HoloLensでリアルタイム翻訳
前回、前々回で紹介した方法を使い、HoloLensでリアルタイム翻訳を実施します。構築したアプリケーションとしては、以下の機能を有するものです。
- 翻訳したい言語、翻訳後の言語、合成音声出すかをUIで設定
- レコーディング開始を実行するとリアルタイム翻訳開始
- レコーディングを止めるまでマイクの音声を集約する。
- 翻訳できたデータはHoloLens上でテロップ&音声出力
以上のような簡単なものです。ただ、実をいうと音声出力はよくないと思います。というのも、スピーカーから出すとマイクで集音されてしまうのでただの雑音になり精度を下げる要因になります。お試しで使う形になるかと思います。動作させるとこのような形で動きます。
とりあえずの最終版のHoloLensリアルタイム翻訳アプリの動作状況。現状のTranslator Speech APIが使えると思われる設定だと音声品質の問題で認識率が落ちてる気がします。#HoloLensJP pic.twitter.com/xBww80Ch6N
— takabrz (@takabrz1) 2017年5月16日
今回の環境
環境については以下の通りです。
- IDE
- Unity 5.5.0f3
- Visual Studio 2015 update 3 Community Edition
- ライブラリ関連
- HoloToolkit-Unity 1.5.5.0
- Naudio 1.8.8.0(合成音声の再生のみで利用)
実装について
前回、前々回でライブラリ化しているので、実態としてはそれをそのまま利用する形になります。ただ、音声については多少の加工を行っているのでそのあたりを紹介したいと思います。
- Unityでの実装(UI)
- 音声処理の実装
- UWP側の実装(前々回作成のライブラリを参照したアプリの実装)
事前作業について
事前作業としてAzureのCognitive Serviceとして「Translator Speech API」の追加を行ってください。追加後SubscriptionKeyの控をお忘れなく。
1. Unityでの実装(UI)
