この記事をご覧の方に
この記事は下記記事の部分集合です。
徐々に出していくためにこの記事が存在していますが、すでに完全なものが存在していますので、これから読む方は下記をどうぞ。
前回の要約、【要約】The world beyond batch: Streaming 101の続きになります。
前回と同じく、一気に読んで訳したものですので、相応に粗く、用語の統一も多分ずれがあり、流れがわかればいい内容となっていますので、その前提で。
ただ、コメントは歓迎します。ここにまとめた私自身も理解できていない点が多々あると思いますので。
以後の内容はオライリーの記事のライセンスより、CC BY-NC-SA 1.0になります。
The world beyond batch: Streaming 102
導入
もし前の記事(Streaming 101)を読んでいないなら、まず読むことをお勧めする。
以後の内容を論じる上での前提事項を説明しているし、そこで述べられた内容について相応に理解していることを前提として、本記事は書かれているから。
また、本記事の一部ではアニメーションを使用しているため、もし印刷して読もうと考えている場合にはそれについて留意いただきたい。
でははじめよう。
簡単に要約すると、前回私は3つの内容について焦点を当てていた。
1つ目は「技術定義」。"ストリーム処理"についてどういうものを意図するか、明確に定義した。
2つ目は「バッチ VS ストリーム」。2つのシステムの比較を行い、「正確性」と「時間について推測可能なツールであること」の2要素が揃えば、ストリーム処理システムがバッチ処理システムの純粋な上位互換になり得ることを説明した。
3つ目は「データ処理パターン」。バッチ処理システム、ストリーム処理システムを用いて無限のデータ、有限のデータを処理する際の共通的なパターンについて説明した。
この記事においては、前回説明したデータ処理パターンについてより詳細かつ明確に踏み込んだ上で、更にその先に焦点を当てたい。
この記事の骨子は下記の2つの章からなる。
- Streaming 101 振り返り
Streaming 101で紹介したコンセプトについて振り返り、実例について概要を示す。
- Streaming 102
Streaming 101の内容を受け、無限のデータを扱う上で重要な要素となる追加の概念について詳細を動作例を基に説明する。
この記事を一通り読むことで、頑強なout-of-orderなデータ処理に必要となる主要な原則や概念の基本についておさえることができる。
この概念をおさえたストリーム処理は伝統的なバッチ処理を超えるツールとなり得る。
具体的にどのように構成をすればいいかを示すために、Google Cloud DataflowのSDKのコードと、概念を示すアニメーションを用いる。
SparkやStormといった他のシステムに通じている方もいる中でGoogle Cloud Dataflowを用いる理由は、概念を示すために十分な表現力をもつシステムが現状存在しないため。
ただ、徐々に他のプロダクトもこの方向に向かいつつあるのはいい傾向だと感じる。
さらに、GoogleからはApache Beamというプロダクトをdata Artisans、Cloudera、Talendといった会社と共に公開し、これを用いることでよりオープンなコミュニティとエコシステムの上でこのような頑強なout-of-orderなデータ処理が可能になるだろう。
でははじめよう。
前回の概要と今後の流れ
Streaming 101で、はじめにいくつかの用語の定義を明確にしている。
有限のデータと無限のデータの違いについて明確にしている。
有限のデータソースは有限のサイズのデータを保持し、しばしば「バッチ」データとして扱われる。
無限のデータソースは無限のデータを有しており、しばしば「ストリーム」データとして扱われる。
まずはこういった形で有限だからバッチ、無限だからストリームという形で紐づけるのはミスリーディングになるので、そうではないことを示している。
その後、バッチ処理エンジンとストリーム処理エンジンの違いについても述べた。
バッチ処理エンジンは有限のサイズのデータのみを念頭に置いた設計になっており、ストリーム処理エンジンは有限のデータに加えて無限のデータに対しても考慮した設計となっている。
ここではバッチ処理、ストリーム処理は実際にそれを実行する実行エンジンにのみ紐づけて考えてほしい旨を記述している。
この定義の後、無限のデータを扱う上で2つの基本かつ重要な概念について説明している。
