tl;dr
- 本論文は2つのドメイン間の変換という問題に対して、汎用的に利用できる機械学習手法に関するものである。
- e.g. 翻訳:英語から日本語、日本語から英語の翻訳
- 画風変換: 自然画像から、モネの絵風に、モネの絵から自然画像風に変換
- Dual learning: あるデータを異なるドメインに変換し、変換したデータから元のデータを復元できるかを元に、双方向の変換を学習
- 主エージェント以外は教師付き学習などで事前に学習しておき、Dual learning中はパラメータを固定する。主エージェント以外は主エージェントを誘導することに使われる。
- 教師なし・教師あり機械翻訳でSotA
- CycleGANをマルチエージェント化することで、CycleGANよりも性能向上
はじめに
Ryobotさんによると 先日Open Reviewに公開されたICLR 2019への投稿ではなんと6本も機械翻訳のSotAを名乗る論文が現れたとのことです。
以前の投稿では、3位の"Pay Less Attention with Lightweight and Dynamic Convolutions"について紹介しましたが、今回は1位であった"Multi-Agent Dual Learning"を紹介します。

(From @_Ryobot on Twitter. Red circle is by the author.)
背景: Dual Learningとは
多くの問題はDualな (二重な) 性質もっています。例えば翻訳では、英語から日本語、日本語から英語の翻訳というように2つのドメインを行き来します。あるいは、画風変換では、自然画像から、モネの絵風に、モネの絵から自然画像風に、というような変換を行います。
このような問題では、たとえば、英語 ($x \in \mathcal{X}$とする)と日本語 ($y \in \mathcal{Y}$とする) が対応づけられたコーパス(対訳コーパス)から日本語翻訳 $f: \mathcal{X} \mapsto \mathcal{Y}$と英語翻訳$g: \mathcal{Y} \mapsto \mathcal{X}$をそれぞれ教師付き学習として学習してもよいでしょう。実際、機械翻訳の界隈で標準的なアプローチは、教師付き学習に基づいた方法です。
一方で、そのような相互変換が可能な場合、日本語翻訳をした結果を英語翻訳し($g(f(x))$)、元の英語を復元できるかを元に学習できないかと考えるのは自然な発想でしょう。
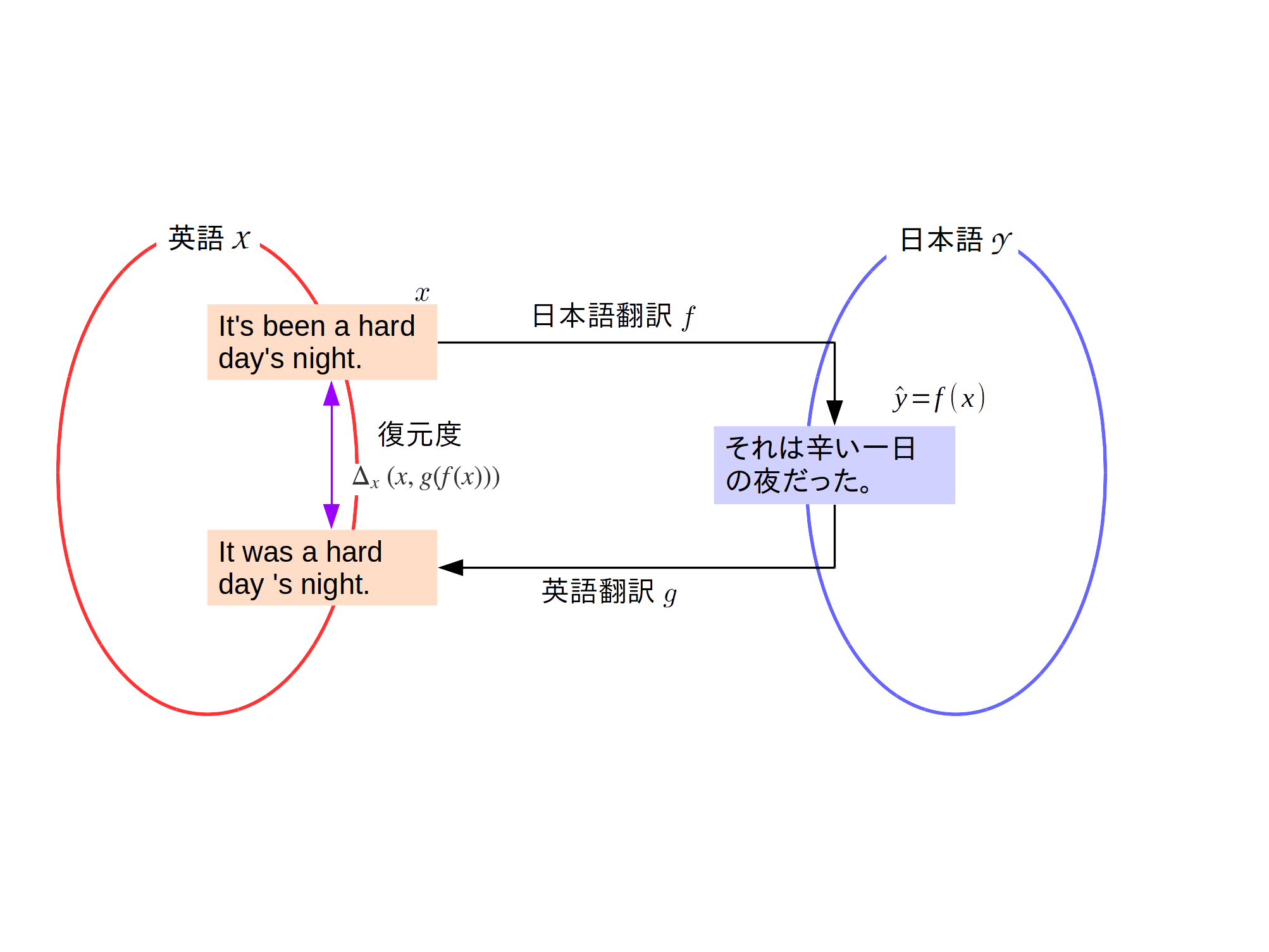
つまり、2つのデータの違いを表す関数$\Delta_x: \mathcal{X}\times\mathcal{X} \mapsto \mathbb{R}$を用い、 $\Delta_x\left(x, g(f(x))\right)$ と $\Delta_y\left(y, f(g(y))\right)$ を最小化するように学習します。そうすることで、ペアとなっていないデータを学習に用いてデータ量を増やすことや、そもそもペアがない設定で教師なし学習を行うことができます。このような自己復元に基づく機械学習手法をDual learningと呼びます1。Dual learningとして有名な手法にCycleGANが挙げられます。
本研究では、この変換に複数にエージェントを使うことでDual learningの性能を向上すること目指します。具体的には、ドメイン間の変換を行う関数$f$、$g$を複数用意し、その多数決に基づいて変換を行います。
