたが、いまではAACも開放されDRMフリーも販売されていることで以前ほどではなくなりました。 ↩