1つ目として、Event Time(いつそのイベントが発生したかを示す時刻)とProcessing Time(いつ対象のデータを処理したかを示す時刻)の区別がある。
もし実際にイベントが発生した時刻を基にした厳密な解析をしたい場合、Event Timeに基づいて処理を行う必要があり、Processing Timeを用いては解析に支障が出る、
2つ目として、Windowing(データを一時的な区切りを用いて分割すること)について説明した。
これは無限に発生し続け、終了しないデータソースからのデータを処理するにあたり、共通的なアプローチのうちの一つ。
基本的な例として、Windowingには固定長WindowとSlidingWindowがあることを示し、より複雑な形式のWindowingとして、Session(Windowサイズはデータによって決定し、アクセスがない時間が一定時間に達したらWindowが区切られる方式)と用途について示した。
これらの2つの考えに加えて、下記の3つについて掘り下げる。
Watermarks
WatermarkはEvent Timeベースでどこまで処理が完了したかを示す概念。
WatermarkがXの値を取った場合、「Event TimeがXより小さいデータは全て観測されている。」ことを示す。
つまりはWatermarkは無限のデータを観測している状態において、どこまで進んだかを示すメトリクスとして動作する。
Triggers
Triggerはウィンドウ出力をどのタイミングで実体化するかをいくつかの外部の状況を基準に宣言するためのメカニズム。
Triggerはいつ出力値が実体化するべきかについて柔軟性を実現する。
また、Trigger機構によってウィンドウ出力がデータが更新される毎に複数回出力するということも可能になる。
これによって、上流からのデータが変化したり、Watermarkより遅れたデータが到着した際に、投機的な出力を行える。
(実際のところ、モバイルの環境下においては、電波圏外から戻るなど、端末が記録したデータが実際に到着するまでに大きく遅れることは頻繁に発生する。)
Accumulation
Accumulationモードは同一ウィンドウ内で複数の結果が算出された場合の関係性や動作を定めるもの。これらの結果は完全に切り離されて用いられるケースもあるかもしれない。(例:セッション生存期間を超えたアクセス同士の関連など)違うモードでは、異なるセマンティクスを保持し、計算方法も変わってくるだろう。
最後に、これらの概念の関係を理解しやすくするために、ある4つの質問について再度確認してみる。これらは無限のデータを処理するあらゆるシステムで絡んでくる問いだと考えるため。
- What results are calculated?
この質問に対しては、データパイプライン上にどのような変換が存在するかが回答になる。
これには合計やグラフ生成、機械学習モデル訓練等が含まれる。
それは伝統的なバッチ処理でも同様に回答が可能。
- Where in event time are results calculated?
この質問に対しては、データパイプライン上のEvent Time Windowingの使い方が回答になる。
これにはStreaming 101で挙げられているWindowingの種別(固定長、スライディング、Session)、Windowingに関係ないユースケース(Streaming 101の時間非依存化参照、伝統的なバッチ処理もこちらに帰結することが多い)や、より複雑なWindowing、時間制限オークションといったものが含まれる。
また、これにはシステムへの到着時刻をEvent Timeとして割り振る場合、Processing Time Windowingも同様に含まれることに留意いただきたい。
- When in processing time are results materialized?
この質問に対しては、WatermarkとTriggerの使い方が回答となる。
これには無数のバリエーションが存在するが、最も共通的なパターンとしては、Watermarkを与えられたWindowの処理が完了した時点とし、Triggerを早期結果出力(投機的に発生したり、部分的な結果であってもWindowingの処理が完了する前に出力するなど)、遅延結果出力(このケースにおいては、Watermarkはどこまで処理したかの見積もりでしかなく、Watermark完了後もデータが到着するケースはある。)に用いるもの。
- How do refinements of results relate?