UnityのUIとしては3つのパラメータの設定、翻訳のスタート&ストップです。
パラメータについてはそれぞれ以下の情報を設定します。
| query | 設定値 |
|---|---|
| from | 入力する音声の言語 |
| to | 翻訳する言語 |
| voice | 合成音声のId |
合成音声を返さない場合は未設定とします。それぞれのパラメータは前々回の「2. サポート言語の取得」でえられるデータのIDに相当する値となります。
今回は適当にこんなUIにしてみました。
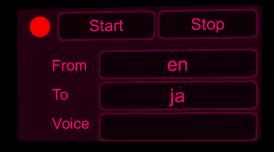
また、翻訳結果をテロップ表示するためのテキストも用意します。のちに作るMicrophoneInput.csの中で利用するものでサンプルでは「TranslateText」としてprefabにしています。表示後少ししてから上に移動しながらフェードアウトするように処理を入れています。
上記はいずれもnGUIでつくりました。Canvasの設定については操作系はTagalongを利用しました。テロップはカメラ追従で実装しています。
2. 音声処理の実装
オブジェクトの設定
次にマイクからの集音処理部分の実装です。
UnityのHierarchyで「create」-「Audio」-「Audio Source」を選択し「Audio Source」を追加します。あと、Projectで「create」-「Audio Mixer」を選択し「Audio Mixer」も追加します。
まず、「Audio Mixer」-「Master」を選択し、Inspectorの設定項目「Volume」を-80dbに設定します。
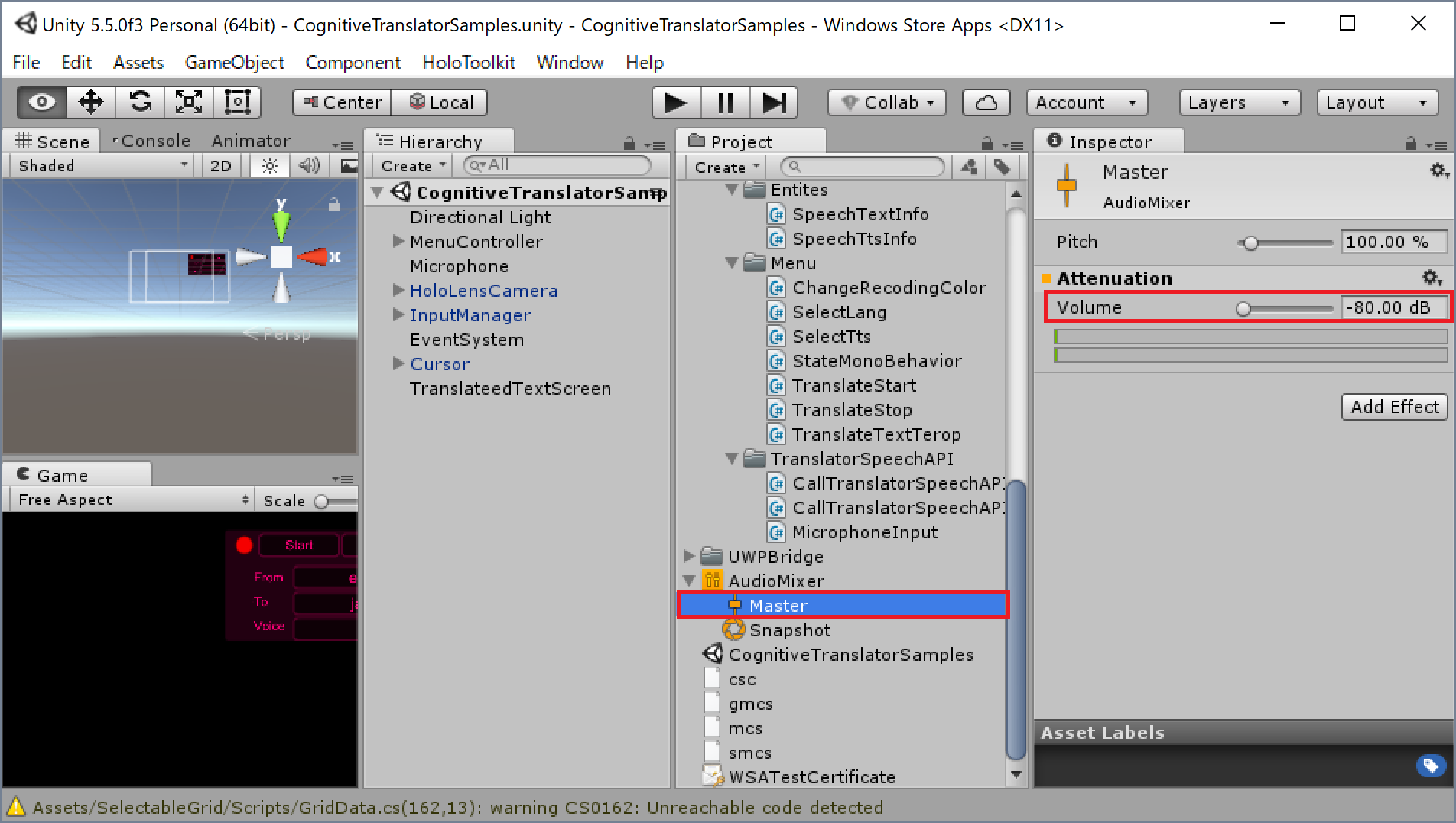
次にHierarchyで「Audio Source」を選択し、Inspectorの設定項目「output」に先ほどの「Master」をドラッグ&ドロップします。これはスピーカーから自分のマイク音声を出力しないための設定です。なお「Audio Clip」については後でプログラム側で設定するのでそのままにしておきます。
