PythonとJavaでsqliteを介してポアソン分布とポアソン累積分布プロット
前回
PythonとJavaでそれぞれポアソン分布とポアソン累積分布をグラフで書いてみる。
でJavaで作成したデータをMatplotlibでプロットしましたが、CSVでデータ橋渡しをしていたものを
SQliteで書き直してみました。
SqliteAPIはPythonは3.6標準のもの、Javaはこちらのものを使用しています。
下記のコードはmath_data.dbにテーブルPoissonとPoissonCDFを作成し、それぞれのλに対する確率質量と累積を入れ込んでいってます。
Javaによるコード
poisson.java
public static void main(String[] args) {
Connection connection = null;
Statement statement = null;
Calc c = new Calc();
// リストに値をλ値を格納する方式に変更
int[] lamList = {1, 4, 8, 10};
try {
double p = 0;
Class.forName("org.sqlite.JDBC");
connection = DriverManager.getConnection("jdbc:sqlite:math_data.db");
statement = connection.createStatement();
connection.setAutoCommit(false);
//テーブル作成
statement.executeUpdate("DROP TABLE IF EXISTS Poisson");
statement.executeUpdate("CREATE TABLE IF NOT EXISTS Poisson( lam integer, count integer , p real )");
//値を入していく
PreparedStatement preparedStatement = connection.prepareStatement("INSERT INTO Poisson values (?, ?, ?);");
// λ回一定期間に発生する事象がi回一定期間内に発生する確率p
for (int i = 0; i < lamList.length; i++) {
for (int j = 0; j <= 12; j++) {
p = c.poisson(lamList[i], j);
preparedStatement.setInt(1, lamList[i]);
preparedStatement.setInt(2, j);
preparedStatement.setDouble(3, p);
preparedStatement.addBatch();
}
}
System.out.println(preparedStatement.executeBatch().length + "件バッチ登録します。");
connection.commit();
// 累積分布
statement.executeUpdate("DROP TABLE IF EXISTS PoissonCDF");
statement.executeUpdate("CREATE TABLE IF NOT EXISTS PoissonCDF( lam integer, count integer , p real )");
//値を入していく
preparedStatement = connection.prepareStatement("INSERT INTO PoissonCDF values (?, ?, ?);");
// λ回一定期間に発生する事象がi回以下一定期間内に発生する累積確率p
for (int i = 0; i < lamList.length; i++) {
double pTotal = 0;
for (int j = 0; j <= 12; j++) {
p = c.poisson(lamList[i], j);
pTotal += p;
preparedStatement.setInt(1, lamList[i]);
