この記事はVASILY DEVELOPERS BLOGにも同じ内容で投稿しています。よろしければ他の記事もご覧ください。
わーい!コンテナたのしー!🐾
弊社が運営するファッションサイトIQONでは、日々200以上の提携ECサイトから100万のオーダーで商品をクロールしています。
新商品の追加・商品の在庫状況・セールの開催など情報は日々変化するため、弊社において「正しくクロールすること」と「速くクロールすること」は肝心カナメの要素です。
本記事では、特に「速くクロールする」という目的で構築したコンテナベースの新クローラーシステムを紹介いたします。
このクローラーシステムは、最終的にクロール時間67%減、 維持コスト70%減という成果が得られました。
キーワード:
コンテナ, Docker, Apache Mesos, Marathon, AWS Lambda, Amazon EC2 SpotFleet
問題解決手段の検討 -> コンテナ採用
コンテナを採用するまでの経緯を簡単にまとめます。
なお、途中経過を飛ばして最終的な構成から見たい方はこちらからご覧ください。
刷新のモチベーション2016
昨年末の時点で、IQONクローラーは2つの大きな問題を抱えていました。
- 季節ごとの新商品追加時期など、クロール対象の急激な変化に追従するのが難しい
- クロール中とそれ以外で負荷の差が激しく、計算資源の無駄が多い
2の影響は弊社で完結しますが、1はユーザ体験の損失につながります1。
これを根本的に解決することをモチベーションとして次の3つを満たすべく刷新に着手します。
- クロール量の急激な変化に対応してワーカー数を簡単に変更できる
- 維持コストを抑える(金銭的な削減)
- 保守コストを抑える(人の手間削減)
改修箇所の選定
幸いにも、どの部分を改修すれば良いかは着手時点で明確でした。クローラーの実行環境です。
昨年時点でのアプリケーションとその実行環境は次の通りです。
アプリケーション2016
昨年末時点のIQONのクローラーはver 4.5です。
ver 1.0: PHPで書かれたクローラー
2.0: Rubyで書き換え
3.0: resqueベースの分散処理に移行
4.0: sidekiqベースの分散処理に移行 + クローラー作成ツールの導入
4.5: shoryukenベースの分散処理に移行
ver 4.5は4.0のマイナーアップデート版で、大まかな構成はこちらの資料にあるものと変わっていません。
- クロール処理をステップごとに分解
- ステップ毎にそれを担当するプログラム(ワーカー)を準備
- ワーカーが並列分散処理を行う
という構造です。各ワーカーはそのプロセス毎に完結しており、自分以外のプロセスを意識する必要はありません。
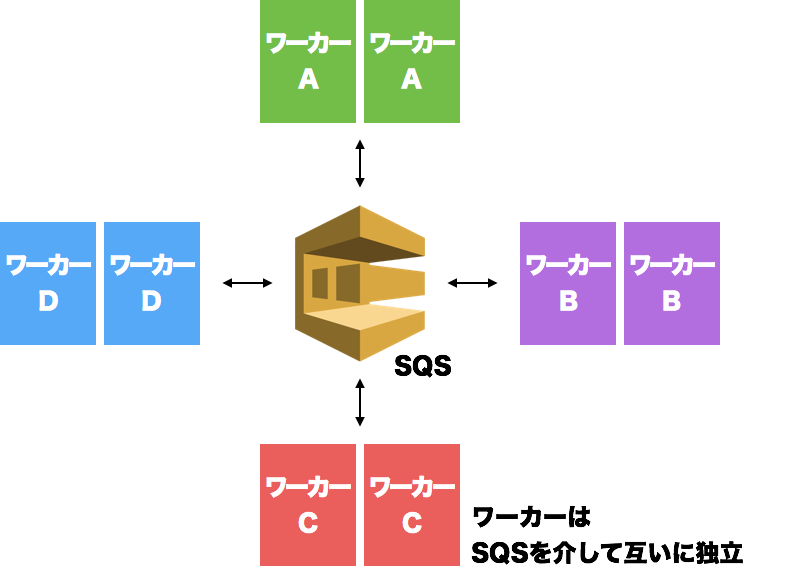
実行環境2016
昨年末時点のIQONクローラー実行環境はとてもシンプルです。
- クローラー専用のインスタンスを用意
- 前述のワーカーをsupervisorでデーモン化
- インスタンスのメトリクスを元に、インスタンス毎にワーカーのプロセス数を決定
- メッセージ・キューのdequeue速度を元にインスタンスを必要なだけ並べる