この質問に対しては、どのようなAccumulation方式・・・廃棄(結果が独立し、排他的な場合)、積算(遅延到着した場合、前の値に追加)、積算+後退(積算値への追加と、その前に出力した結果の見直し)を使用するかが回答となる。
これらの質問についてはこの記事の後でより詳細に掘り下げる。
また、以後はどの質問に紐づいた内容なのか、What / Where / When / How のように文字に色を付けて判別する。
Streaming 101 振り返り
はじめに、Streaming 101で示されたコンセプトを振り返ろう。
だが、今回は例と共に先ほどの質問と共に併せて説明するため、より深く掘り下げられるはずだ。
- What transformations
伝統的なバッチ処理にこの「What results are calculated?」という質問を適用した場合、答えは「変換」となるだろう。
たとえ、読者の多くは既に古典的なバッチに精通しているとしても、まずは我々はこのことについて説明する。
まずはこれが土台となり、その先に様々な概念を追加していく形となるため。
この節においては、一つの例、10個の値で構成されるキーつき整数の合計を算出する処理を以て説明する。
もし、読者がもう少し現実的な例に落とし込みたい場合、モバイルゲームの独立したスコア群を元に合計のスコアを算出する例を考えればいい。
また、利用料を監視して支払いを算出するケースでもいい。
これらの例に対して、Dataflow Java SDKの擬似コード片を組み込み、よりデータパイプラインの定義を明確にする。
擬似コードからは具体的な入出力ソースといった詳細は省き、単純な名称を用いることで例を明確にしている。
そういった要素を除けばこの後説明するコードは実際のDataflow Java SDKのものとなっている。
興味がある方のために、実際のコードの例のリンクを後で示そう。
もし読者が多少なりともSpark StreamingやFlinkを知っている場合、Dataflowのコードが何をしているかの意味を捉える上で助けとなるだろう。
はじめにDataflowを理解するための2つの基本的な概念について説明する。
- PCollections
これはデータセット(巨大なものにもなり得る)を示しており、並列の変換を通して生成されるものでもある。
