はじめに
2020年3月4日から3月31日の期間で行われた、Neural Network Console Challenge(NNC-Challenge)というコンテストに参加しました
元々画像処理分野には興味があり、いつの日か何らかの形でアウトプットしたいなぁと考えていたので丁度良い機会でした
コンテストの最後に、自分が行ったことをプレゼンテーション形式でアウトプットする必要がありましたので、Qiitaに記事として書かせていただきました(読み難い箇所が多々あるかと思います。お許し下さい🙇♂️)
簡単にですが、コンテストの概要です
- 配布された1万枚の画像データを対象に深層学習して、AIシステムを開発
- 学習用データ提供:PIXTA
- 開発プラットフォームとして、SONY製GUIツールのNeural Network Consoleを使用
-
全4種類のテーマから、挑戦したいテーマを一つ選択
- 「新しいオノマトペ(擬音語/擬声語/擬態語)による画像カテゴリ分類」
- 「画角/焦点距離による画像分類」
- 「人の感情による画像分類」
- 「自由設定」
優秀者には賞金が贈られる(画像参照)

テーマ
「画角/焦点距離による画像分類」枠とし、人物画像から獲得した顔画像の目線がカメラ目線か非カメラ目線かの分類を行いました

学習用データ提供:PIXTA
応用先は、視線検知を用いたカメラの追加機能や新たなPC操作、マーケティングに結びつくデータ(来店者はどの商品を注視していたか=興味があるか) といったように多岐に渡ります
やったこと
一覧です
1. アノテーション
2. 学習データ
3. アーキテクチャ
4. 結果
5. 考察
6. 追加実験
7. 追加実験の結果
1. アノテーション
1万枚の画像を全部アノテーションするのはしんどいので、半自動な方法を採りました
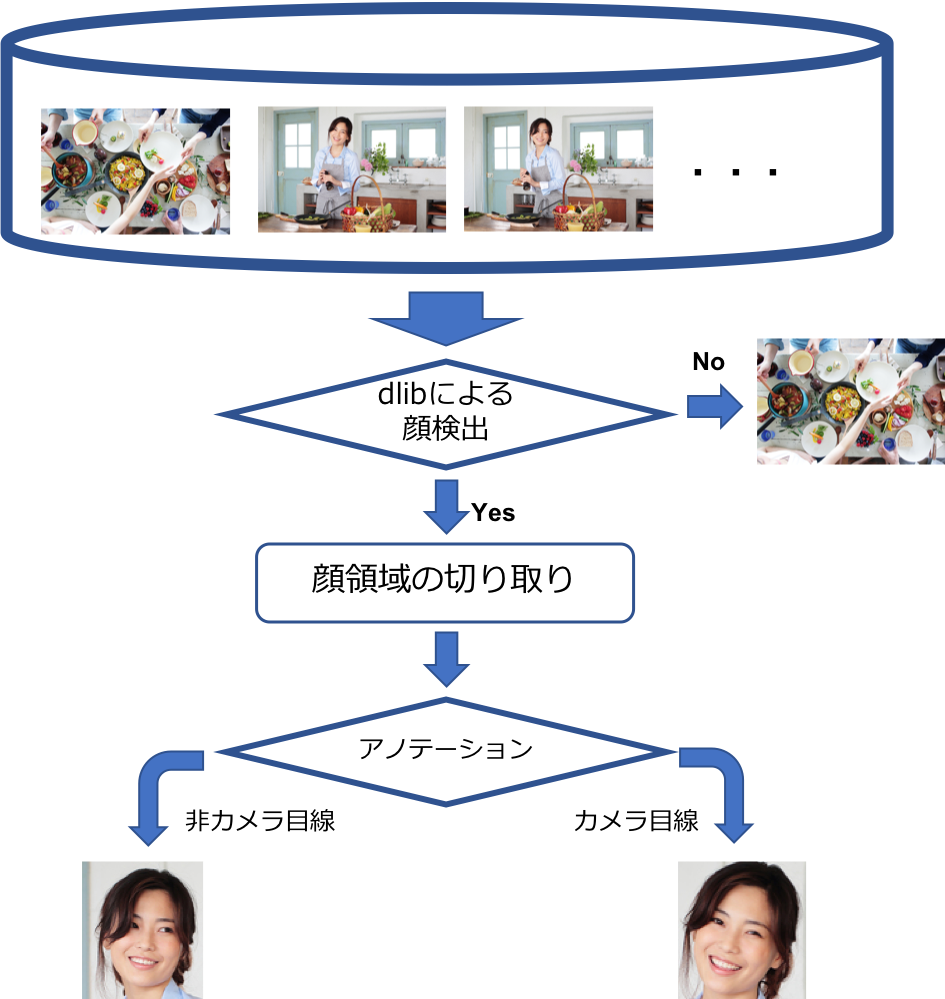
学習用データ提供:PIXTA
手順
- 顔検出ライブラリdlibを用いて、①顔画像が検出できる画像②顔検出が一部分しかされない画像③顔が検出されない画像の3種類に仕分ける
→ 結果、①の画像は5350枚、②の画像は157枚、③の画像は4493枚と分類された
- ①の画像から顔画像を検出し、学習のために以下の前処理を行う
- 顔画像は64*64の正方形にリシェイプ (画像サイズは統一する必要あり)
- 画像に複数人の顔画像が検出された場合、それぞれを顔画像として保存 (データのカサ増し)
→ 結果、7819枚の顔画像が検出されました
- この内、①の画像を自分でカメラ目線か非カメラ目線かのアノテーションを行いました(ここが辛かった...)
→ 結果、カメラ目線の顔画像は2623枚、非カメラ目線の顔画像は5102枚、例外は94枚になりました
スクリプト
dlibを用いた顔検出
# -*- coding: utf-8 -*-
import glob
import dlib
import cv2
import pandas as pd
import datetime
import os
#候補画像を格納したディレクトリパス
IMG_PATH = "./data/NNC-Challenge_Dataset/*.jpg"
