はじめに
VoltDBの開発者向けの公式ドキュメントGuide to Performance and Customizationのまとめです。対象のバージョンはv8.3です。
正確に翻訳することや網羅することは目的ではないため、重要でない記述等は削除したり、不足部分は追記しています。
今回は3章です。
なお、本投稿のまとめ元である「Guide to Performance and Customization」のライセンスはAGPLであり、これらのまとめ投稿はAGPLが適用されます。
また、他にもVoltDBの開発者向けの公式ドキュメントUsing VoltDBをまとめています。
・3. データベースの起動
・7. アプリケーション開発の簡略化
・9. クラスタでVoltDBを使用する
・13. VoltDBデータベースの保存と復元
第3章 VoltDBの実行計画
3.1 SQL文の実行計画をVoltDBが選択する仕組み
VoltDBは、ストアドプロシージャまたはアドホッククエリを解析し、SQL文の実行計画を検討する。
テーブルのスキーマ、パーティション列、索引に基づき、SQLを最も効率的に実行する計画を選択する。
VoltDBはコンパイル時に実行計画を生成する。SQL文に対してテーブルの結合順序を指定することもできる。
3.2 VoltDBの実行計画について理解する
VoltDBは、ストアドプロシージャの実行計画をスキーマとともにデータベースに格納する。
実行計画を確認する方法は以下の3つがある。
-
@Explainまたは@ExplainProcシステムプロシージャーを呼び出す。 - sqlcmdのexplainまたはexplainprocディレクティブを使用する。
- VoltDB Management Centerの「スキーマ」タブで確認する。
これらは全て同じ実行計画を出力する。
@ExplainProcシステムプロシージャーとsqlcmdにexplainprocディレクティブでは、ストアド・プロシージャで定義されたすべてのSQL文の実行計画が出力される。
Explainディレクティブと@Explainシステム・プロシージャを使用すると、クエリのテキストを入力して、アドホッククエリの実行計画を確認できる。
以下は、VoltDB Management Centerの「スキーマ」タブで確認した結果。
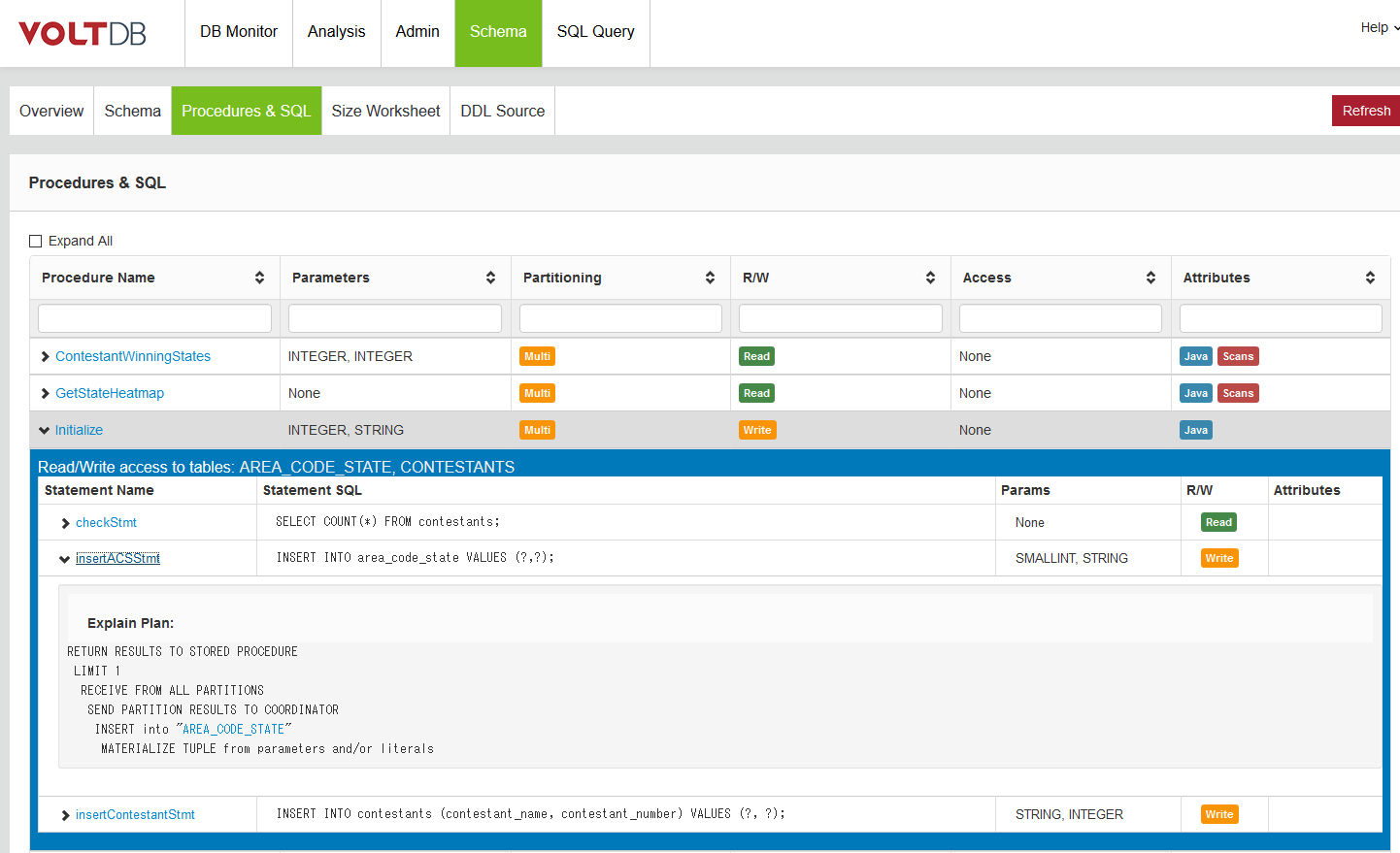
- 3.3 実行計画を読み、SQL文を最適化する
実行計画はVoltDBがステートメントを実行方法を順番に表したもの。
実行順序は実行計画の下から上になる。
例えば、VoterサンプルアプリケーションのInitializeストアドプロシージャのInsertACSStmtの実行計画は以下になる。
このSQLでは、area_code_stateテーブルに市外局番(area_code_state)をINSERTしている。