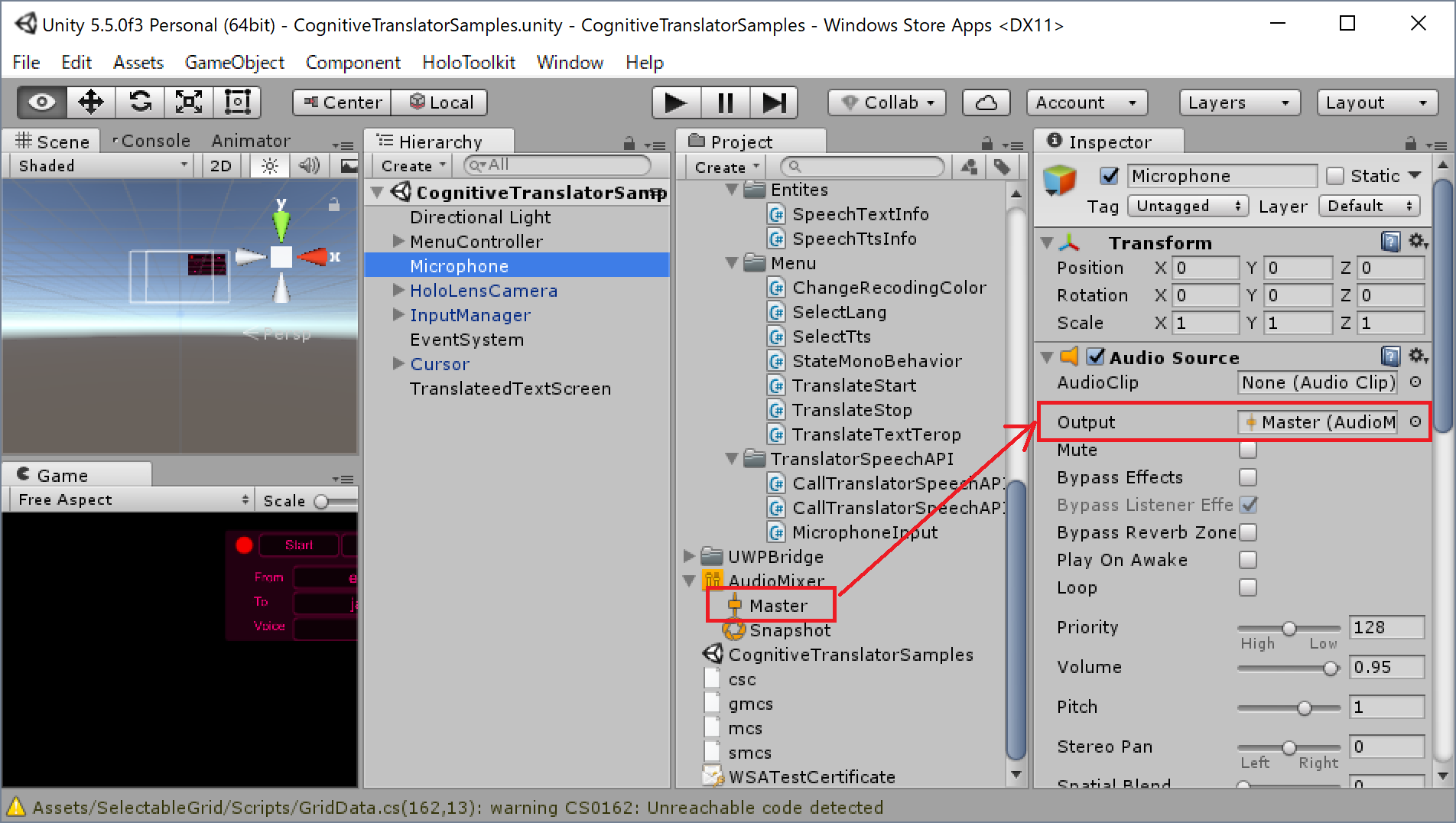
初期化処理
次に「Audio Source」の処理を書きます。Project内にC#Scpirtを作成します。
Startメソッドでは、前々回のUWPのサンプルコードを参考にTranslator Speech APIのサービスへの接続処理を書きます。
UWPで作ったプロジェクト(Com.Reseul.Apis.Services.CognitiveService.Translators.UWPプロジェクト)をそのまま利用するのが楽ですが、この場合一旦Unityでビルドを行いUWPに変換してから追記する必要があります。
翻訳結果の表示
翻訳結果の表示については前々回のUWPのサンプルコードを参考にサービスの翻訳結果のうちJSONの内容を加工し「TranslateText」をインスタンス化して
画面に表示します。
マイクの集音開始/終了及びデータの送信
次にマイクからの集音開始と終了及びデータの送信部分を作成します。
マイクの集音開始
マイクの集音開始については以下のように実装します。このメソッドは先ほど作ったUIのStartボタンで呼び出されるように実装します。
処理内容としては前回と同じ実装内容になります。今回はHolotoolkit-Unityは使用せずにUnityのみで実現しています。
// Copyright(c) 2017 Takahiro Miyaura
// Released under the MIT license
// http://opensource.org/licenses/mit-license.php
audio = GetComponent<AudioSource>();
audio.clip = Microphone.Start(deviceName, false, 999, MicSampleRate);
audio.loop = true;
while (!(Microphone.GetPosition(deviceName) > 0))
{
}
//recording start.
