経緯
昨日参加させて頂いたGCPの勉強会で、Dataflowのハンズオンをしていた際、
プロジェクトIDにバケットIDを設定して実行してしまったのが原因か、Dataflowがエラーで止まったままだったので、
復習がてらプロジェクトの作成からDataflowの実行までやり直してみました。
構築
補足
[your_project_id]と[your_backet]にはそれぞれ任意のプロジェクト名(ID)とバケット名を設定
プロジェクト新規作成
プロジェクトの選択から新しいプロジェクトを選択する
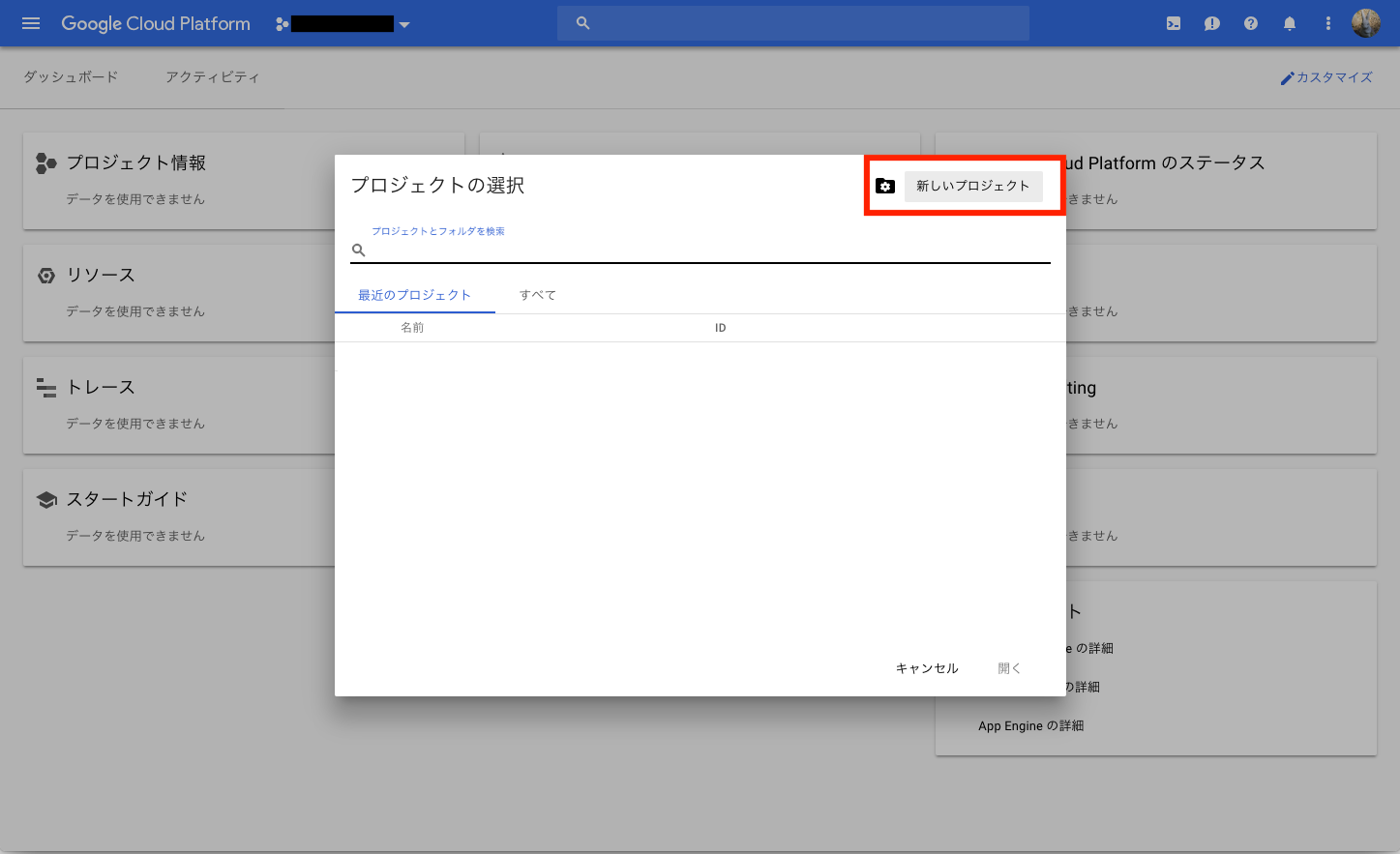