preparedStatement.setInt(2, j);
preparedStatement.setDouble(3, pTotal);
preparedStatement.addBatch();
}
}
// バッチ書き込み
System.out.println(preparedStatement.executeBatch().length + "件バッチ登録します。");
connection.commit();
} catch (ClassNotFoundException e) {
e.printStackTrace();
} catch (SQLException e) {
e.printStackTrace();
} finally {
try {
if (statement != null) {
statement.close();
}
} catch (SQLException e) {
e.printStackTrace();
}
try {
if (connection != null) {
connection.close();
}
} catch (SQLException e) {
e.printStackTrace();
}
}
}
}
class Calc {
int factorial(int n) {
if (n == 0) {
return 1;
}
return n * factorial(n - 1);
}
// 一定期間に発生する事象が平均lamの場合においてk回のみ発生する確率質量密度
double poisson(double lam, int k) {
double total = 0;
total = Math.pow(lam, k) * Math.pow(Math.E, -lam) / factorial(k);
return total;
}
// 一定期間に発生する事象が平均lamの場合においてk回以下発生する確率質量密度(0を含め)
double poisson_cdf(double lam, int k) {
double p = 0;
double total = 0;
for (int i = 0; i <= k; i++) {
p = poisson(lam, i);
total += p;
}
return total;
}
}
// 実行結果
// 52件バッチ登録します。
// 52件バッチ登録します。
実行完了しました。ちゃんと入っているか確認します。
ResultSet resultSet;
resultSet = statement.executeQuery("select * from Poisson");
while (resultSet.next()) {
System.out.print(resultSet.getString("lam"));
System.out.print(",");
System.out.print(resultSet.getString("count"));
System.out.print(",");
System.out.println(resultSet.getString("p"));
}
resultSet = statement.executeQuery("select * from PoissonCDF");
while (resultSet.next()) {
System.out.print(resultSet.getString("lam"));
System.out.print(",");
System.out.print(resultSet.getString("count"));
System.out.print(",");
System.out.println(resultSet.getString("p"));
}
/*
実行結果
1,0,0.367879441171442
1,1,0.367879441171442
1,2,0.183939720585721
1,3,0.0613132401952404
1,4,0.0153283100488101
*/
しっかりと入っていますね。