- PTransforms
これはPCollectionsに適用することで、新たなPCollectionsを生成する変換を示す。
PTransformsは要素単位の変換だったり、複数の要素を統合するものだったり、または他のPTransformsの組み合わせだったりする。
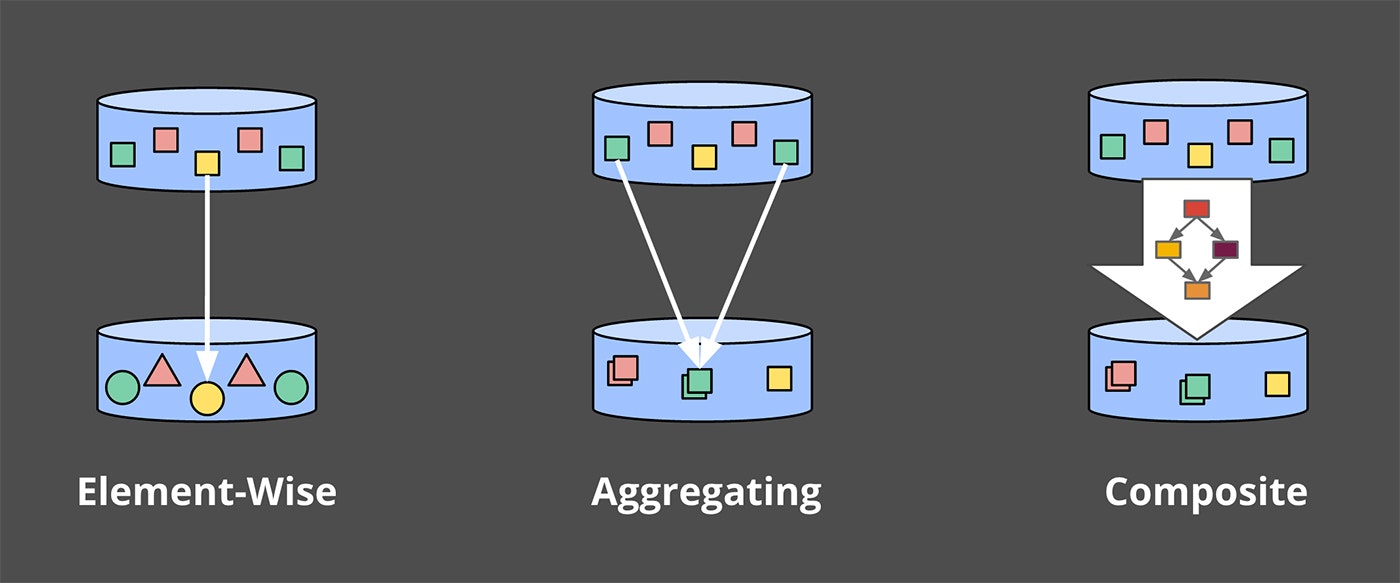
Figure 1 代表的な変換
もし読んでいて混乱するようだったり、リファレンスを確認したい場合はDataflow Java SDK docsを確認してほしい。
この例の目的は、"input"という名称の PCollection<KV<String, Integer>> (文字列のkey、数値のvalueで構成された PCollection であり、例えば文字列はチーム名称、数値はチームに対応した点数となる。)。
実際のデータパイプラインにおいては、"input" は入力ソースログを読み込んだ生レコード PCollection をパースし、変換して生成される。
以後の例ではこういったパースの過程は含まれるものの、入力元については省略する。
このようにして、パイプラインにおいてデータを読み込み、チームとスコアにパースし、チーム毎の合計点数を算出する。
そのコードは下記のように記述される。
PCollection<String> raw = IO.read(...);
PCollection<KV<String, Integer>> input = raw.apply(ParDo.of(new ParseFn());
PCollection<KV<String, Integer>> scores = input.apply(Sum.integersPerKey());
Listing 1. Summation pipeline
今後示す例において、コード片を説明した後に実際のデータに対してそのデータ解析パイプラインを流した場合どうなるか、についてアニメーションも併せて示す。
今回では、あるキーに対して10個のデータが存在する場合の例について示す。
当然ながら、実際の例においてはこの処理は複数のマシン上で並列で実行されるが、アニメーションについてはそういったことはせず、シンプルな構成として示す。