def face_detect(img_list):
# print(img_list)
# 顔領域を検出する識別器呼び出し
detector = dlib.get_frontal_face_detector()
image_class_data = pd.DataFrame(index=[])
img_count = 1
for img_path in img_list:
img = cv2.imread(img_path, cv2.IMREAD_COLOR)
cv_img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
faces = detector(cv_img, 1)
# 顔領域が検出出来た場合
if faces:
image_class_data = image_class_data.append([[img_path,"0","there are people in pic(maybe..)"]])
for face in faces:
# 候補画像サイズ取得
height, width = img.shape[:2]
# 顔領域の座標点取得
top = face.top()
bottom = face.bottom()
left = face.left()
right = face.right()
# イレギュラーな顔領域は無視
if top < 0 or left < 0 or bottom > height or right > width:
print("イレギュラー",top,bottom,left,right)
image_class_data = image_class_data.append([[img_path,"1","ID"+str(img_count)+": face detect is not good shape(maybe..)"]])
DIR_split = img_path.split("/")[-1]
os.system("cp "+img_path+" ./classification_faceonly/1/"+str(img_count) + '.jpg')
break
# 顔領域をトリミング
dst_img = img[top:bottom, left:right]
# 顔画像サイズを正規化して保存
face_img = cv2.resize(dst_img, (64,64))
new_img_name = '././classification_faceonly/0/'+str(img_count) + '.jpg'
cv2.imwrite(new_img_name, face_img)
img_count += 1
# 顔領域が検出出来なかった場合
else:
DIR_split = img_path.split("/")[-1]
os.system("cp "+img_path+" ./classification_faceonly/2/"+DIR_split)
image_class_data = image_class_data.append([[img_path,"2","no people(maybe..)"]])