次にPythonで読み込みMatplotlibでプロットしたいと思います。
Pythonのコード
plotting.py
import sqlite3
import matplotlib.pyplot as plt
import numpy as np
import seaborn as sns
sns.set(style="darkgrid")
conn = sqlite3.connect("math_data.db")
c = conn.cursor()
c.execute('SELECT * FROM Poisson')
# リスト化
lam_db_list = np.array(c.fetchall())
# 行頭の数値がλなので、ひとまずまとめ、λごとにプロッティング
lam_db_f = sorted(list(set(map(lambda x: x[0], lam_db_list))))
fig, axe = plt.subplots(1, 2, constrained_layout=True, figsize=(12, 5))
# 行頭のλ数の種類分だけリストを作り、それをもとにプロットする。
for i in range(len(lam_db_f)):
y_axis = []
for j in lam_db_list:
if j[0:1] == lam_db_f[i]:
y_axis.append(j[2:])
y_axis = np.array(y_axis).reshape(-1)
x_axis = range(len(y_axis))
axe[0].plot(x_axis, y_axis, marker='o', label='$\lambda=%.2f$' % lam_db_f[i])
c.execute('SELECT * FROM PoissonCDF')
lam_db_list = np.array(c.fetchall())
lam_db_f = sorted(list(set(map(lambda x: x[0], lam_db_list))))
for i in range(len(lam_db_f)):
y_axis = [j[2:] for j in lam_db_list if j[0:1] == lam_db_f[i]]
y_axis = np.array(y_axis).reshape(-1)
x_axis = range(len(y_axis))
axe[1].plot(x_axis, y_axis, marker='o', label='$\lambda=%.2f$' % lam_db_f[i])
conn.close()
axe[0].set_xlabel('k')
axe[0].set_ylabel('probability')
axe[0].set_title('Poisson')
axe[0].legend()
axe[0].grid(True)
axe[0].set_xticks(range(len(x_axis)))
axe[1].set_xlabel('k')
axe[1].set_ylabel('probability')
axe[1].set_title('PoissonCDF')
axe[1].legend()
axe[1].grid(True)
axe[1].set_xticks(range(len(x_axis)))
plt.savefig("poisson_n_cdf.png")
plt.show()
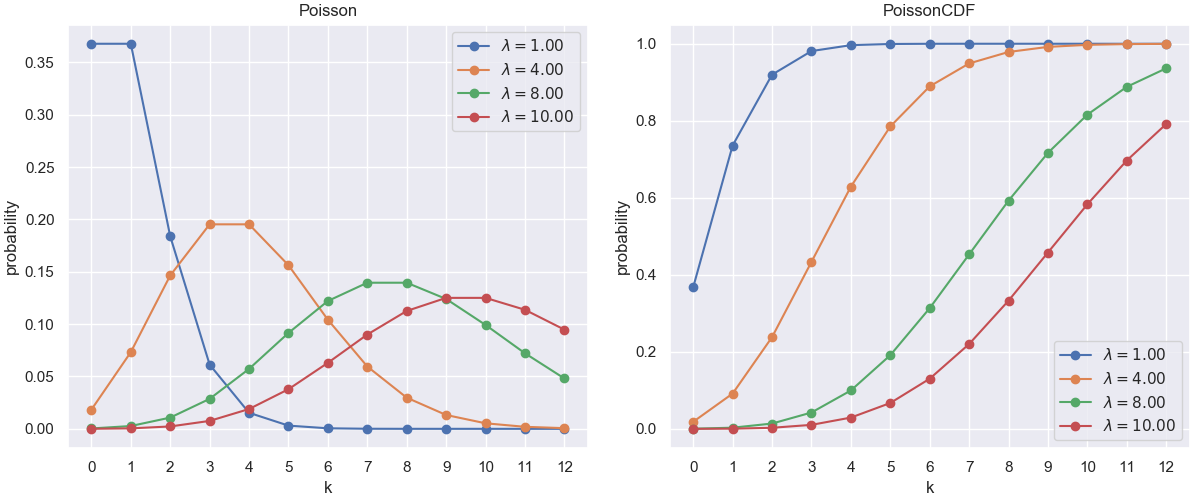
きれいにプロットできました。またJava側で渡すλ配列を変更すれば様々なポアソン分布をプロットできます。
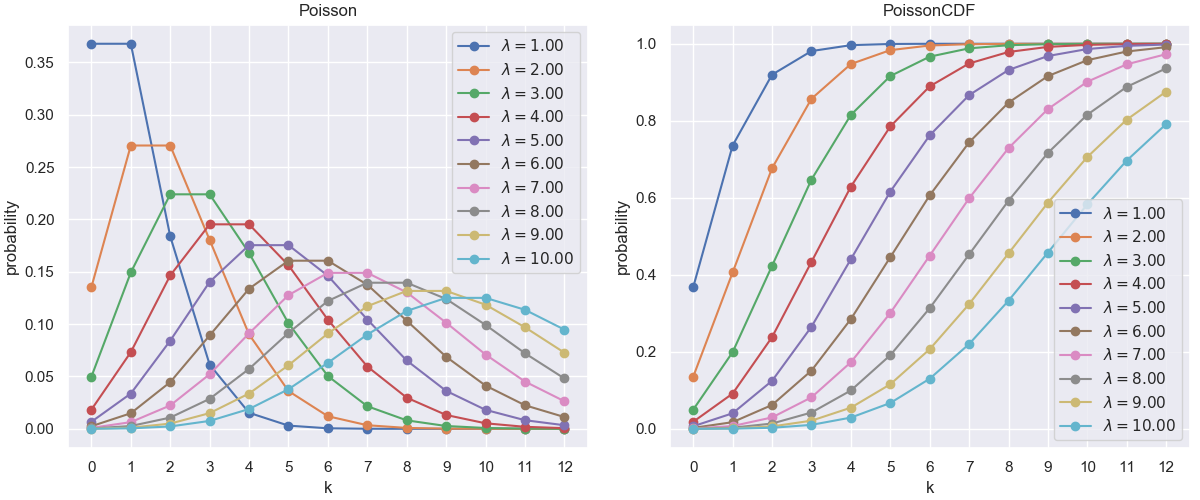
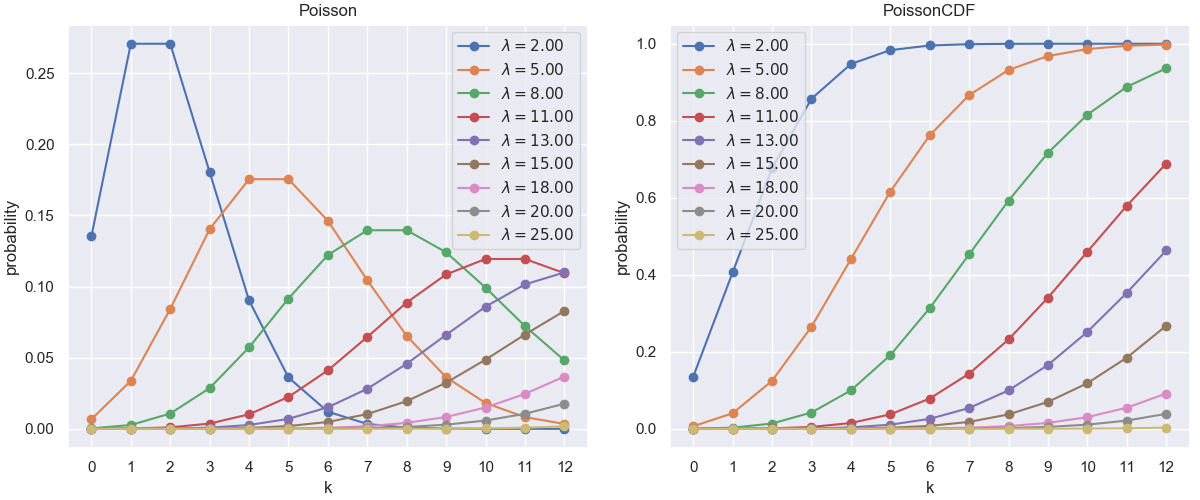
苦労した点
DB作成を行列逆に作成し、最初行頭数値から総当たりですべての配列を計算しようとしたがコードが複雑化した。
後々使いやすくするためにDBを作る段階でアウトプットまで考えないとならない。
特に不動点少数を扱うデータだと狂ってくるのであまり後々構造を弄くらなくても良いようにしたい。