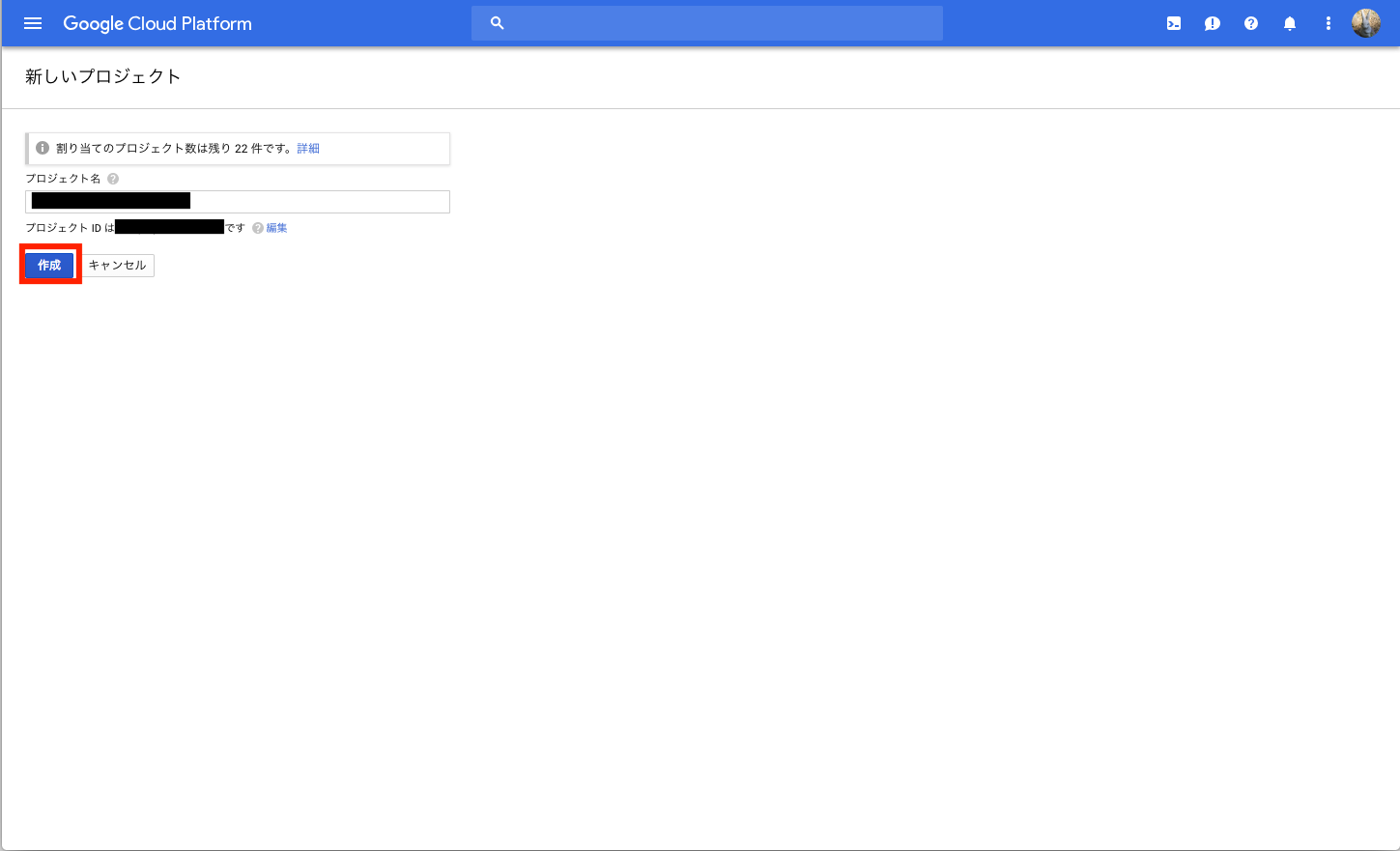
下記を設定及び選択して、作成を選択する
- プロジェクト名:[your_project_id]
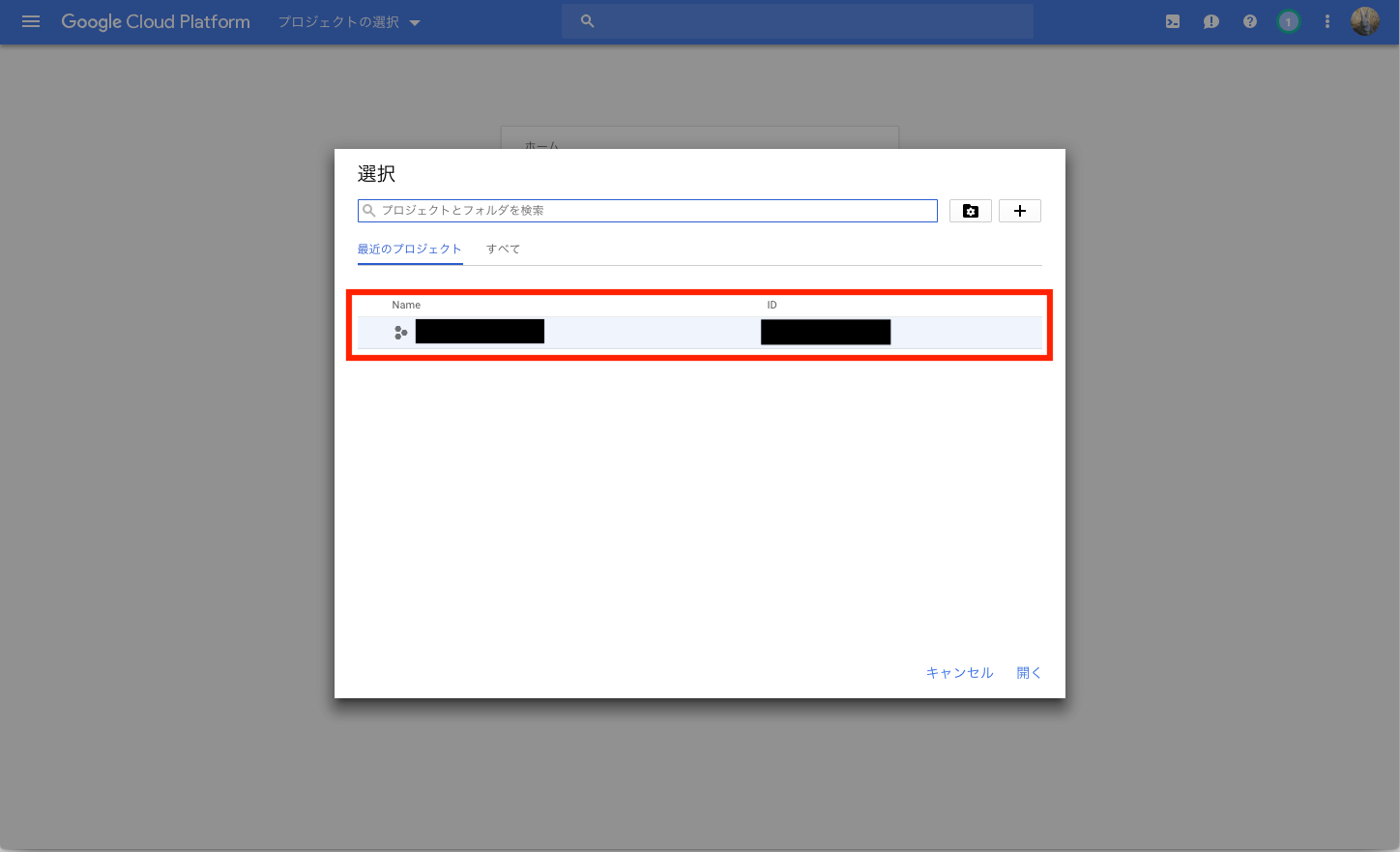
ダッシュボードから作成したプロジェクトを選択する
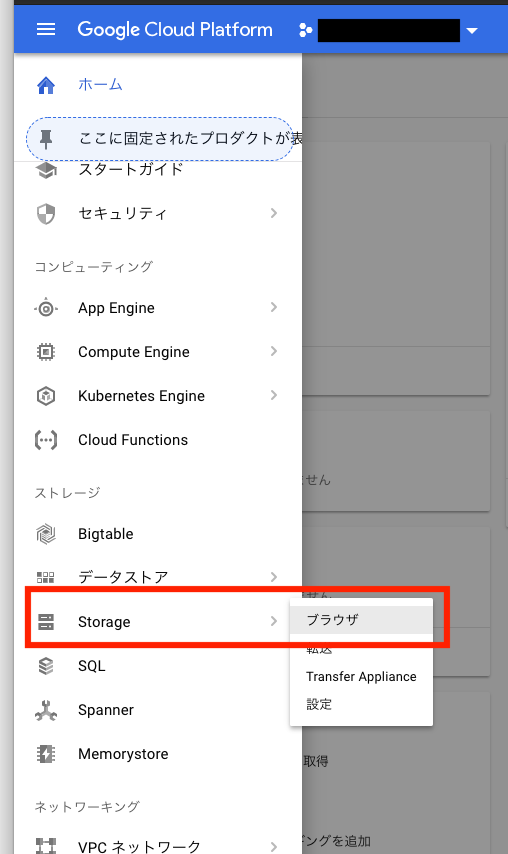
バケット新規作成
ナビゲーションメニューのストレージからStorageを選択し、ブラウザを表示する
バケットの作成を選択する
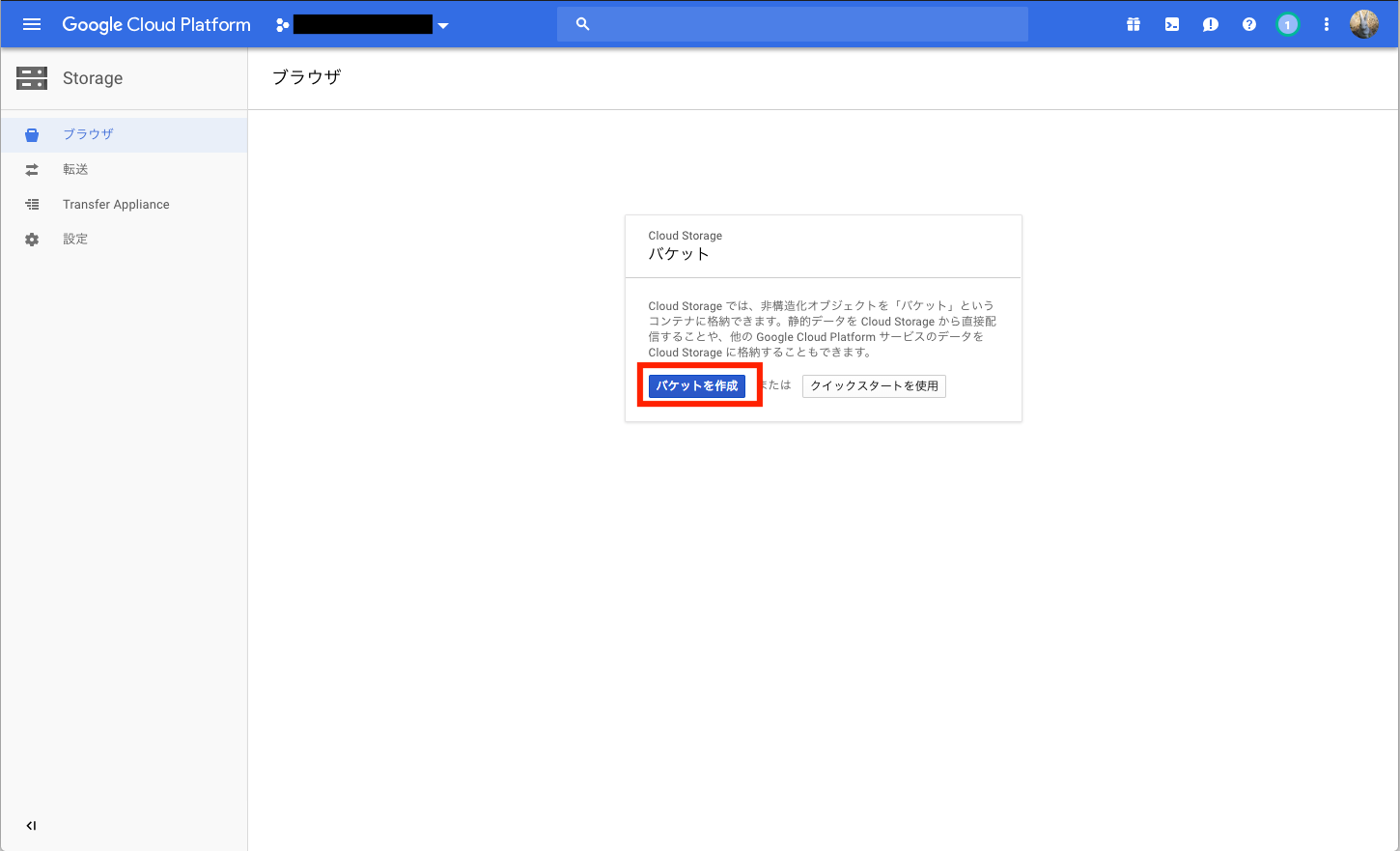