# dev用
# if img_count > 60:
# image_class_data.columns = ["directory","classfication","reason"]
# image_class_data.to_csv("./out_facedetect_dev_"+str(datetime.datetime.today())+".csv",index=False)
image_class_data.columns = ["directory","classfication","reason"]
image_class_data.to_csv("./out_facedetect_"+str(datetime.datetime.today())+".csv",index=False)
if __name__ == '__main__':
images = glob.glob(IMG_PATH)
face_detect(images)
2. 学習データ
学習に用いる画像はカメラ目線画像・非カメラ目線画像のどちらも2623枚にしました
train:validation=8:2の比率で学習しましたので、train4196枚、validation1050枚です
スクリプト
NNCにアップする.csvファイルの作成
# -*- coding: utf-8 -*-
# trainとvalidationに分けたcsvファイルを生成
import numpy as np
import pandas as pd
import glob
import datetime
image_class_data0 = pd.DataFrame(index=[],columns=["x:image","y"])
image_class_data = pd.DataFrame(index=[],columns=["x:image","y"])
l0 = glob.glob("./classification_faceonly/0/anotation/0/*.jpg")
l1 = glob.glob("./classification_faceonly/0/anotation/1/*.jpg")
# カメラ目線と非カメラ目線の画像の枚数を同じにする
leng_0 = len(l0)
leng_1 = len(l1)
if leng_1 > leng_0:
leng_1 = leng_0
else:
leng_0 = leng_1
# y: 0 (カメラ目線)
image_class_data0["x:image"] = l0[:leng_0]
num_array = np.zeros(leng_0)
image_class_data0["y"] = num_array
# y: 1 (非カメラ目線)
image_class_data["x:image"] = l1[:leng_1]
num_array = np.ones(leng_1)
