概要
最近SVMに興味を持ったので、以下のように何回かに分けてまとめていこうと思います。
-SVM概要(本記事)
-SVM詳しい原理(次回以降)
-SVM発展(いつか)
では、さっそくSVNとは何なのか見ていきましょう。
SVMとは
SVMは、あるデータXが与えられた時にXがAに分類されるか、Bに分類されるかを判別するものです。ディープラーニングが登場するまではSVMがとてもよく使われていたみたいです。
以下、全て線形SVMの説明を書いていきます。
非線形SVMというのもあるんですが、自分があまりよく理解できてないので。。。
非線形写像すれば、非線形も線形分離できるとかなんとか。誰か教えて下さい。
SVMの原理(概要)
状況設定を以下のようにしましょう。
ラベルAとラベルBのデータがそれぞれいくつかあります。このとき、データXはAとBどちらに分類されるでしょうか?
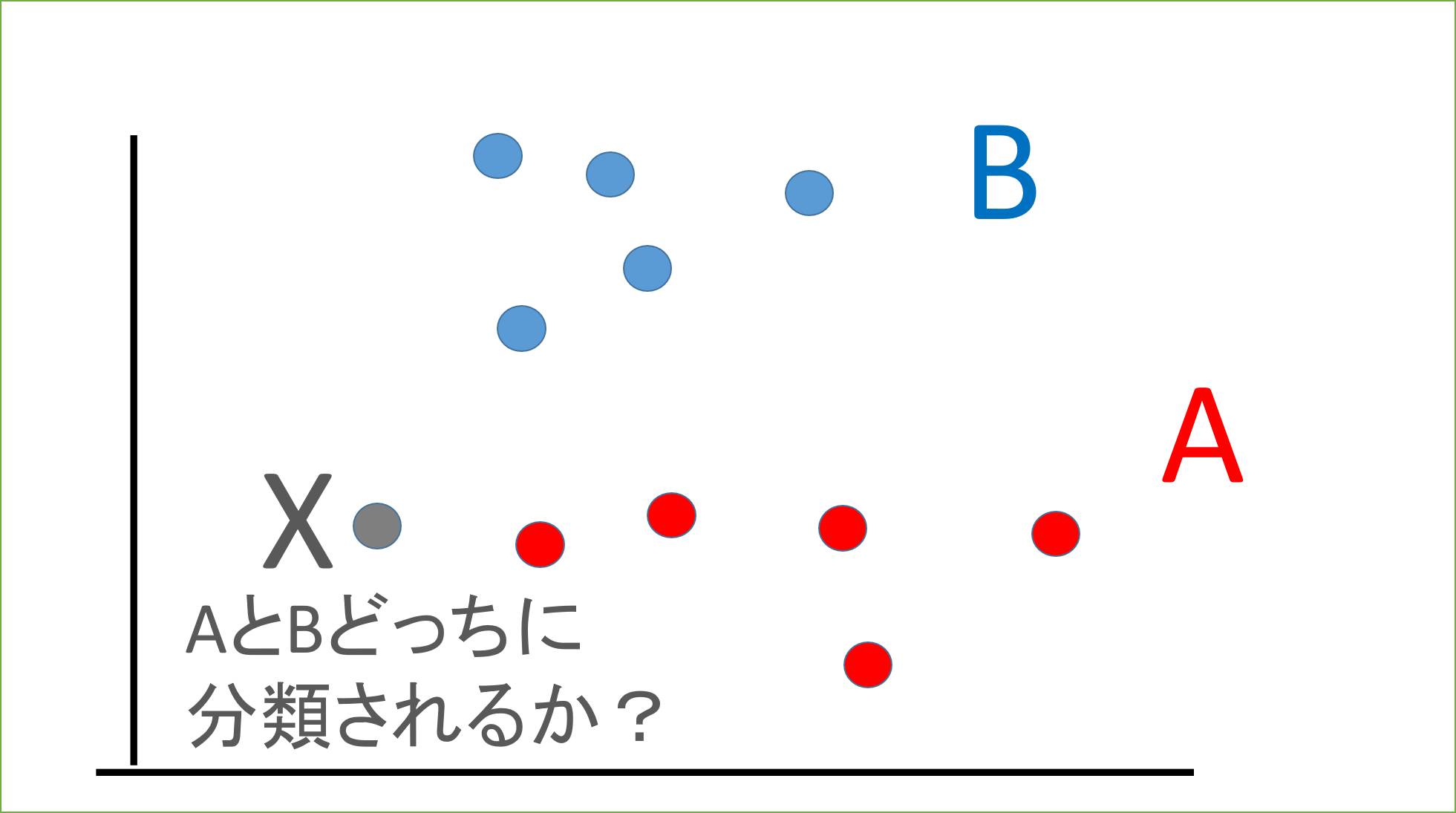
上記の例では、なんとなくAに分類されそうですね。
XがAとBどちらに分類されるかを決めるには、当然ですがAとBの分類ルールを決めればいいですよね!