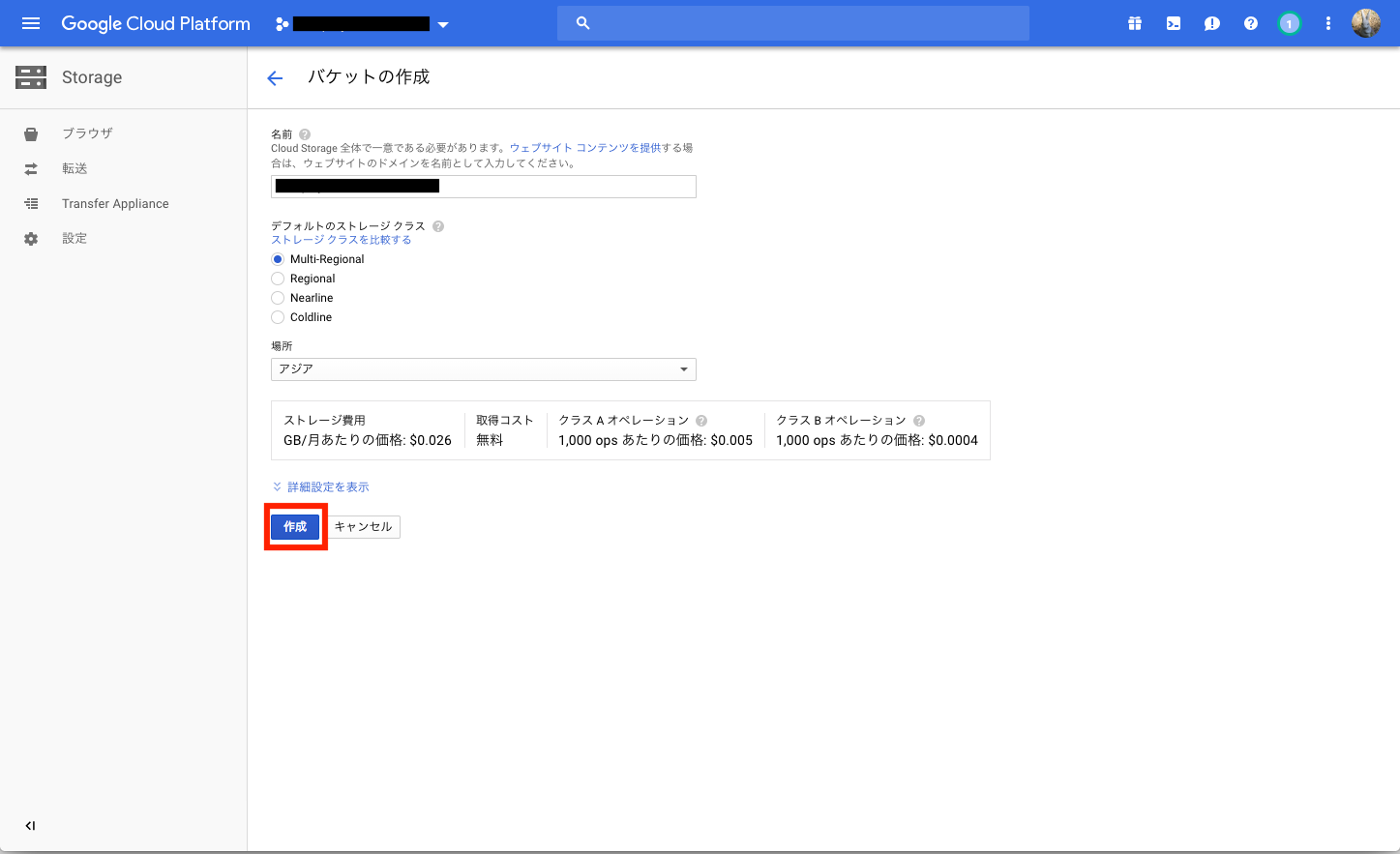
下記を設定及び選択して作成を実施する
- 名前:[your_backet]
- デフォルトのストレージクラス:Multi-Regional
- 場所:アジア
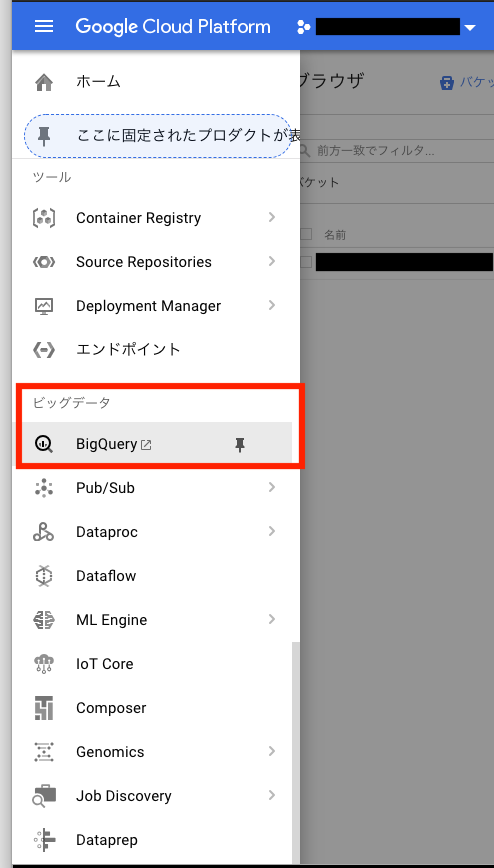
BigQueryのデータセット作成
ナビゲーションメニューのビッグデータからBigQueryを選択する
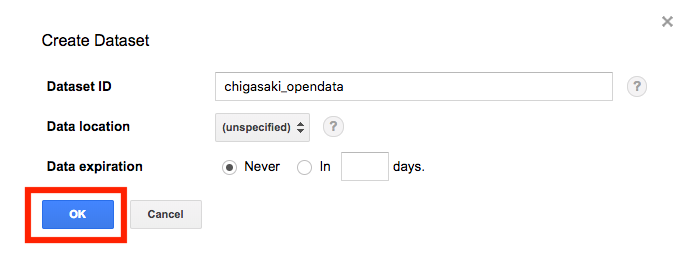
プロジェクト名の横の三角からCreate new datasetを選択し、下記設定値でOKを選択する