image_class_data["y"] = num_array
print(image_class_data0.head())
print(image_class_data0.describe())
print(image_class_data.head())
print(image_class_data.describe())
# trainとvalidationに分ける (8:2)
image_class_data0_train = image_class_data0[:int(leng_0*0.8)]
image_class_data0_validation = image_class_data0[int(leng_0*0.8):]
image_class_data_train = image_class_data[:int(leng_0*0.8)]
image_class_data_validation = image_class_data[int(leng_0*0.8):]
# trainとvalidationそれぞれでconcat処理
df_concat_train = pd.concat([image_class_data0_train, image_class_data_train])
df_concat_validation = pd.concat([image_class_data0_validation, image_class_data_validation])
print(df_concat_train.describe())
print(df_concat_validation.describe())
df_concat_train.to_csv("./dataset_train.csv",index=False)
df_concat_validation.to_csv("./dataset_validation.csv",index=False)
3. アーキテクチャ
下図に示す4種類のネットワークの性能を比較します
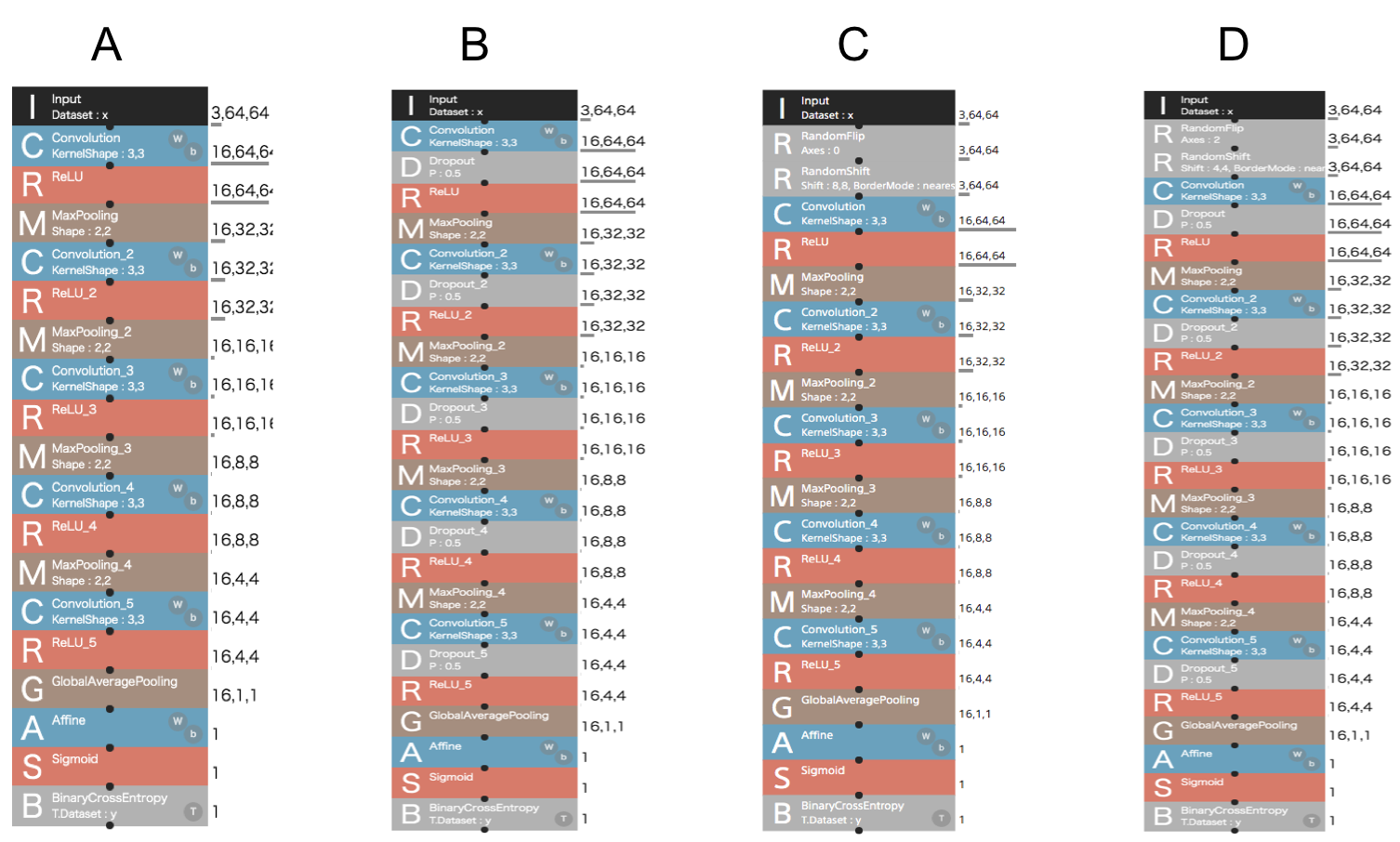
詳細
ハイパーパラメータ等の設定
- 活性化関数(1~4層):ReLU、活性化関数(5層):Sigmoid
- 損失関数:Binarycalcrossentropy
- 最適化関数:Adam
- 学習率:0.001
- Batchsize:512
A:SimpleCNNネットワーク
- CNNからなる5層ネットワーク
B:A + 各層にDropoutネットワーク
- Aの各層にDropoutを挟んだネットワーク
C:A + ImageAugmentation
- RandomflipとRandomShiftレイヤを用いてデータ増量
D:C + Dropout
- 色々組み合わせたネットワーク
- (何となくですが、これが一番良い精度になりそう)