SVMでは、分類ルールを以下のように設定しています。
"マージンを最大化するような直線を分類の境界線とする"
(* ̄- ̄)ふ~んって感じですよね。
単純に直線で分類するんだってことは分かると思います。
じゃあ、マージンって何??
マージンとは、「境界線」と「境界線に最も近い点」の距離のことです。
*「境界線」と「境界線に最も近い点」の距離を最大化すれば、「全ての点」と「境界線に最も近い点」の距離も最大化されるみたいですね。なぜかは知りません。教えて下さい。
マージンを図にすると、以下のような感じ
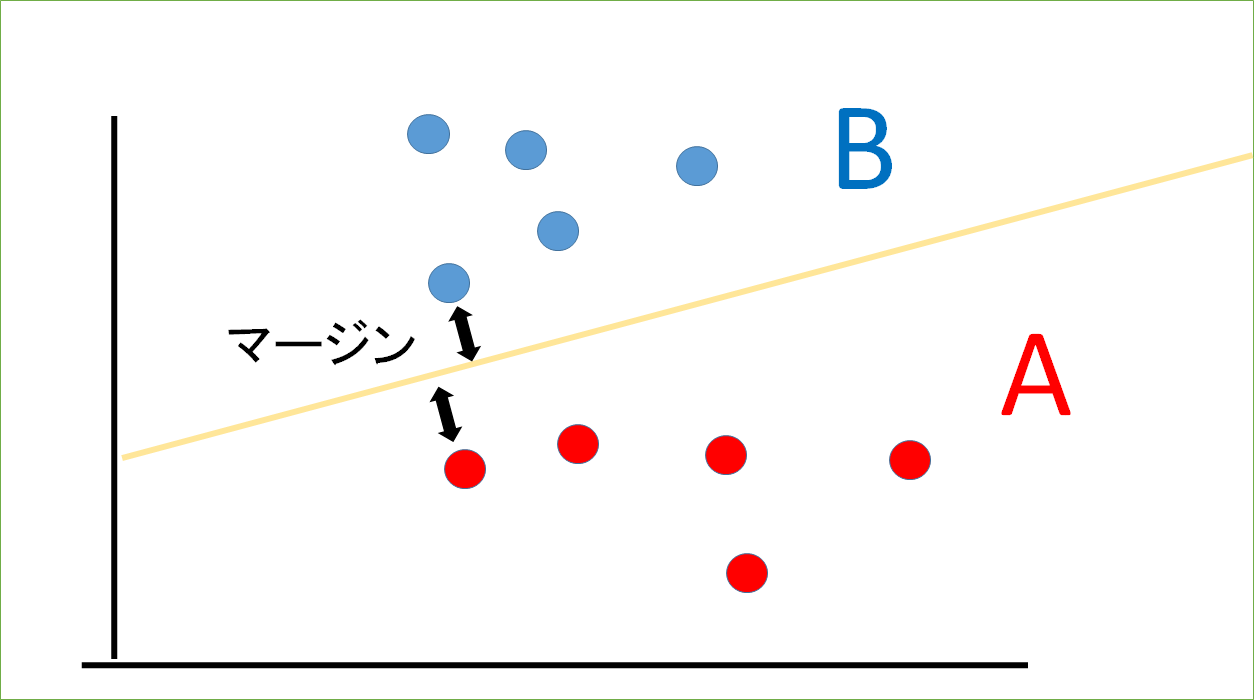
とか
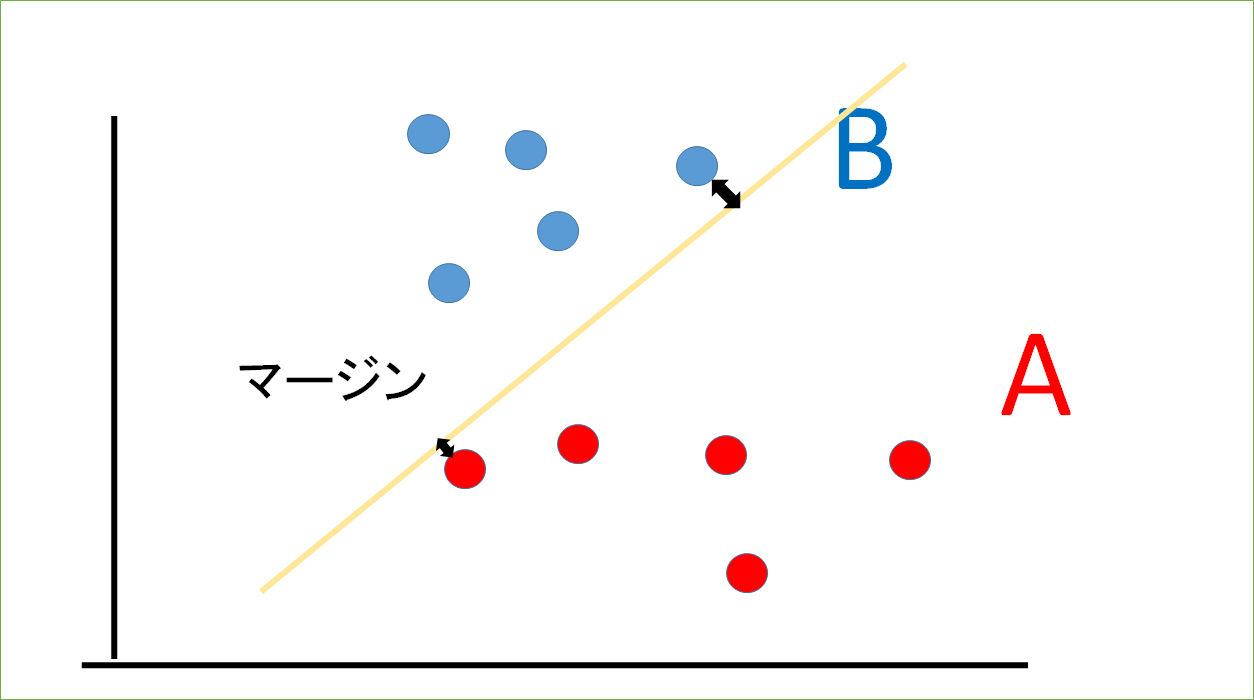
とか。
この二つを見比べると、上の図の方がマージンが大きくとれていますよね。
このマージンが最大化となる直線を、境界線と定めるのがSVMです。
まとめ
- SVMは、マージンを最大化するように直線で分類するもの。
- マージンは、「境界線」と「境界線から最も近い点」との距離のこと。
次回以降は数式使いながら、もう少し詳しい部分まで触れていく予定です。
では、お疲れさまでした。
