ネットサーフィンをしていると、言葉のマサカリやアハトアハトから飛び出す罵倒が飛び交っております。そういう流れ弾がこちらに飛んできた場合、私達は精神衛生上の健康のためにどのように過ごすべきでしょうか?
ひとつの解決策として、このような精神衛生上に悪い文章を「ゆっくり」っぽく変換することで、受け流す方法があります。
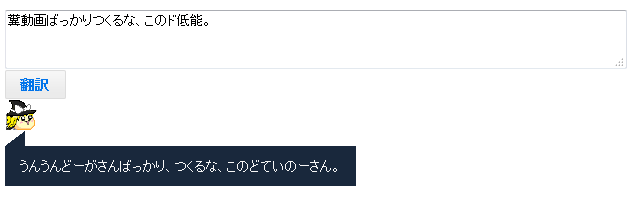
ゆっくり翻訳
http://needtec.sakura.ne.jp/yukkuri_translator/
仮に「糞動画ばっかりつくるな、このド低能」といわれたとしましょう。
しかし、「うんうんどうがさんばっかり、つくるな、このどていのーさん。」に変換されたら、怒りはわかないでしょう。
ここではMeCabを利用して形態素解析をおこない、精神衛生上に悪い文章を、ゆっくりっぽく変換することにより、不快感をなくし、むしろ、ほっこりするようにしてみます。
ソースコード
#!/usr/bin/env python
# -*- coding: utf-8 -*-
import MeCab
import jctconv
import sys
import codecs
reload(sys)
sys.setdefaultencoding('utf-8')
sys.stdout = codecs.getwriter('utf-8') (sys.stdout)
converter = {
'食べる' : 'むーしゃむーしゃする',
'食べ' : 'むーしゃむーしゃし',
'寝る' : 'すーやすーやする',
'眠る' : 'すーやすーやする',
'寝' : 'すーやすーやし',
'眠' : 'すーやすーやし',
'糞' : 'うんうん',
'大便' : 'うんうん',
'便' : 'うんうん',
'尿' : 'しーしー',
'小便' : 'しーしー',
'太陽' : 'おひさま',
'制裁' : 'せいっさい',
'菓子' : 'あまあま',
'飴' : 'あまあま',
'砂糖' : 'あまあま',
'ジュース' : 'あまあま',
'コーディネート' : 'こーでぃねーと',
'妊娠' : 'にんっしんっ'
}
class MarisaTranslator:
def __init__(self, user_dic):
self.mecab = MeCab.Tagger("-u " + user_dic)
def _check_san(self, n):
"""
「さん」をつけるかどうかの判定
"""
f = n.feature.split(',')
if f[0] == '名詞':
if f[1] == '固有名詞' or f[1] == '一般':
if n.next:
# 次の単語のチェック
nf = n.next.feature.split(',')
if nf[0] in ['名詞', '助動詞']:
# 名詞が続く場合は、ここでは「さん」をつけない
return False
else:
if n.surface.endswith('さん'): # さんでおわる場合は付与しない
return False
if n.surface == '様' or n.surface == 'さま': # 様でおわる場合は付与しない
return False
return True
else:
return True
return False
def _check_separator(self, n):
"""
「、」をつけるかどうかの判定
"""
f = n.feature.split(',')
if f[0] == '助詞':
if n.next:
# 次の単語のチェック
nf = n.next.feature.split(',')
if nf[0] in ['記号', '助詞']:
return False
return True
return False
def _get_gobi(self, n):
if n.next:
f_next = n.next.feature.split(',')
if n.next.surface == '、':
return None
if f_next[0] == 'BOS/EOS' or f_next[0] == '記号':
f = n.feature.split(',')
if f[0] in ['助詞', '名詞', '記号', '感動詞']:
return None
if f[5] in ['命令e', '連用形']:
return None
if n.surface in ['だ']:
return 'なのぜ'
else:
return n.surface + 'のぜ'
return None
def translate(self, src):
n = self.mecab.parseToNode(src)
text = ''
pre_node = None
while n:
f = n.feature.split(',')
if n.surface in converter:
text += converter[n.surface]
elif len(f) > 8:
gobi = self._get_gobi(n)
if gobi is not None:
text += gobi
elif f[8] != '*':
text += f[8]
else:
text += n.surface
else:
text += n.surface
if self._check_san(n):
text += 'さん'
elif self._check_separator(n):
text += '、'
n = n.next
pre_node = n
return jctconv.kata2hira(text.decode('utf-8')).encode('utf-8')
上記クラスの利用例:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
from yukkuri_translator import MarisaTranslator
if __name__ == "__main__":
t = MarisaTranslator('yukkuri.dic')
print t.translate('糞動画ばっかりつくるな、このド低能。')
説明
ひらがなへの変換
すべての文字を平仮名にすることにより、餡子脳っぽい台詞にします。
これには、まず、MeCabで形態素解析をおこないます。
これにより、各単語の読みが取得できます。これはfeatureの8項目(0を開始として)が該当します。
この読みはカタカナになっているのでjctconvをもちいてすべて平仮名に変換します。
読みを間違うこともありますが、そのあたりは、餡子しかつまっていないので 仕様 です。
平仮名ばかりなので、適度に「、」を付与する。
ゆっくりの仕様上、平仮名が多用されることになります。
そのため、可読性をたかめるために、助詞の後になるべく「、」を付与します。
この条件の詳細は「_check_separator」を参照してください。
「名詞」の語尾に「さん」をつける
名詞の語尾に「さん」をつけることにより、ゆっくりらしさを表現します。
名詞が続いた場合は、除外するなどの条件がありますので詳細は「_check_san」を確認してください。
語尾に「のぜ」を付与する
ゆっくりまりさの語尾には特徴があり、文末が「のぜ」、「なのぜ」で終わるケースが多いのでそれを再現しました。
例としては次のようになります。
支給と支出を管理するのは当たり前だ
とあった場合、
しきゅーと、ししゅつを、かんりするのわ、あたりまえなのぜ
となります。
語尾の条件については「 _get_gobi」を参照してください。
単語をおきかえる
いくつかの単語を置き換えるようにします。
たとえば「糞」という汚らしい単語を「うんうん」と置き換え利用者の精神の安定を図ります。
この置き換えはconverter変数に登録された内容に従い行います。
まとめ
MeCabの形態素解析を用いることで、精神衛生上に悪い文章を、かわいいゆっくりがしゃべっているように偽装できることが確認できました。
これを応用することで、「ゆっくり霊夢」、「ゆっくり妖夢」、「やる夫」っぽい文章への翻訳などが行えると考えられます。
以下にWebで動作するアプリケーションと、そのコードを添付します。
ゆっくり翻訳
http://needtec.sakura.ne.jp/yukkuri_translator/
https://github.com/mima3/yukkuri_translator
以上。