先日投稿したこちらの記事を利用して、ドロップアウトについて考えます。
といっても、一言で終わってしまうのですが。
ドロップアウトとは
Deep Learningでガリガリ学習させていくと、時に過学習が発生します。
これは学習データばかり処理しすぎて、それ専用の識別機になってしまい、別のデータに対応できなくことを意味します。
識別は、基本的に分類問題なのですが、この分類がうまくいかなくなります。
グラフで見るとわかりやすいのですが、いくつかの点があり、最初はあまり点に沿っていないのですが、やがて点に近い曲線が出来上がります。
しかし学習させすぎると、各点には近いのですが、どうみてもおかしな曲線が出来上がってしまいます。
これで分類しても、うまくいかないことはよくわかるかと思います。
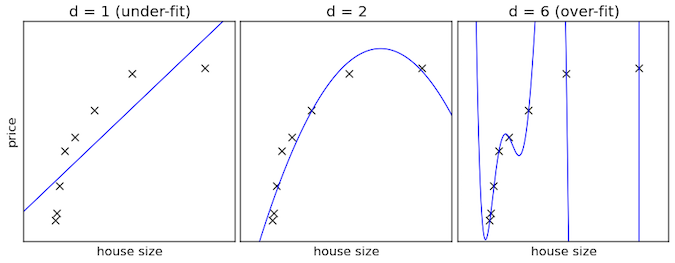
ということで、ある程度学習したら、あまり関係がないところは無視するような処理を行います。これが「ドロップアウト」です。
Deep Learningの場合、各のノードが階層でつながっているのですが、このうちの必要がなさそうなノードを消してしまいます。
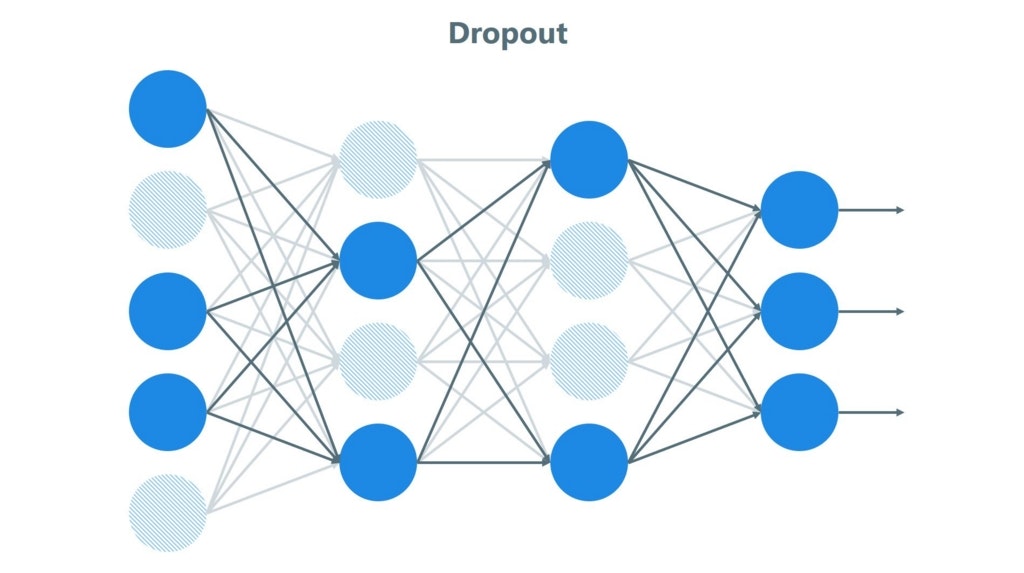
※つながりを切るのではなく、ノードを消しちゃいます
TensorFlowでの記述
TensorFlowでは、この「消しちゃうノード」の残す割合を設定します。
使用する関数は「tensorflow.nn.dropout()」です。
割合は第2引数で指定します。
keep_prob = tensorflow.placeholder(tf.float32)
h_fc1_drop = tensorflow.nn.dropout(h_fc1, keep_prob)
チュートリアルでは、学習実行時に残す割合を「0.5」として指定しています。
(半分のノードを残して、半分のノードを消す)
train_step.run(feed_dict={x: batch[0], y_: batch[1], keep_prob: 0.5})
なお、テスト時にはドロップアウトは行わないようにします。
(「1.0」を設定)
accuracy.eval(feed_dict={x: mnist.test.images, y_: mnist.test.labels, keep_prob: 1.0})
値の調整
値として何がいいのかは試行錯誤するしかないのですが、値だけでなく、ドロップアウトを行う場所や回数も調整の対象となるようです。
※きっと、この値や位置、回数も、Deep Learningで調整されるときが来るんだろうなぁ(遠い目)