という構成です。AutoScalingはありません。
コンテナの採用
先の通り、昨年末時点のIQONクローラーはそのアプリケーションに比べて実行環境に柔軟性がありませんでした。
せっかくの分散処理ワーカーもインスタンスに縛られてはその力を発揮しきれません。宝の持ち腐れです。
これを解決するためにIQONクローラーver5.0では実行環境の改善ということを目的にDockerコンテナの導入を行いました。
今までの仕組みの延長線上で、AutoScalingやデプロイの仕組みを整備するという選択肢もありましたが、
かねてより「複数種類のワーカーが多数動く」という状況が「PaaSの上で色々なアプリケーションが動く」という状況に近いと感じていたこともあり、
PaaSを効率化するために生まれたDockerとは相性がいいに違いないという判断でコンテナ化を採用します。
コンテナ採用 -> オーケストレーションツール決定
コンテナの採用を決定後、まず着手したのがオーケストレーションツールの検証です。
オーケストレーションツール
Dockerコンテナを本番運用する上で、非常に重要なのがコンテナオーケストレーションツールです(以後、単にオーケストレーションツール)。
Dockerのライフサイクルは1コンテナ単位ですが、本番環境では複数のコンテナを複数のホストにまたがって運用します。
また、弊社ではコンテナイメージの再利用性を高めるために1コンテナ1プロセスをポリシーにしており、コンテナは複数を論理的に接続して扱うことが前提として求められます2。
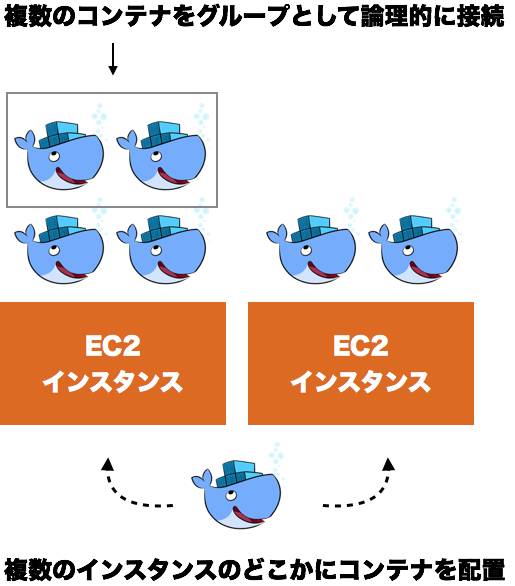
このようなコンテナ同士を論理的に接続したり、インスタンス群にコンテナを配置したりといったコンテナの組織化(オーケストレーション)を支援してくれるのがオーケストレーションツールです。
オーケストレーションツールの比較検討
今回の刷新では3つのオーケストレーションツール3を比較しました。
思い描く実行環境に必要な項目を洗い出し、比較した表が次のものです。
| 評価項目 | Kuberenes | Marathon | Amazon ECS |
|---|---|---|---|
| ELB/ALBとの連携 | ◯ | x | ◯ |
| cron jobのような時間指定でのタスク定義 | ◯ | x | x |
| コンテナのグルーピング | ◯ | △ (v1.4〜、webui未対応) | ◯ |
| マスタのHA構成 | ◯ | ◯ | ◯ (マネージド) |
| Web API | ◯ | ◯ | ◯ |
| Web UI | ◯ | ◯ | ◯ |
| ドキュメントが充実している | △ | ◯ | ◯ |
| クラスタの構築が容易 | x | ◯ | ◯ |
| ホストインスタンスのスケーリングにクラスタが追従する | ? | ◯ | ◯ |
| コンテナデプロイのタイミングでソースコードを配布可能 | x | ◯ | x |
x: 不可能 / 難しい
△: 可能だが制約あり
◯: 可能