audio.Play();
マイクの集音終了
マイクの集音終了はMicrophoneInput.ServiceStopメソッドで実装します。このメソッドは先ほど作ったUIのStopボタンで呼び出されるように実装しています。
こちらの処理内容も前回と同じ実装内容になります。
// Copyright(c) 2017 Takahiro Miyaura
// Released under the MIT license
// http://opensource.org/licenses/mit-license.php
audio.Stop();
Microphone.End(deviceName);
集音データの送信
次に集音データの送信を行います。処理はMicrophoneInput.OnAudioFilterReadメソッドで実装します。こちらも基本的な部分は前回と同じ実装内容になります。
異なるのは、以下の2点です。
- Translator Speech APIへ送信するためのリサンプリング
- Translator Speech APIサービスにデータを送信
リサンプリングについては、HoloLensで集音すると48Khz,2chの品質でサンプリングされます。ですが、経験上(確認中ですが)Translator Speech APIは16Khz,1ch,16bitで送るのがよさそうなので、リサンプリングを行っています。リサンプリングは単純にデータを間引く対応を行っています。間引き方は単純で48/16*2=6個のデータ毎に平均をとって配列を再構成します。waveデータはfloatの配列で取得できるのですが、ステレオの場合、この配列の偶数が右チャネル、奇数が左チャネルとなります。今回はステレオからモノラルの変換も兼ねているので単純にまとめて処理しています。リサンプリングしたデータは16bitで量子化したうえでTranslator Speech APIに送信します。
なお、この辺りの処理が単純すぎるので認識率の低下につながってる可能性もあります(データ劣化を起こしている)。
// Copyright(c) 2017 Takahiro Miyaura
// Released under the MIT license
// http://opensource.org/licenses/mit-license.php
/// <summary>
/// Read sampling Data from Microphone.
/// </summary>
/// <param name="buffer">Sampling Data.</param>
/// <param name="numChannels">number of audio channels.</param>
private void OnAudioFilterRead(float[] buffer, int numChannels)
{
if (!_isStart) return;
lock (this)
{
Debug.Log("samplingDataSize:" + buffer.Length);
lock (lockObject)
{
// Resampling datas from microphone(ex:48000hz) to 16000hz.
var reduction = MicSampleRate / toSampleRate * numChannels;
var convBufSize = buffer.Length / reduction;
if (buffer.Length % reduction > 0) convBufSize++;
var convBuf = new short[convBufSize];
var count = 0;
float ave = 0;
while (count < convBufSize - 1)
{
ave = 0;
for (var j = 0; j < reduction; j++)
ave += buffer[count * reduction + j];
ave = ave / reduction * 20f;
convBuf[count] = FloatToInt16(ave);
count++;
}
ave = 0;
for (var j = count * reduction; j < buffer.Length; j++)
ave += buffer[j];
ave = ave / (buffer.Length + count * reduction + 1);
convBuf[count] = FloatToInt16(ave);
//Write send datas to Translator Speech API.