各アニメーションでは入出力データは2つの軸を保持する。
Event Time(X軸)とProcessing Time(Y軸)となる。
そのため、実際のデータパイプラインの処理の進捗は図の下から上にあがっていく形になる(アニメーションにおいては、白い線を参照)。
入力値は丸で囲まれた数値に示されており、グレーから色が変わったタイミングでそのデータがデータパイプライン上で観測・解析されたことを示す。
データパイプラインがある値を観測した段階で、それまで観測した値を基に積算を行い、最終的に結果として出力する。
アニメーションでは灰色のエリア(観測&計算が完了したエリア)の上部に積算値として表示されている。
Listing 1で示したパイプラインでは伝統的なバッチ処理と同様に見えるだろう。
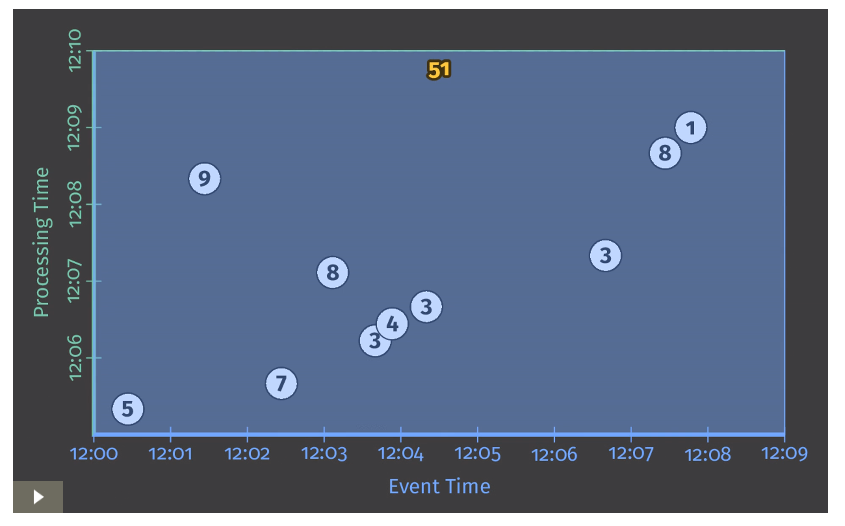
Figure 2 Classic batch processing
以後、左下に矢印のついている画像についてはアニメーションは元記事を参照
今回のケースにおいてはバッチパイプラインであるため、全入力値を受け取ってから状態の算出を行う。
(画面上部まで白い線が達した状態を指す。)
その結果、単一の出力51のみを得る。
この例においては、全時間の合計値の算出のみを行っており、Window演算などは適用されていない。
結果、出力を算出する際の長方形はX軸全体をカバーしている。
しかしながら、無限のデータソースから発生するデータを処理したい場合、伝統的なバッチ処理では不十分となる。
何故なら、発生すると思われる全データが到達することは決してなく、全体の量を用いて処理することは出来ないため。
WindowingについてはStreaming 101で説明したかった概念だが、ここで次の質問が出てくる。
Where in event time are results calculated?
これを基に再度Windowingを振り返ってみよう。
- Where : windowing
既に示されているように、Windowingはデータソースを一時的な領域に区切って処理するものとなる。
共通的なWindow分割方式はFixed Windowing、Sliding Windowing、Session Windowingとなる。