このように評価をした結果、作りたい実行環境にとって致命的なxが無く、ツールとしてのアプローチ(後述)がクローラーに最も適しているMarathonを採用するに至りました。
補足: ホストインスタンスのスケーリングにクラスタが追従する
EC2インスタンスがAutoScalingで増減した際に、それらがクラスタの一部として自動的に認められるかどうかを検討した項目です。
- Kubernetesは検証を途中で中断してしまったので
? - Marathonはエージェントがマスタノードと通信可能であればクラスタに参加するため
◯ - ECSはサービスとしてAutoScalingの機能を提供しているので
◯
としています。
Marathon
今回の刷新で採用したMarathonはそれ単体で動くものではありません。Marathonを使うために、まずApache Mesosを理解する必要があります。
Apache Mesos
Apache Mesosは、クラスタを構成するインスタンスのCPUやメモリ、GPUやストレージを1つのリソースプールとして扱う分散システムカーネルです。

Mesosはタスクを受け取ると、リソースに空きがあるインスタンスを見つけてそこで実行します4。
利用者からみると、クラスタをあたかも1台の巨大なインスタンスがあるように扱うことが可能です。
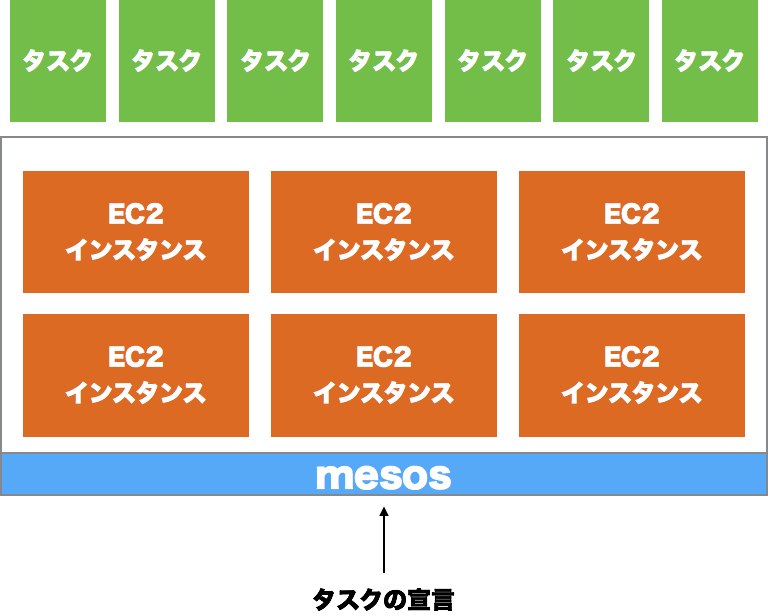
Marathonの検証をした時点ではあまり意識していませんでしたが、Mesosの「複数のインスタンスを1つの巨大なインスタンスとして扱う」というアプローチはクローラーと大変相性が良く、積極的にMarathonを採用する後押しにもなっています。
Marathonの役割
Apache Mesosで実行するタスクのライフサイクルは実行から終了コードを受け取るまでです。終了した状態が何であれ、Mesosはそれ以上何もしません。
この動作はWebサービスのようにずっと動き続けて欲しいタスクにとっては不便です。そこでMarathonが登場します。
MarathonはApache Mesos Frameworkと呼ばれるもの1つで、Mesosの仕組みの上でタスクに恒常性を与えます。

アプリケーションのコンテナを4つ、というタスクを投げるとその通りにコンテナを用意し、
仮にコンテナが例外で落ちると要求数を満たすように自動で次のコンテナを用意します。

次のJSONは、実際にコンテナを4つ起動するAPIリクエストの内容です。
メモリ256M、CPUを20%5割り当てるコンテナを4つ起動します。
{
"parse": {
"id": "/iqon/crawler/parse",
"container": {
"type": "DOCKER",
"docker": {
"image": xxxx
}
},
"cpus": 0.2,
"mem": 256,
"instances": "4"
}
}
fetch機能
Marathonの機能は多岐にわたりますが、ここでは最終的な構成に大きな影響を与えたfetch機能について紹介いたします。
これのお陰で、比較表で唯一Marathonだけがコンテナデプロイのタイミングでソースコードを配布可能で◯になっています。