方法
複数のエージェント$f_i$、$i\in {0, 1, \cdots, N-1}$を考えます。本研究で最小化したい損失は、次の式によって与えられます。
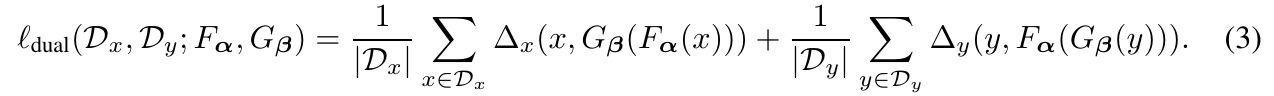
ただし、
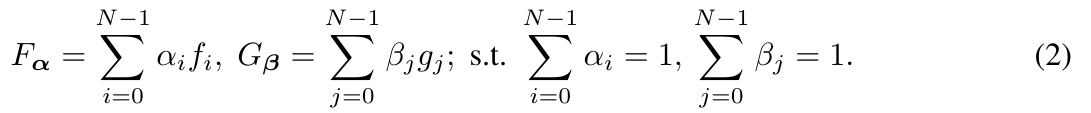
$\alpha_i$、$\beta_i$はエージェントの信頼度を表す重みですが、本研究では単に$1/N$と均等割りしています。要は各エージェント(=別の初期値で学習した変換関数)で投票しているわけですね。
どの程度復元できるかを表す関数$\Delta_x: \mathcal{X}\times\mathcal{X} \mapsto \mathbb{R}$は次式で与えられます。
\Delta_x\left(x, G_{\mathbf{\beta}}(F_{\mathbf{\alpha}}(x))\right) = - log \sum_{\hat{y}\in \mathcal{Y}}P\left(\hat{y}|x; F_{\mathbf{\alpha}}\right)P\left(x|\hat{y}; F_{\mathbf{\alpha}}\right)
直感的にいうと、ありうる全ての中間出力$\hat{y}$に対して、その$\hat{y}$を介して$x$を完全に復元できる確率をもとめ、その確率を最大化(マイナスがついているので)しようとするわけです。
この式は最適化が難しいので、実際にはこの式の上界を最小化します。
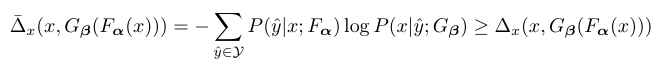
やはり気になるのが$\sum_{\hat{y}\in \mathcal{Y}}$の部分で、ありうる全ての中間出力$\hat{y}$に関して上記の式を計算することは事実上不可能です(「ありうる全ての中間出力」というのは機械翻訳でいえば、ありうる日本語の並び方全部ですので、無限個存在します)。そこで、本研究では、最も確率が高い$\hat{y}$を1つだけサンプリングします。....というと、聞こえがいいですが、要は$G_{\mathbf{\beta}}(F_{\mathbf{\alpha}}(x))$を計算します。上記の損失関数は微分可能であり、サンプリング部分も簡略化したので、普通にバックプロパゲーション+ミニバッチ最急降下法で学習できます。
さて、これだけですと、普通にアンサンブル学習のようになってしまっていますが、本研究では$f_0$、$g_0$のみを学習するところがポイントです。他の$f_i$、$g_i$については、たとえば教師付き学習によって事前に学習しておき、Dual Learning中には重みは固定します。教師なし学習に提案手法を使いたい場合は、教師なし学習で$f_i$、$i\in {1, 2, \cdots, N-1}$を初期化しておきます。また、学習時に$f_i$、$i\in {1, 2, \cdots, N-1}$を使いますが、予測時には$f_i$、$i\in {1, 2, \cdots, N-1}$は使わず$f_0$のみを使います。
これは私の理解ですが、普通のDual Learningだと$f$と$g$の学習が互いに依存してしまっており、卵が先か、鶏が先かの要領で学習がうまくゆかないのではないかと思います。上記のように学習済みの変換器を並行して使うことによって、$f_0$と$g_0$の学習を他の学習器で誘導しているような形になるのではないでしょうか。