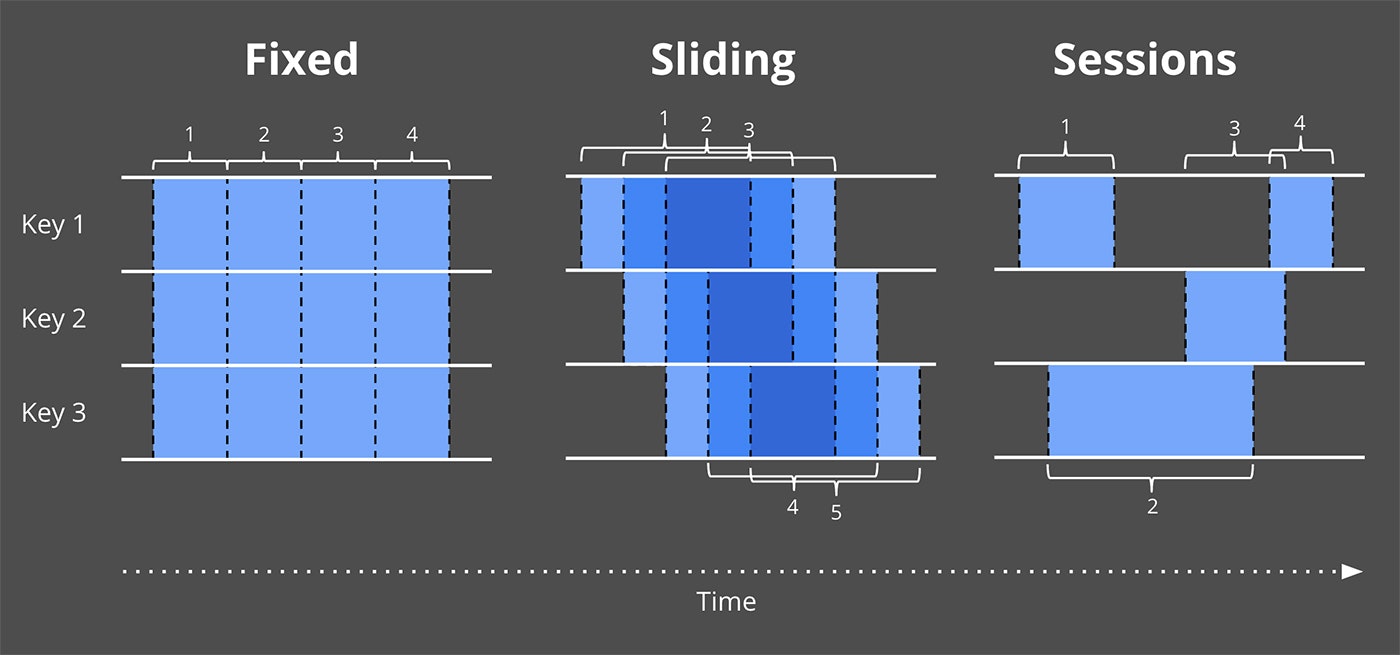
Figure 3 Example windowing strategies
実際にどのようにWindowingが処理されるかを深く理解するために、整数の合計値パイプラインを2分毎のFixed Windowに区切る場合を考えてみよう。
Dataflow SDKにおいては、2分毎のFixed Windowに区切ることは Window.into transformで可能となる。
PCollection<KV<String, Integer>> scores = input
.apply(Window.into(FixedWindows.of(Duration.standardMinutes(2))))
.apply(Sum.integersPerKey());
Listing 2. Windowed summation code.
Dataflowはバッチ、ストリーム両方を統合したモデルを提供しており、バッチはストリームのサブセットであることを思い出そう。
そのため、まずは初めはこのパイプラインをバッチエンジンで実行することを考えた方がより単純になる。
その後、ストリーム処理で実行することを考えれば何が差分か明確に比較ができるだろう。
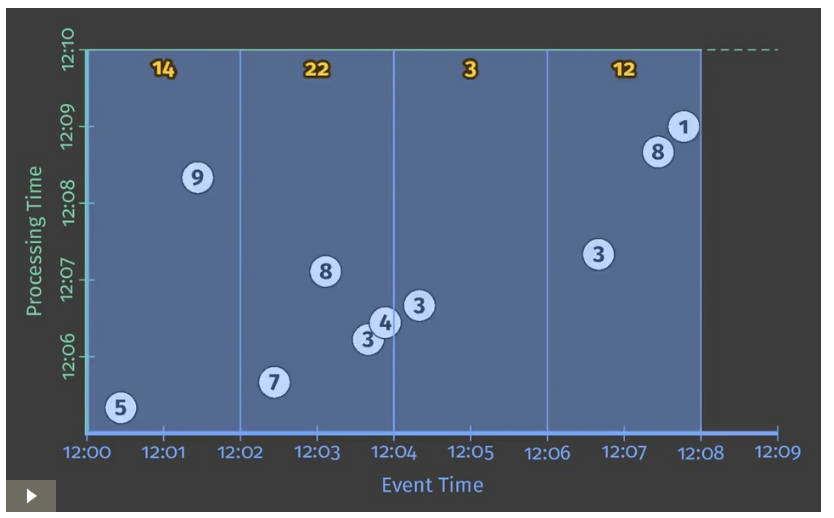
Figure 4 Windowed summation on a batch engine
従来通り、入力値は全データが入力されるまで蓄積され、その後出力が行われる。
この場合、出力値として2分ごとのWindowに区切られた4つの値が得られる。
ここで、Streaming 101で触れられていた2つのコンセプト「Event TimeとProcessing Timeの関係」「Windowing」について思い返そう。
この先に進むにあたり、上記に「Watermarks」「Triggers」「Accumulation」を追加して考えよう。
その考えを基にStreaming 102について説明する。
著者: Tyler Akidau
本投稿: kimutansk

記事自体が長いので、一度これで区切ります。
続きは次の投稿で。