4. 結果
| A. SimpleCNN | B. A+Dropout | C. A+ImageAugmentation | D. C+Dropout | |
|---|---|---|---|---|
| CPU学習時間 | 28分4秒 | 未調査 | 未調査 | 未調査 |
| GPU学習時間 | 1分12秒 | 1分17秒 | 1分44秒 | 1分44秒 |
| 精度(GPUの場合) | 0.69 | 0.63 | 0.71 | 0.63 |
※使用GPU:Tesla®︎k-80×1
最も良い精度になったのは、Cのネットワークで精度は0.7114でした
処理速度に関して
AのネットワークではGPUはCPUよりも処理速度が約28倍速いことが判りました
他のネットワークでもCPU上での学習を行うべきですが、時間コストが高いので今回は割愛させて頂きました、すみません
気力があれば更新したいと思います
5. 考察
アーキテクチャ
ImageAugmentationによるデータの増量のおかげで、Aよりは良い精度を出すことに成功しました
一方、Dropoutが含まれているネットワークのBとDがあまり良い精度ではありませんでした
Dropoutの確率値をデフォルトの0.5にしていましたが、今回のデータ量に対しては数値が大き過ぎたのかもしれません
多層化、BatchNormalization等も使っていきたいですね
(NNCは操作が直感的で分かりやすいので色々なレイヤを試してみたいです)
あとBatchSizeがデータ量に対して大分大きいので、もっと小さくして再実験したいです
学習
ネットワークの初期値は乱数なので、評価を行う際は複数回の推論を行うべきです
実は複数回の推論自体は行なったのですが、何故かConfusion Matrixが表示されなかったのでお蔵入りにしました
困ってます…、解決方法わかる方いらっしゃればご教授頂ければと思います…!
↓↓↓ 解決しました! ↓↓↓
1プロジェクトに比較用のネットワークを複数作っていたのが原因でした
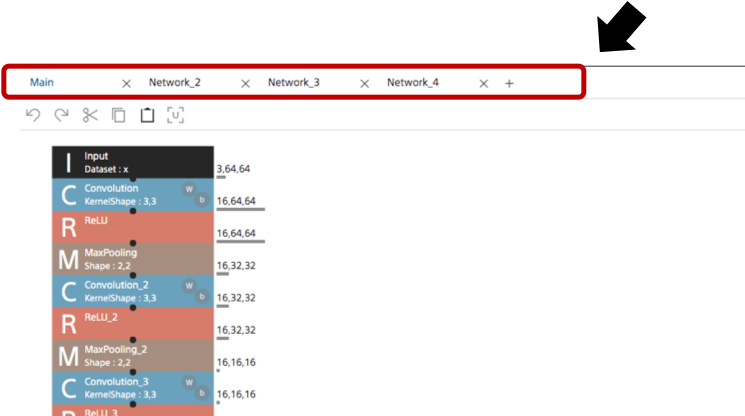
ConfigのNetwork設定を対象ネットワークの名前に変更すれば良いかと思ってたけど、それは違うんですね
毎回プロジェクト立ち上げる のが無難ですね
6. 追加実験
考察を基に、ネットワークのハイパーパラメータやレイヤをベターな設定にしてみました
アーキテクチャは下の2通り
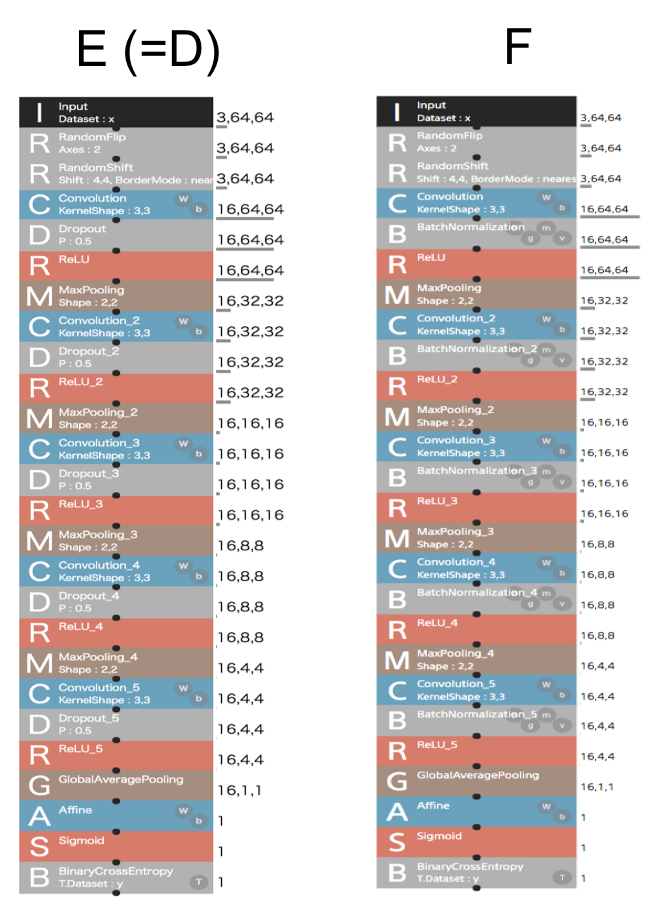
詳細
変更したハイパーパラメータ等の設定
- Epochs:100 → 300
- BatchSize:512 → 128
- 推論回数:1回 → 5回
E:Dのハイパーパラメータを変更したネットワーク
- Dropoutの確率値:0.5 → 0.2
F:EのDropout層をBN層に変更したネットワーク