fetchはタスクの起動前に、指定したファイルを取得するというMarathonの機能6です。
コンテナをデプロイする際に悩ましいのが、最新のソースコードをどう取得するか、という問題です。
もちろん、コンテナイメージをビルドする際にソースコードを含めることもできますが、
次の問題からコンテナイメージにソースコードを含めることは避けるべきと考えています。
- アプリケーションと環境の分離ができない
- コンテナレジストリに大量のタグが登録される
- デプロイ時にコンテナイメージのキャッシュが効かない
fetchはこの問題を解決します。次のJSONはfetchを利用した場合の例です。
{
"parse": {
"id": "/iqon/crawler/parse",
"container": {
"type": "DOCKER",
"docker": {
"image": xxxx
},
"volumes": [
{
"containerPath": "/var/app",
"hostPath": "./iqon_crawler",
"mode": "RW"
}
]
},
"cpus": 0.2,
"mem": 256,
"instances": "4",
"fetch": [
{
"uri": "https:// xxxx /iqon_crawler.tar.gz",
"executable": false,
"extract": true,
"cache": false
}
]
}
}
fetchとvolumeの項目は次のように処理されます。
- Mesosによる
docker runの前にfetchでIQON_crawler.tar.gzが取得/解凍される -
docker runの--volumeで、コンテナに対しマウントされる
検証時に確認した範囲では、同様の機能はMarathonにしかありませんでした。これもまたMarathonの採用を決めた大きな要素です。
オーケストレーションツール決定 -> クラスタ完成
全体構成
オーケストレーションツール選定を経て、IQONクローラーver5.0は最終的に次の形になりました。
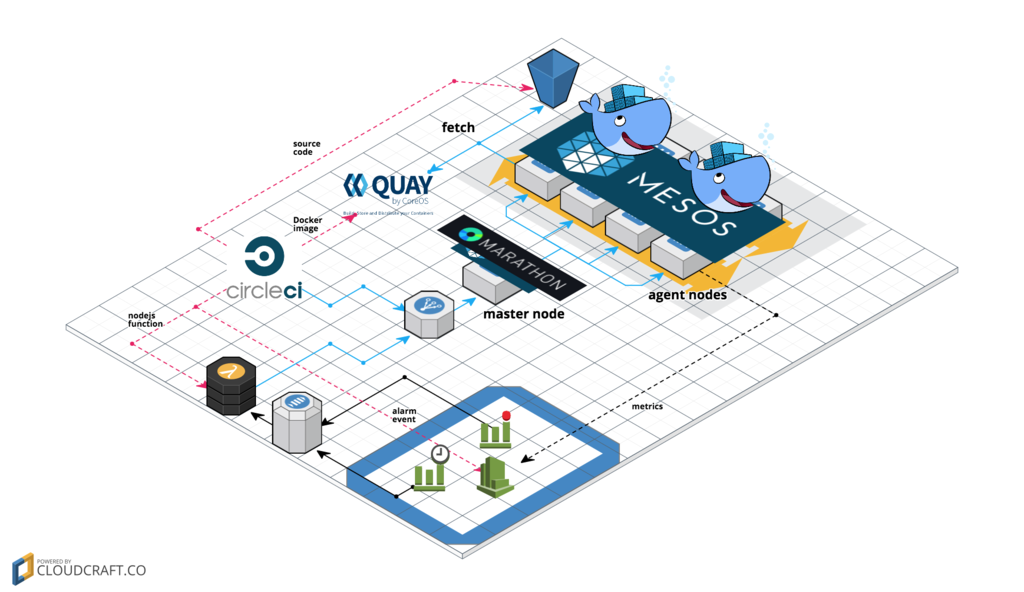
ここからは、この実行環境を4つに分けてご紹介します。
アプリケーションのデプロイ
まず、アプリケーションのデプロイ部分です。

DockerRegistryにはquay.io、CIにはCircleCIを利用しています。
- CircleCIがmasterブランチの内容をS3に保存
- Marathonへタスクの更新をリクエスト
- MarathonがMesosへリクエスト
- MesosがS3から最新のソースコードをfetch
- Mesosがquay.ioからコンテナイメージをpull
- Mesosがクラスタのどこかで
docker run
という流れでデプロイが行われます。
クローラーのリポジトリにはYAMLで書かれたデプロイルールとデプロイ用のスクリプトが用意されており、
CircleCIはそれを使ってMarathonへリクエストを送っています。以下は実際のYAMLファイルから抜粋したものです。
:common:
:env: &env
:CRAWLER_ENV: production
:RACK_ENV: production
# ...
# private docker reposからpullするための情報
:credentials: &credentials
:uri: xxxx
:executable: false
:extract: true
:cache: false
:source: &source
:uri: https:// xxxx /crawler/app/<%= ENV['CIRCLE_SHA1'] %>.tar.gz
:executable: false
:extract: true
:cache: false
:localtime: &localtime
:containerPath: /etc/localtime
:hostPath: /etc/localtime
:mode: RO
:network: &network
:ipAddress:
:networkName: mesos_slave_host_nw
# networkがUSERのときはportsを空配列で明示的に宣言しておく必要がある
:ports: []
:parse:
:id: /iqon/crawler/parse
:dependencies:
- /iqon/crawler/td-agent
:args:
- ./scripts/start_shoryuken_worker.rb
- --log-level=warn
- --worker=parse
:env:
<<: *env
:container:
:docker:
:image: <%= ENV['DOCKER_APP_IMAGE'] %>
:network: USER
:parameters:
- :key: net-alias
:value: parse
:volumes:
- <<: *localtime
- :containerPath: /var/app
:hostPath: ./iqon_crawler
:mode: RW
:type: DOCKER
:fetch:
- <<: *credentials
- <<: *source
<<: *network
デプロイの4と5で取得しているのは、YAML中にfetchとimageで指定されている要素です。
なお、デプロイについては2つの工夫を盛り込みました。
- デプロイルールの定義はYAMLで行う
- YAMLはERBでパースする
MarathonへのアクセスはJSONですが、JSONで長い定義を行うのはいささか苦痛です。
そこで、一度YAMLで記述してそれをJSONに変換する形を取ることで、可能な限りDRYに管理できるようにしています。
コメントも書けるため、補足も随時行います。
また、一度ERBでパースすることで環境変数を使えるようにしています。
これでデプロイ毎に変わる部分を気にすること無くfetchで指定することが可能になりました。
コンテナ数のコントロール
アプリケーションのデプロイができたので、次はそれをコントロールします。

適当な数のコンテナをデプロイして終わり、であれば良いのですが求めるものは状況に応じてコンテナ数(ワーカー数)が変わる実行環境です。
そこで、Lambda Functionを用いて、CloudWatchとMarathonを繋いでいます。
まず、次のようなYAMLを定義します。
:cloudwatch:
:alarm:
:iqon-crawler-production-parse-visible-high:
:rule:
# CloudWatch Alarmに登録する内容
:metric_name: 'ApproximateNumberOfMessagesVisible'
:namespace: 'AWS/SQS'
:statistic: 'Average'
# ...
:action:
# ruleを受けてLambda Functionがmarathonをどうするか
:alarm:
:method: 'PATCH'
:path: '/v2/apps/'
:body: '[{"id": "/iqon/crawler/parse","instances": 32}]'
:ok:
# ...
:insufficient_data_actions:
# ...
そして、このYAMLをアラーム用のデプロイスクリプトで読み込み、次のように展開します。

- YAML中のrule要素を使ってCloudWatchのアラームを登録
- YAML中のaction要素を事前に用意しておいたLambda Functionのテンプレートに埋め込む
- テンプレートをAWS Lambdaに登録
ここでの工夫は関連する処理を1つのファイルで近くに置くということです。
- トリガーとアクションを分離しない
- アプリケーション側でコンテナ配置ルールを管理
トリガーとアクションを並べ、CloudWatchの更新とLambdaへの反映までを一括で行えるようにすることで変更のし忘れを防止しています。
DaemonSetの更新
3つ目は特別なコンテナの管理です。ここが今回もっとも苦労した部分です。
このクローラー実行環境を支えるmesos agent nodeは、Amazon EC2 SpotFleetで宣言されており、
インスタンス自体もまた負荷に応じて増減するようになっています。
SpotFleetが作るインスタンスは起動と同時にユーザスクリプトでsystemctl restart mesos-slaveが宣言されているため、起動と同時にMesosクラスタの一員となります。
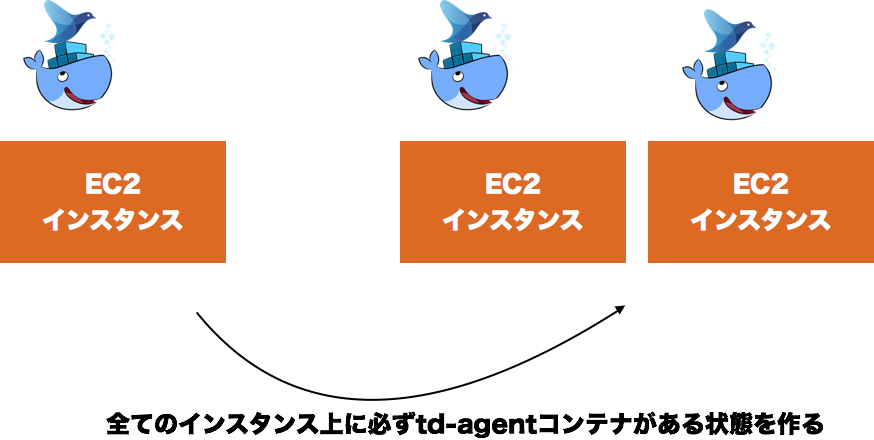
Mesosクラスタ的にはこれで終わりなのですが、この時AutoScalingに合わせて、td-agentコンテナの数を更新するいう非常に重要な処理を実行しています。
オーケストレーションツール比較表にありますが、Marathonには複数のコンテナを論理的に繋ぐ機能がありません。
Martahon 1.4系で待望のPod機能7が実装されたものの、2017/03/17時点で最新のMarathon 1.4.1では宣言されたPodがWeb UIから見えないという状況のため、導入はまだ時期尚早です。
そして、このPodが無いことで問題になったのがtd-agentコンテナです。
Podであれば必ず同じホスト上にコンテナが配置されますが、Podが無い場合アプリケーションコンテナとtd-agentコンテナは別ホストにデプロイされる可能性があります。
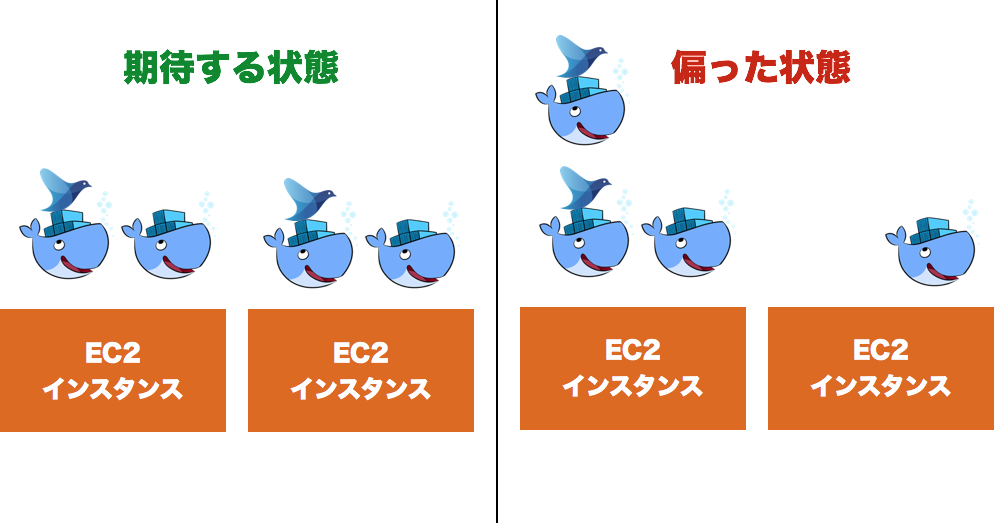
画像右の「偏った状態」になると、右側のインスタンスで動いているコンテナはtd-agentと通信できません。この場合、そのコンテナのログは全て捨てられてしまいます。
これの回避のため、必ず各ホストに1つのtd-agentコンテナが置かれる状況を作る仕組みDaemonSet8を動かしています。
DaemonSet実現のために、次の要素を組み合わせます。
- Docker Network
- User Defined Network
- net-alias
- Marathon
- constraints
- dependencies
- CloudWatch Events
- Lambda Function
まずDockerのUser Defined Network(以下、UDN)を作成します。
docker network create --subnet=172.20.0.0/16 mesos_slave_host_nw
次にtd-agentの宣言でnet-aliasを指定します。
# デプロイスクリプト用YAMLのtd-agentコンテナの宣言(抜粋)
:td_agent:
:id: /iqon/crawler/td-agent
:container:
:docker:
:image: xxxx
:network: USER
:parameters:
- :key: net-alias
:value: tdagent
これで同一ホストにデプロイされたコンテナからはtdagentという名前解決が可能になります。
UDNを作成するのはこのnet-aliasがUDN上でしか使えないためです。
次にconstraintsを宣言し、デプロイに制約を加えます。
:td_agent:
:id: /iqon/crawler/td-agent
:container:
:docker:
:image: xxxx
:network: USER
:parameters:
- :key: net-alias
:value: tdagent
:constraints:
-
- hostname
- UNIQUE
Maratahon(Mesos)はタスクを余裕のあるインスタンスで実行しますが、実行先インスタンスに幾つかの制約を持たせる可能です。
hostname, UNIQUEは、そのタスクを各ホストで高々1つまでしか起動できなくするという制約です。
次にCloudWatch Alarmを登録する仕組みを応用して、CloudWatch Eventを登録します。
:autoscaling:
:daemonize-container:
:rule:
:schedule_expression: "cron(*/2 * * * ? *)"
:action:
:method: 'PATCH'
:path: '/v2/apps/'
:targets: [ 'iqon/crawler/td-agent' ]
2分置きにイベントを発生させ、対応するLambda Functionを発火させます。
Lambda FunctionはMesosクラスタを構成するインスタンス数を取得し、actionに従ってMarathonにコンテナ数変更のリクエストを投げます。
[
{
"id": "iqon/crawler/td-agent",
"instances": "Mesosクラスタのインスタンス数"
}
]
最後に、アプリケーションコンテナへdependenciesとenvでtd-agentを指定してやれば完了です。
:parse:
:id: /iqon/crawler/parse
:dependencies:
- /iqon/crawler/td-agent
:env:
:TD_AGENT_HOST: tdagent # アプリケーション側で環境変数を読む
dependenciesが宣言されると、そのタスクはdependenciesで宣言されたタスクが実行されるまで自身の実行を待ちます。
ここまでの流れを整理します。
- td-agentコンテナはUDNのnet-aliesを利用し、tdagentという名前で名前解決が可能になる
- td-agentコンテナは
constraintsに従って1ホスト1コンテナが保証されている - アプリケーションコンテナはtd-agentコンテナが起動するまで起動を待つ
- 起動後はtdagentという名前でtd-agentコンテナを探す
- Lambda Functionによる変更で、ホスト数分だけtd-agentコンテナが用意されるため、
constraintsと合わせて各ホストには必ずtd-agentが存在する
ここの説明ではtd-agentに限っていますが、必要に応じて別のタスクも管理可能なようになっています。
コンテナイメージの更新
最後はコンテナイメージの世代更新についてです。

IQONクローラーのリポジトリでは、masterブランチ以外にdockerbuildという特別なブランチを用意しています。
circle.ymlからdockerbuildに関する部分を抜粋したものが次のYAMLです。
machine:
environment:
DOCKER_APP_IMAGE: xxxx
CONTAINER_NAME: yyyy
services:
- docker
dependencies:
pre:
- docker login -e $DOCKER_EMAIL -u $DOCKER_USER -p $DOCKER_PASS quay.io
- docker pull ${DOCKER_APP_IMAGE}; true
override:
- if [ ${CIRCLE_BRANCH} = 'dockerbuild' ]; then docker build -t ${CONTAINER_NAME}:${CIRCLE_SHA1} .; else true; fi
test:
# ...
deployment:
registry:
branch: "dockerbuild"
commands:
- docker push ${CONTAINER_NAME}:${CIRCLE_SHA1}
dockerbuildブランチ以外では、DOCKER_APP_IMAGEで宣言されたコンテナイメージをpullして利用します。
一方、dockerbuildブランチではpullされたコンテナイメージだけでなく、リポジトリのDockerfileを使いコンテナイメージを作成します。
テストを通過すればコンテナイメージがquay.ioにpushされるため、タイミングをみてDOCKER_APP_IMAGEを更新しmasterへマージします。
知らぬ間にコンテナが入れ替わって不具合発生というリスクを最小限に抑えるため、ここでも全てをアプリケーションのリポジトリにまとめる形式を採用しています。
刷新の効果
さて、少なくない工数をかけて行ったIQONクローラーver5.0(コンテナ化)ですが、その効果は目覚ましいものがありました。
| 効果 | |
|---|---|
| クロール時間 | 67%減 |
| 維持コスト | 70%減 |
| 保守コスト | Web UIで変更。設定が固まったらYAMLに反映 |
柔軟にワーカー数を変更できるようになったことで、
- クロール開始直後はHTMLをダウンロードするワーカーを増やす
- クロールの後半ではHTMLをパースするワーカーを増やす
ということが可能になり、その結果クロール時間は刷新前の3分の1になりました(67%減)。
また、インスタンスの維持コストも大幅に削減できました。瞬間的にはこれまでの3倍近い計算資源を用意して尚、トータルでは70%の維持コスト削減となっています。
これはSpotFleetを採用した影響が大きいですが、コンテナのメトリクスとしてワーカーが必要とするCPUとメモリが可視化されたため、集約度を上げられたことも要因の1つです。
3つめの保守コストについては言うまでもありません。
インスタンス起動・Chef実行・デプロイ・ワーカー起動という作業がWeb UI1つで誰でも行えるようになりました。
クラスタの運用はありますが、その手間を差し引いても極めて大きな保守コスト削減ができています。
まとめ
この記事では、Docker / Apache Mesos / Marathonを使った新クローラーシステムの紹介をいたしました。
今回のクローラー刷新では、アプリケーションを柔軟に実行できる環境の構築を目指して取り組み、
クロール実行時間の短縮と維持コスト、保守コストの大幅な削減とおよそ最高の結果を得ることができました。
またこの記事では、話の都合上クラスタ構築中の試行錯誤やコンテナ移行後の開発環境に関しての話題を丸々省略しております。
そちらは別記事としてまとめるつもりですが、もし興味を持っていただけるようであれば、はてブやSNSでリアクションをいただければ幸いです。まとめの励みになります。
長々と読んでいただき誠にありがとうございます。少しでも得るものがありましたら何よりです。
-
実際に、情報の反映が遅れたことが原因で「IQONとECサイトで掲載価格が違う」というお問い合わせをいただくことがありました ↩
-
クローラーであればアプリケーション+td-agentといった組み合わせ ↩
-
その他のオーケストレーションツールとしてDocker Swarm, HashiCorp Nomadがありますが、ドキュメントを読んでみてしっくりこなかったため検討対象から外しています ↩
-
当然、クラスタに所属するインスタンスはタスクの実行環境を持っておく必要があります ↩
-
cpusの設定はDockerのcpu-sharesオプションに反映されます。そのためインスタンスに余裕さえあれば必要に応じて20%以上が割り当てられることもあります ↩
-
KubernetesにはPodというコンテナのグルーピング機能がありPodに所属するは同一ホスト上にあることが保証されます。MarathonのPodも同様です ↩
-
Kubernetesには、各ホストで必ず動いていて欲しいコンテナを宣言するDaemonSetという仕組みがあり、それに倣いました ↩