ちなみに、提案手法に教師付き学習を混ぜたいときは、普通に教師ありコストを上記の損失に足して、その項についてもバックプロパゲーション+ミニバッチ最急降下法で学習します。
実験
機械翻訳
Transformer2をベースとしたモデルで提案手法を評価します。
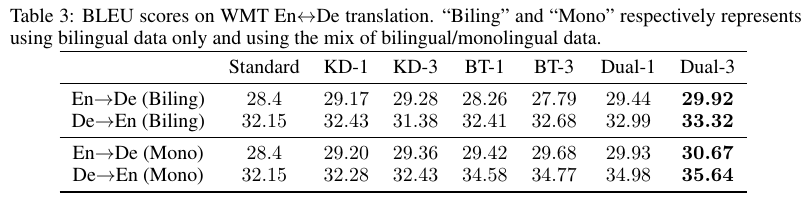
WMTデータセット上でSotAでした。前述したようにICLR 2019でSotAに名乗りをあげた全論文の中でも1位です。ポイントなのは、エージェント1つのDual learning (Dual-1) も、ICLR 2019のに2位にまけてこそいますが、通常のTransformer (Standard) よりも大幅な改善がみられ、Dual Learning自体が非常に強力な考え方であることを示しています。
(from the paper)
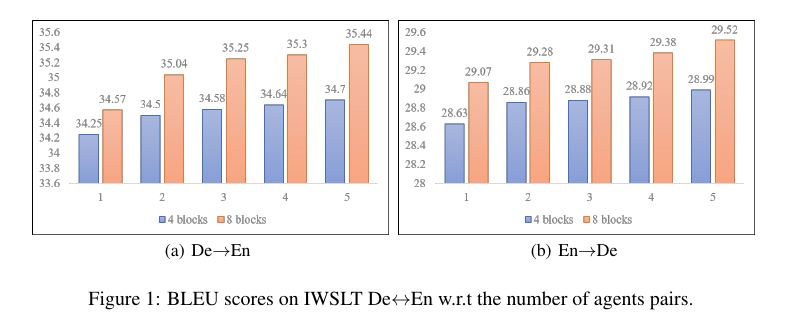
上の図はエージェントの数と性能をプロットしたグラフです。エージェントを増やすと性能は向上しますが、性能の伸びは鈍化しているので、各変換方向につきエージェントの数 = 3程度が適当だと結論づけています。
なお、教師なしの機械翻訳でも、(教師なしの機械翻訳の中で)SotAでした。
教師なし機械翻訳
CycleGANをマルチエージェントした提案手法と、CycleGANを比較しています。提案手法のほうがよかったと主張していますが、どうでしょうか... (いつも思うのだがGANの評価はどう反応して良いのだか困る....)

(from the paper)
先行研究
本研究は当然ながら既存のDual Learningに関する論文から強く影響をうけています。Dual Learning+アンサンブル学習なんじゃないの、というつっこみには2つ反論を用意しています。
- アンサンブル学習と違い、学習時に複数のエージェントを使い、推定時は1つのエージェントしかつかわない。アンサンブル学習は、学習時には各エージェントを別々に学習し、予測時に複数エージェントを用いる。
- 上記の違いから、学習、推論時の計算コストがアンサンブルほど高くない。
また、学習済みエージェントで主エージェントを誘導するという考え方はDistillation3とも関係性が深いと考えられます。
コメント
- 性能は華々しいが、やはりDual Learning+アンサンブル学習が拭えない。
- 実験にて普通のアンサンブルとの性能差を比べてほしかった。正直アンサンブルしたほうが性能よかったんじゃないか。
- 仮にアンサンブル学習よりよかったとして、なぜそうなったかについての分析がほしい。
- Dual Learningは非常に強力なフレームワーク。今後色々な問題への適用が進むと思われる。
著作権に関して
本論文で使用している表はすべて論文からの抜粋です。特に出展が示されていない図、ならびに本文はCC-0で公開しています。
編集可能な図はこちら。
-
そこまでちゃんと定着した用語ではありません。 ↩
-
Vaswani et al. 2017. Attention is All you Need. NIPS 2017. ↩
-
他のエージェント(複数の場合もありうる)の推定結果を真似るように主エージェントを学習する。他のモデルが学習した知識を蒸溜 (distillation) するので、このような名前で呼ばれる。 ↩