- Dropout層をBatchNormalization(BN)層に変更
- BNのパラメータはデフォルト
7. 追加実験の結果
| E. Dのハイパーパラメータを変更したネットワーク | F. EのDropout層をBN層に変更したネットワーク | |
|---|---|---|
| GPU学習時間 | 5分11秒 | 5分26秒 |
| 精度(GPUの場合) | 0.84 | 0.78 |
Eにおいて、最高値の0.84ポイントを示すことに成功しました!
ハイパーパラメータを調整する事でかなり精度が向上しましたね笑
Eは同じアーキテクチャのDと比較して、精度が0.21ポイント向上しました
Dは元々これだけの能力を秘めていたんだなぁ
脳死でデフォルトパラメータに設定するのはダメ、、、
データに応じたパラメータ設定の重要性 を深く理解しました
Fもパラメータの設定次第でグッと精度が上がる可能性あるかもですね
(あとABCネットワークも再調査するべきでしたね、忘れてた、、、)
まとめ
- Neural Network Consoleを用いて人物画像の視線分類を行った
- アノテーションはdlibによる顔検出機能を用いることで半自動にした
- 最初の実験ではあまり良い精度は出なかったが、ハイパーパラメータを再設定することで、最高値0.84ポイントを出すことに成功した
展望
- よりリッチなデータセットの構築を目指すならdlibによる自動分類は行うべきではないですね、全データを人手でアノテーションする方がやっぱり良くなるはずです、時間はかかりますが…

学習用データ提供:PIXTA
- ResNet等他のネットワークアーキテクチャにも挑戦したいですね
感想
アウトプットし終えた今となっては、本コンテストは勉強になる内容が多く、大変有意義な機会になりました!
それはひとえにSONYの社員さんが直々にYouTubeにアップされている動画コンテンツのお陰でした。
ちょっと困った時、トラブルシューティング的に確認できたのはありがたかったです。
NNCは今回初めて触りましたが、大分楽に導入部分を理解する事が出来ました。
NNCの説明以外にも深層学習のアルゴリズムや画像分類に特化した動画等、とにかく色々なジャンルの動画がアップされていて、最初はその多さに驚かされました。(現在も頻繁に動画をアップされていますね。凄い。)
NNCを使って画像分類したい!とか深層学習に興味あるけど何から始めればいいか分からねぇ...、みたいな皆さんには是非観ていただければと思います!
本コンテストは、今後もこういったコンテストに参加していきたいと思えるきっかけになった良きコンテストでした。
主催者様、ありがとうございました。
参考記事・URL
OpenCVとdlibの顔検出機能の比較
- dlibを用いた顔検出用スクリプトの参考にしました
NNCチュートリアル:アンサンブル学習や複数回評価による手軽な精度向上テクニック
- ネットワークアーキテクチャの参考にしました