うちの会社のProductのアルファ版として、Watsonを使って、物語の感情分析をしてグラフ化するっていうのをしてるんですけど、英語はそこそこ取れました。そこで日本語は解析できないので、人間が英語に翻訳したものと、機械が英語翻訳したものでどれぐらい変わるのかなと調査しました。
使ったのは、宮沢賢治の注文の多いレストランです。
やり方は、代名詞が抽出できないので、まず名前を置き換えます。その後、ToneAnalyzerに掛けます。
(我々の場合はシステムでやりましたが、Toneだけ抽出するならPlayGrandだけでOKです)
その際、機械が抽出しやすいサイズに切ってから読み込ませます。
その時の結果の抜粋です。全部で56ページありますが、長いので5枚掲載します。
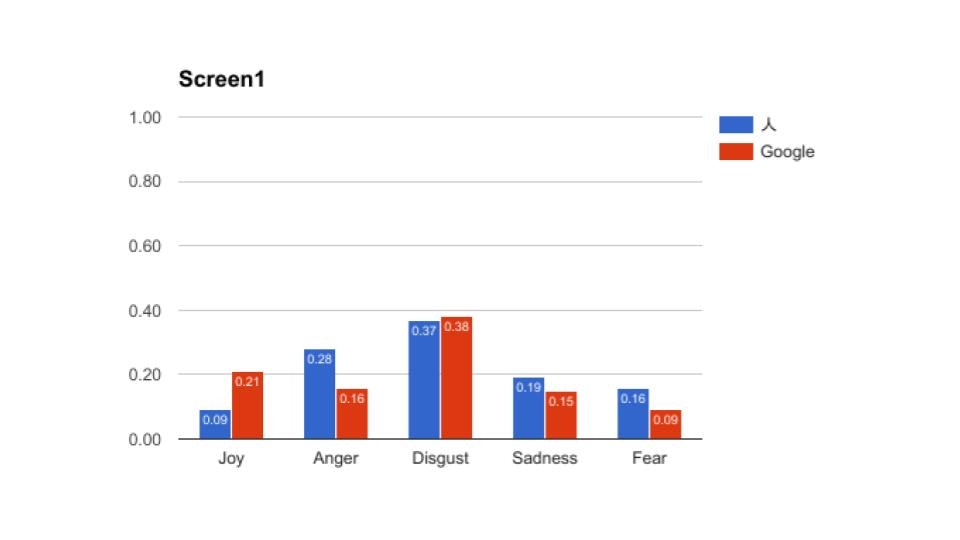
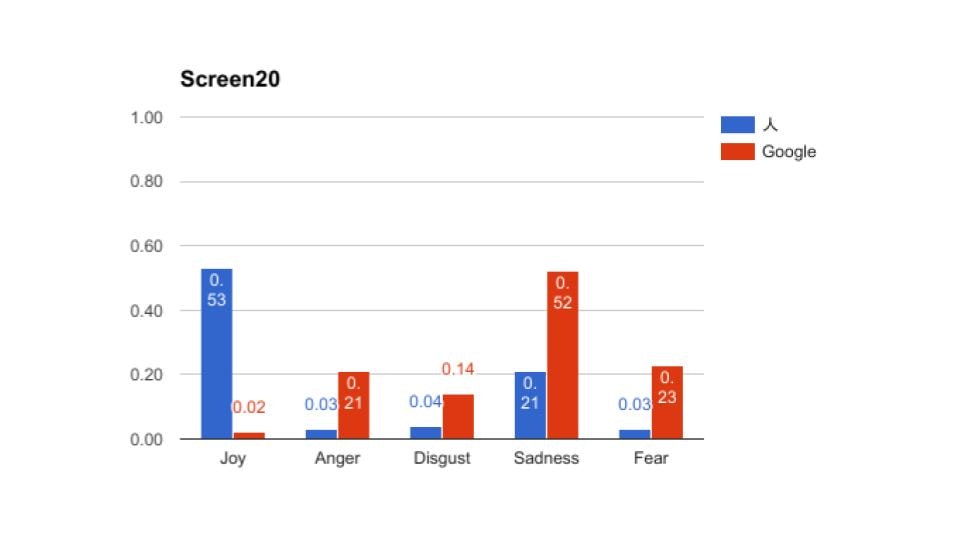
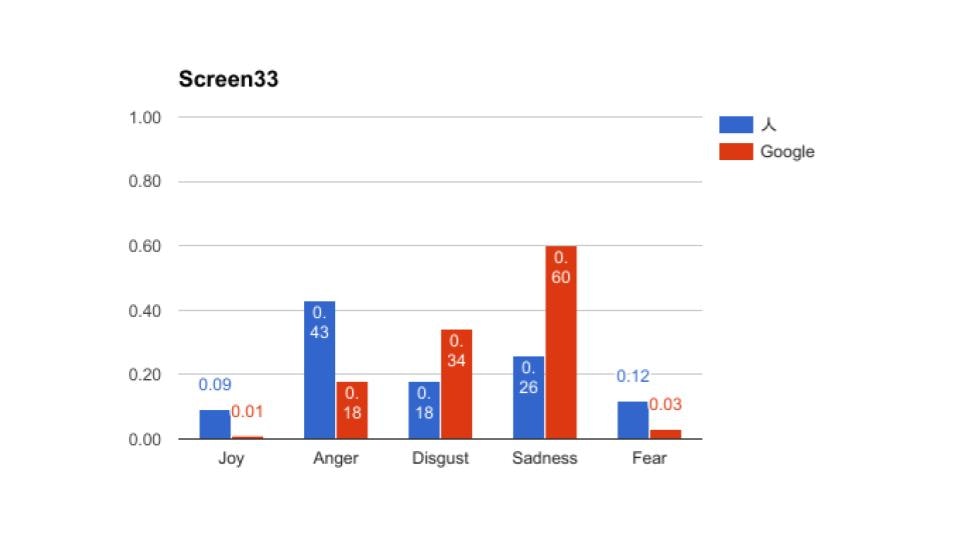
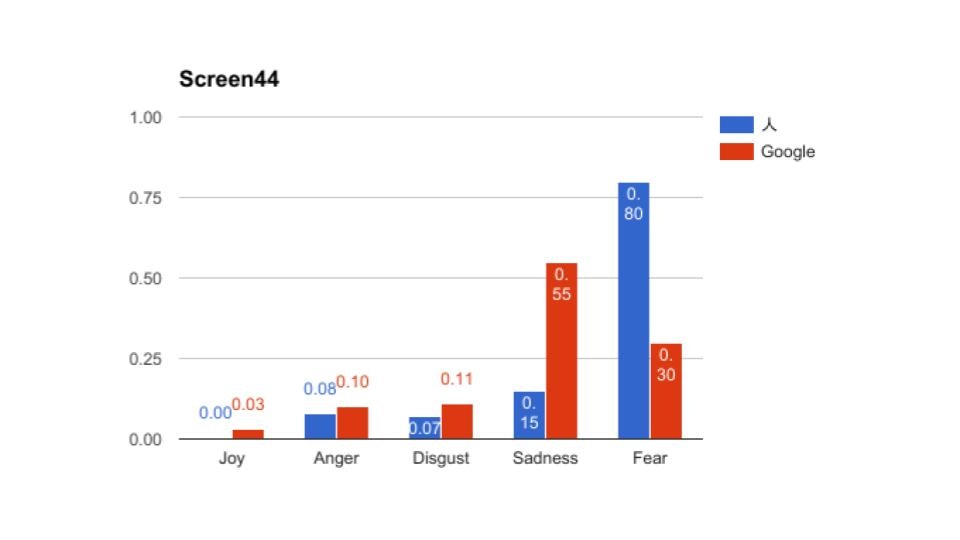
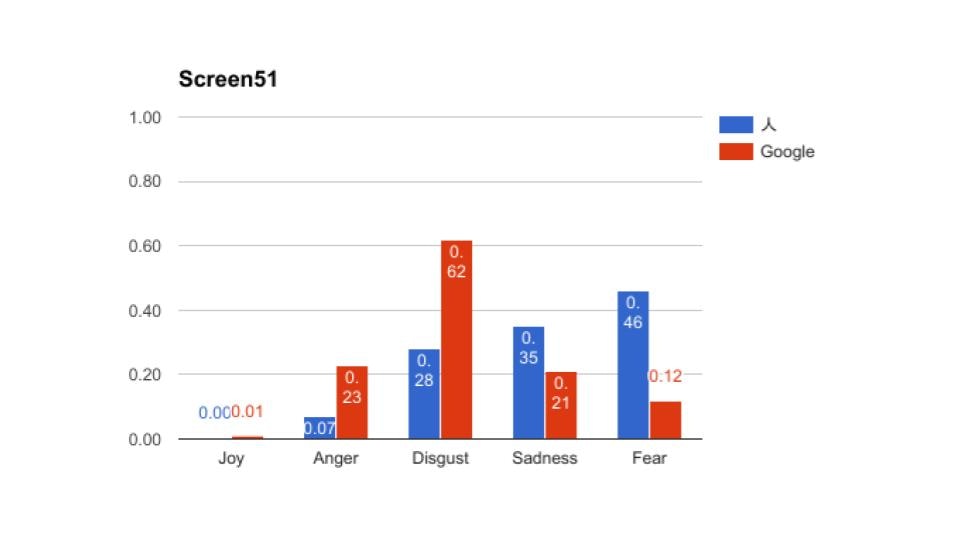
これをみてもらうと、大体あっているところと、大幅にずれているところに分かれているのがわかると思う。これから言えるのは、物語であるから日本語からの翻訳時に感情で読み替えてしまっているため、人間としてはこのシーンの恐怖はより強く表現している、機械はニューラルネットワーク的(つまりは平均的)には、嫌悪を強く表現していたという風に解釈できたのかもしれないということです。
これは最近のGoogle翻訳だから出来たことだと思います。当然意味不明の翻訳になっている部分はあるものの、ToneAnalyzerは特定の単語に依存して抽出しているわけではないので、そのシーン(わたし達はスクリーンと呼んでいる)の平均値として返しています。
ちなみに、この抽出パラメーターをキャラクターごとにマッピングして、更に判定し直して、統計値を使ってグラフ化しているのが我々のサービスです。
現在は12分割したものしか出していませんが、既に細かくデータを切っているので、表現だけ変えれば、より細かくグラフ化することは自動で可能です。
皆さんのご要望があるのか無いのか、わからなかったので、出してきませんでしたが、我々の研究の成果はこんな感じです。今後はGoogle翻訳APIを使っても粒度的には問題ないと判断して、日本語も含めてやっていこうと思います。
皆さんからのご意見お待ちしています。