- Dataset ID:chigasaki_opendata
- Data location:unspecifled
- Data expiration:Never
実行
ナビゲーションメニューのビッグデータからDataflowを選択する
Cloud Dataflow APIの有効化
ナビゲーションメニューのAPIとサービスからダッシュボードを選択する
APIとサービスを検索からCloud Dataflow APIを検索する
Cloud Dataflow APIを有効にする
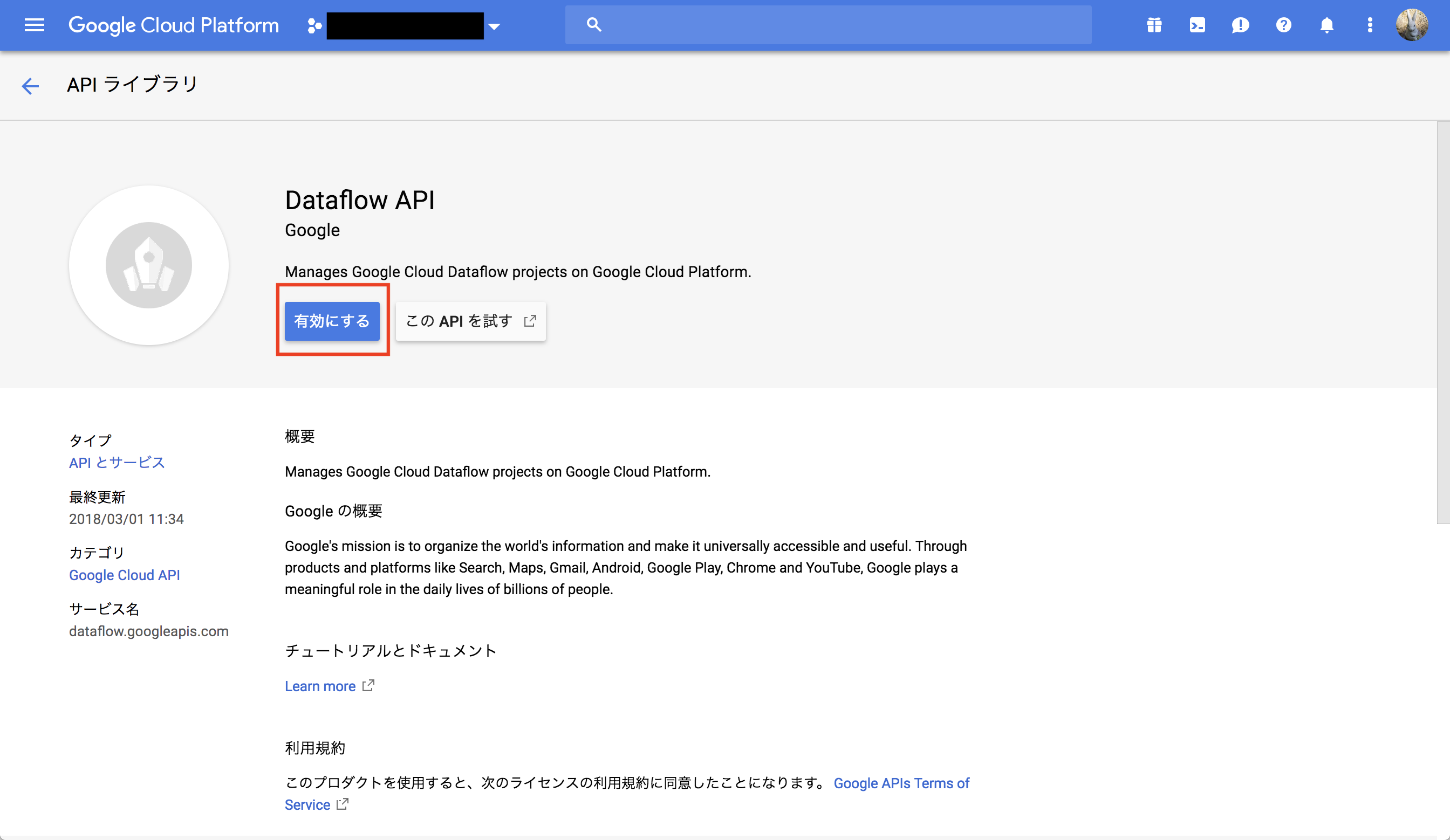