convBuf = null;
}
}
}
3. UWP側の実装(前々回作成のライブラリを参照したアプリの実装)
全てUnity上でできれば丸く収まるのですが、今回作成したものはUWPのライブラリですので、
UWP側で残りの実装を行います。
前々回のUWPのライブラリを利用した場合以下の6つの実装を行います。
- 初期化処理を接続の開始
- データの送信
- 合成音声可能な言語リストの取得(GetTtsInfoメソッド)
- 翻訳可能な言語リストの取得(GetTranslateLanguageInfoメソッド)
- 受信後(翻訳結果:テキスト)の処理(OnTextMessageメソッド)
- 受信後(翻訳結果:合成音声)の処理(OnVoiceMessageメソッド)
1. 初期化処理を接続の開始
ライブラリの初期化をTranslator Speech APIの接続を開始します。
この処理は録音開始のボタンの押下時に実行するように実装します。
ConnectメソッドにはUIで設定したfrom,to,Voiceを渡します。
// Copyright(c) 2017 Takahiro Miyaura
// Released under the MIT license
// http://opensource.org/licenses/mit-license.php
service = new CognitiveTranslatorService(subScriptionKey);
service.OnTextMessage += OnTextMessage;
service.OnVoiceMessage += OnVoiceMessage;
service.Connect(from, to, voice);
コンストラクタの引数にはAzureのサブスクリプションキーを渡します。
2,3行目は送信した翻訳データを受信した際に呼び出すメソッドを割り当てる処理となります。
2. データの送信
接続の完了後音声データを送信する処理は以下の通りです。Unityの方で音声データを集音した際にはデータは16bitのサンプリングデータに変換します。サービスへの送信についてはこれをByteの配列に変換します。データはリトルエンディアンになりますので注意してください。
// Copyright(c) 2017 Takahiro Miyaura
// Released under the MIT license
// http://opensource.org/licenses/mit-license.php
var convertBytes = ConvertBytes(samplingData);
var buffer = convertBytes.ToArray();
service.AddSamplingData(buffer, 0, buffer.Length);
// Copyright(c) 2017 Takahiro Miyaura
// Released under the MIT license
// http://opensource.org/licenses/mit-license.php
private IEnumerable<byte> ConvertBytes(short[] sampleData)
{
foreach (var s in sampleData)
{
var bytes = BitConverter.GetBytes(s);
yield return bytes[0];
yield return bytes[1];
}
}
3. 合成音声可能な言語リストの取得(GetTtsInfoメソッド)
Translator Speech APIでサポートしている合成音声の情報を取得します。これはUnity上のUIで値を選択するための情報として利用します。ライブラリではメソッドを1つ呼ぶだけで実施可能です。
// Copyright(c) 2017 Takahiro Miyaura
// Released under the MIT license
// http://opensource.org/licenses/mit-license.php
var speechTtsInfo = CognitiveTranslatorService.GetSpeechTtsInfo();
speechTtsInfo.Wait();
なお、ライブラリのGetSpeechTtsInfoは非同期のメソッドとして定義していますので、
レスポンスを同期的に処理するためにはWaitメソッドを用いて待機します。
4. 翻訳可能な言語リストの取得(GetTranslateLanguageInfoメソッド)
Translator Speech APIでサポートしている言語の情報を取得します。これはUnity上のUIで値を選択するための情報として利用します。
// Copyright(c) 2017 Takahiro Miyaura
// Released under the MIT license
// http://opensource.org/licenses/mit-license.php
var speechTtsInfo = CognitiveTranslatorService.GetSpeechTextInfo();
speechTtsInfo.Wait();
5. 受信後(翻訳結果:テキスト)の処理(OnTextMessageメソッド)
ここでは、翻訳後のデータが入ったJSONデータを解析してUnity側に描画します。JSONデータには音声から解析された原文と翻訳後の情報があります。今回は両方のデータを利用できるように文字列を加工しています。Unityへの描画についてはコメントの部分に記載を行います。
// Copyright(c) 2017 Takahiro Miyaura
// Released under the MIT license
// http://opensource.org/licenses/mit-license.php