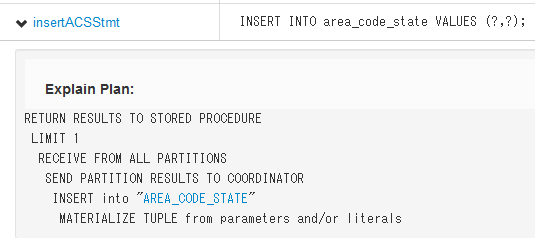
下から順番に読むと
- 入力値かリテラル値からレコードを作成する。
- area_code_stateテーブルにレコードをINSERTする。
- マルチパーティションプロシージャなので、各パーティションは結果をcoordinatorに送信する。
- coordinatorは、全てのパーティションから結果を受け取り、結果を1行にまとめ、その値をストアドプロシージャに返す。
次の例(VoterサンプルアプリケーションのcheckContestantStmt)
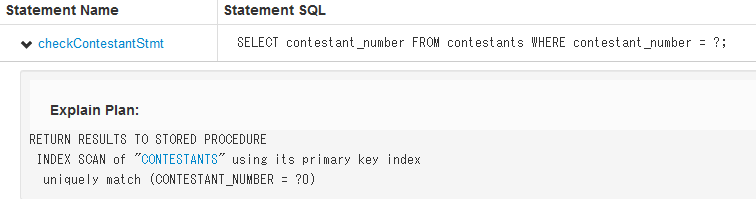
CONTESTANTSテーブルのスキャンで主キー索引が使用されている。
パーティションテーブルおよびプロシージャでもあるため、結果はストアドプロシージャに直接返す。
次の例(VoterサンプルアプリケーションのcontestantTotals)
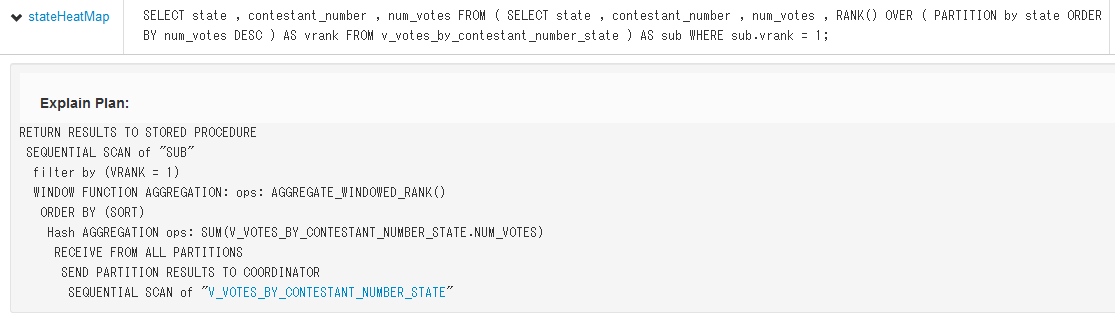
この例はマルチパーティションストアドプロシージャの実行計画。
- 各パーティションで、v_votes_by_contestant_number_stateテーブルのシーケンシャルスキャンを実行する。
- 各パーティションの結果を、マルチパーティションのトランザクションを調整するイニシエーターに返す。
- 集計関数を使用して、contestantごとにすべてのパーティションのvoteを合計(SUM)する。
- 結果をソートし、最後に、結果をストアドプロシージャに返す。
3.3.1 インデックスの評価
インデックスを変更するかクエリの結合順序を変更することによって、データアクセスを向上させる。
実行計画を利用してデータベースアプリケーションを最適化できる。
パーティション列の情報を使用して、シングルパーティションストアドプロシージャ実行に必要なパーティションを決定する。
ただし、その列のレコードにアクセスするためのインデックスは自動的には作成されない。
たとえば、Hello Worldの例では、HELLOWORLDテーブルの主キー(DIALECT)を削除すると、Select文の実行計画も変更される。
変更(削除)前:
RETURN RESULTS TO STORED PROCEDURE
INDEX SCAN of "HELLOWORLD" using its primary key index
uniquely match (DIALECT = ?0)
変更(削除)後:
RETURN RESULTS TO STORED PROCEDURE
SEQUENTIAL SCAN of "HELLOWORLD"
filter by (DIALECT = ?0)
変更前は索引付きスキャンで、変更後はシーケンシャルスキャンになっている。