有効になったら、Google Cloud Shellを起動し、コマンドを実行していく

必要資材のコピー
下記コマンドを実行し、ハンズオン用のスキーマとCSV、udfをコピーする
gsutil cp gs://gcpug-shonan-vol27/schema.json gs://[your_backet]/gcs-to-bigquery/bigquery-schema/
gsutil cp gs://gcpug-shonan-vol27/jinkounosuii_3004.csv gs://[your_backet]/gcs-to-bigquery/input/
gsutil cp gs://gcpug-shonan-vol27/udf.js gs://[your_backet]/gcs-to-bigquery/udf/
Dataflowの実行
下記コマンドを実行し、テンプレートエンジンの作成及び実行を実施する
gcloud beta dataflow jobs run text-to-bigquery \
--gcs-location gs://dataflow-templates/latest/GCS_Text_to_BigQuery \
--parameters javascriptTextTransformFunctionName=transform,JSONPath=gs://[your_backet]/gcs-to-bigquery/bigquery-schema/schema.json,javascriptTextTransformGcsPath=gs://[your_backet]/gcs-to-bigquery/udf/udf.js,inputFilePattern=gs://[your_backet]/gcs-to-bigquery/input/jinkounosuii_3004.csv,outputTable='[your_project_id]:chigasaki_opendata.jinkounosuii',bigQueryLoadingTemporaryDirectory=gs://[your_backet]/gcs-to-bigquery/temp \
--staging-location gs://[your_backet]/gcs-to-bigquery/staging
確認
うごいた。。
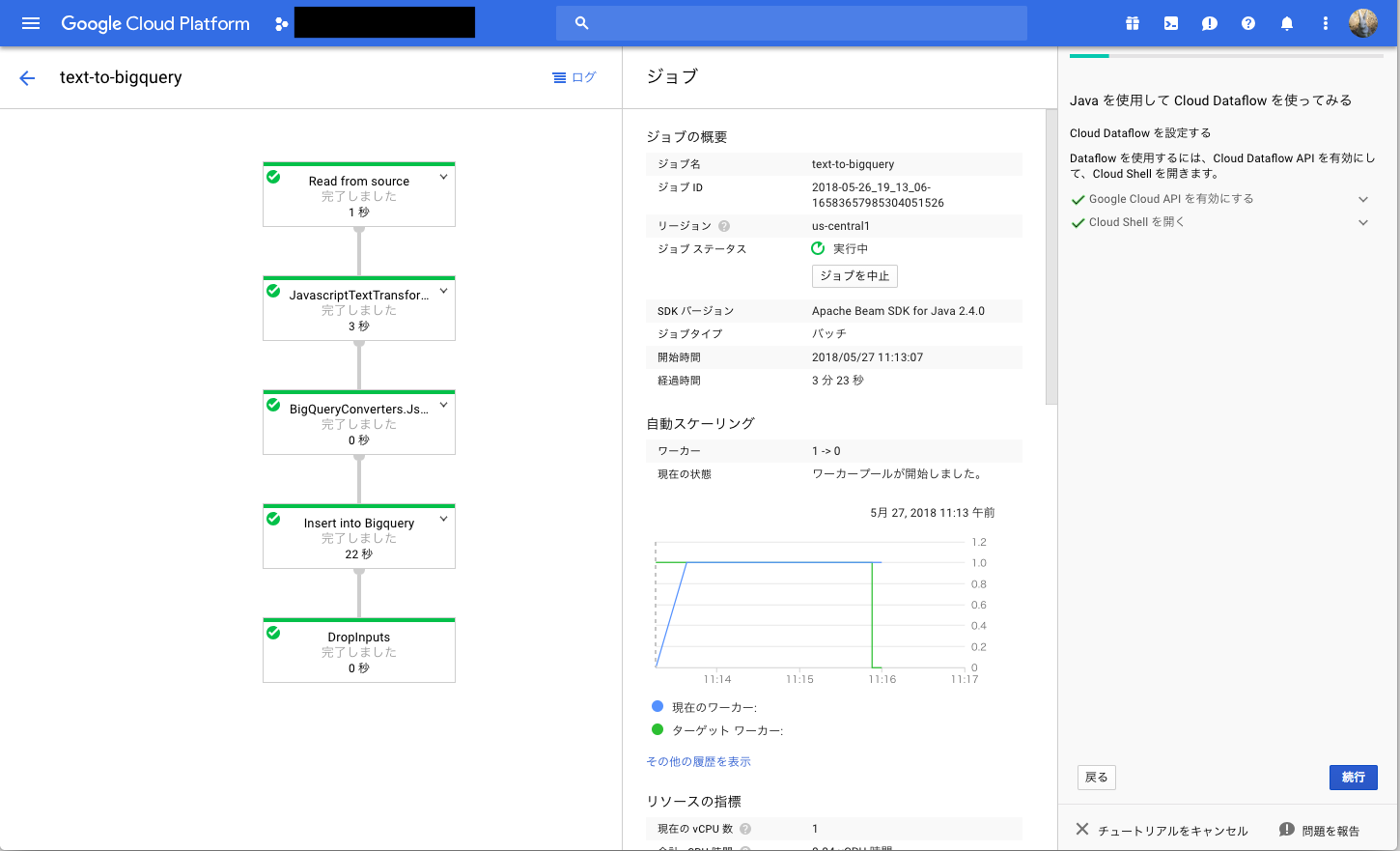
データも見れる様子。。
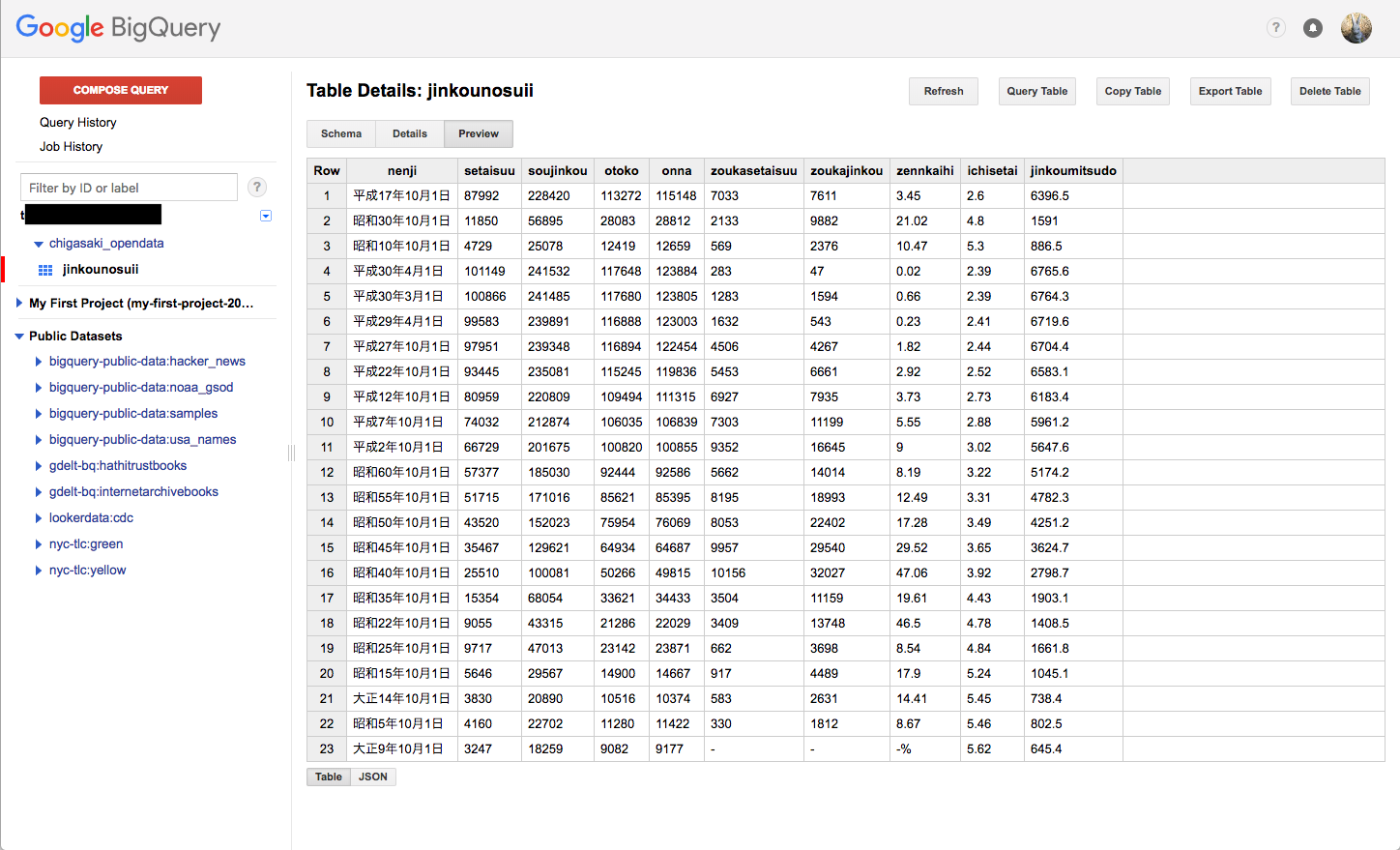
結果
エラーが解消出来てスッキリしました。
また、他の記事書いてる方はプロジェクトIDとパケット名マスクしてたので真似してみましたが、意味があるのかはちょっと謎です。