rivate void OnTextMessage(object sender,
MessageWebSocketMessageReceivedEventArgs messageWebSocketMessageReceivedEventArgs)
{
var result = "";
using (var reader = messageWebSocketMessageReceivedEventArgs.GetDataStream())
using (var sr = new StreamReader(reader.AsStreamForRead(), Encoding.GetEncoding("UTF-8")))
{
result = sr.ReadToEnd();
var jsonObject = JsonObject.Parse(result);
var recognition = jsonObject["recognition"].GetString();
var translation = jsonObject["translation"].GetString();
//(translation + "\n[" + recognition + "]")
//ここでUnity側に値を表示するロジックを実装する。
}
}
6. 受信後(翻訳結果:合成音声)の処理(OnVoiceMessageメソッド)
ここでは、翻訳後の音声データとしてバイナリデータが送られた場合、スピーカーから発話します。音声周りはNAudioを利用して再生しています。
なお、発話するとスピーカーからの音声をマイクが集音することで雑音が増える結果になります。
// Copyright(c) 2017 Takahiro Miyaura
// Released under the MIT license
// http://opensource.org/licenses/mit-license.php
private void OnVoiceMessage(object sender,
MessageWebSocketMessageReceivedEventArgs messageWebSocketMessageReceivedEventArgs)
{
using (var reader = messageWebSocketMessageReceivedEventArgs.GetDataStream())
using (var stream = reader.AsStreamForRead())
using (var mStream = new MemoryStream())
{
var bufferSize = 32000;
var bytes = new List<byte>();
var buf = new byte[bufferSize];
var length = stream.Read(buf, 0, buf.Length);
while (length - bufferSize == 0)
{
bytes.AddRange(buf);
length = stream.Read(buf, 0, buf.Length);
}
if (length > 0)
bytes.AddRange(buf.Take(length).ToArray());
var fullData = bytes.ToArray();
mStream.Write(fullData, 0, fullData.Length);
mStream.Position = 0;
var bitsPerSampleBytes = fullData.Skip(34).Take(2).ToArray();
var channelBytes = fullData.Skip(22).Take(2).ToArray();
var samplingBytes = fullData.Skip(24).Take(4).ToArray();
var bitsPerSample = BitConverter.ToInt16(bitsPerSampleBytes, 0);
var channel = BitConverter.ToInt16(channelBytes, 0);
var samplingRate = BitConverter.ToInt32(samplingBytes, 0);
using (var player = new WasapiOutRT(AudioClientShareMode.Shared, 250))
{
player.Init(() =>
{
var waveChannel32 =
new WaveChannel32(new RawSourceWaveStream(mStream,
new WaveFormat(samplingRate, bitsPerSample, channel)));
var mixer = new MixingSampleProvider(new[] {waveChannel32.ToSampleProvider()});
return mixer.ToWaveProvider16();
});
player.Play();
while (player.PlaybackState == PlaybackState.Playing)
{
}
}
}
}
最後に
以上がHoloLensに組み込む際のポイントを残してみました。もう少しここはどうなってる?等ありましたら、コメントしていただければ返したいと思います。
なお、2017年5月からTranslator Speech APIが大幅値下げされています。お試しで使うとしてもかなりお得感があるので色々試してください。
私自身は、この翻訳アプリをDe:code 2017の基調講演で試行してみたいと思ってます。ただ、事前に映画見ながらも使っていたのですが「1.音声データの品質」「2.翻訳精度」の2つの問題から思ったようには翻訳されないことが多いです。かなり条件そろわないと難しい印象です。この辺り、他のTranslatorも少し使ってみようと思います。