索引があるテーブルへのINSERT、UPDATEはオーバーヘッドがある。
索引は、すべてのクエリに必要なわけではなく、レコード数が少ないテーブルやめったに起こらないクエリの場合、不要なオーバーヘッドになる可能性がある。
ただし、ほとんどの場合、特に大規模なテーブルに対する頻繁なクエリでは、適切な索引がないと、パフォーマンスに深刻な影響を与える可能性がある。
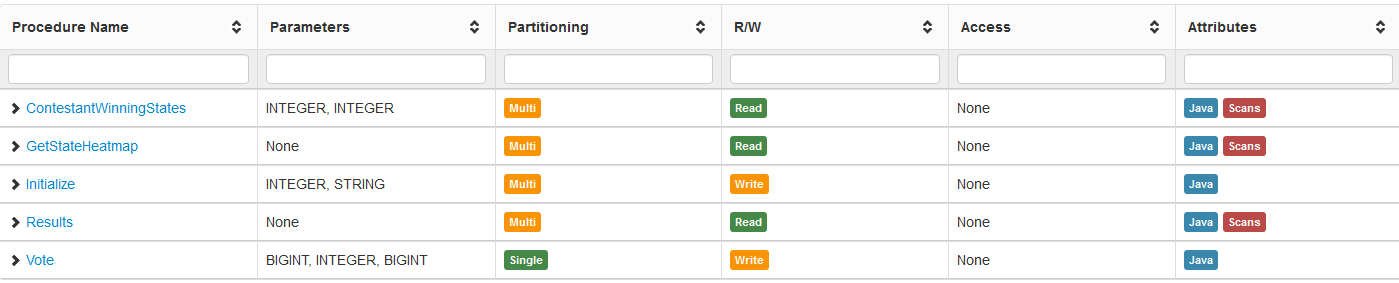
VoltDBデータベースアプリケーションをチューニングするときに役立つステップとして、予期しないシーケンシャル(索引なし)スキャンのスキーマを確認すること。
VoltDB管理センターでは、シーケンシャルスキャンを含む場合に"Scan"アイコンが表示され簡単に確認できる。
3.3.2 テーブルの結合順序の評価
実行計画が提供するその他の情報は、テーブルが結合される順序がある。
結合順序はパフォーマンスにしばしば影響する。
通常、2つ以上のテーブルを結合するときは、最初に一致するレコードの数が最も少ないテーブルをスキャンする。
それにより他の条件を検討するときに評価する比較が少なくなる。
ただし、コンパイル時には個々のテーブルのサイズに関する情報がないため、テーブルスキーマ、クエリ、索引のみに基づいて実行計画は推測される。
そのため、最適な結合順序が選択されないことがある。
複数テーブルを結合で最適な結合順序がわかっている場合は、結合順序を指定することができる。
結合順序をSQLStmtの2番目の引数を指定する。
以下では、"manager,dept,emp"が結合順序の指定になる。
この例ではテーブルに別名がついており、その場合は引数には別名を指定する。
また、クエリ中で6テーブル以上を結合する場合、結合順序を指定しないとコンパイル時にエラーになる。
public final SQLStmt FindEmpByMgr = new SQLStmt(
"SELECT dept.dept_name, dept.dept_id, emp.emp_id, " +
"emp.first_name, emp.last_name, manager.emp_id " +
"FROM MANAGER, DEPARTMENT AS Dept, EMPLOYEE AS Emp " +
"WHERE manager.emp_id=? AND manager.dept_id=dept.dept_id " +
"AND manager.dept_id=emp.dept_id " +
"ORDER BY emp.last_name, emp.first_name",
"manager,dept,emp");
参考
Using VoltDB @ExplainProc
https://docs.voltdb.com/UsingVoltDB/sysprocexplainproc.php