この文章を書く背景と目的
こんな人に読んでほしい
- 人工知能(AI)のビジネス適用を考えている人
- 偉い人から「AIを使って何か新しいことをやれ」と言われている人
- AIを使えば何か凄いことができると思っている人
こんなことを説明します
- AI・機械学習・ディープラーニングの違い
- 機械学習の基本原理としての回帰分析(簡単に言えば算数で習った"比例”)について
- 機械学習は「なにを」「どうやって」学習するのか
- 機械学習を利用した推論・予測には誤差・誤りが含まれること
- 機械学習の精度を上げるためには、たくさんのデータが必要なこと
※「プロジェクト立案編」も投稿予定です。寝て待て。
AI・機械学習・ディープラーニングの違い
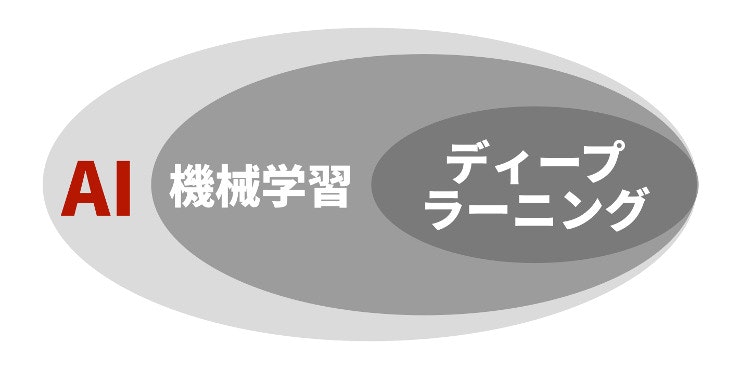
引用元:機械学習とは | AI・人工知能・ディープラーニングとの違い・活用事例・学習方法
端的には ディープラーニングは機械学習と総称される技術のひとつであり、機械学習はAIを実現するためのアプローチのひとつである と言えます。機械学習以外のアプローチとしては、人間が処理条件を記述するルールベースのAI(エキスパートシステム)が挙げられますが、ルールの記述が大変、ルール外の事象に対応できないなど、限定された機能しか実現できていませんでした。
機械学習を使ったアプローチでは、人間がわざわざルールを記述しなくても、機械学習を実行するプログラムにデータを入力するだけで自動でルールを導きだすことが可能です。この「ルールを導き出す」過程ののことを「学習」と呼びます。
機械学習の基本原理としての回帰分析について
例題
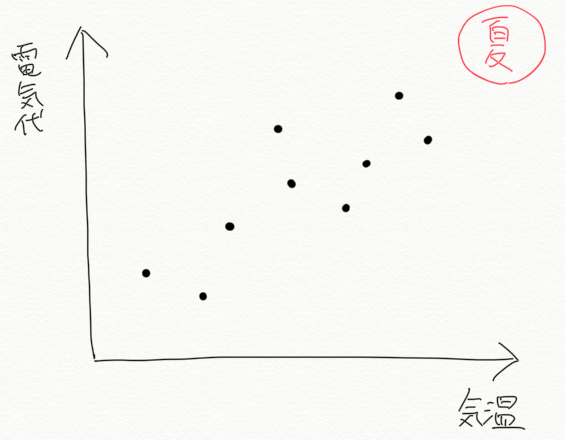
例として、ある家庭の夏の期間の電気代と気温の関係をプロットしてみます。
- データはあくまで例です。
- 1つの点は、ある1日の気温に対して電気代をプロットしているものとして見てください。
機械学習の「学習」ステップ
たいていの家庭では気温が高くなるとクーラーをたくさん使うと考えられますので、下のグラフでは気温が高くなるにつれて電気代も高くなる、という関係が見えます。この関係性を表現しようとする際、こういう(赤い)線を引きたくなると思います(なりますよね?)。
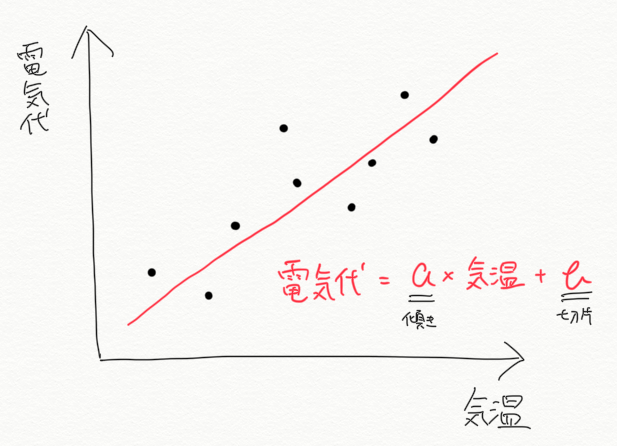
これは、小学校の時に習った「比例の関係」、もしくは中学校の時に習った「一次関数」です。電気代と気温の関係を一次関数で表すとすると、
$$ 電気代=a \times 気温 + b$$
となります。aは傾きbは切片(赤い線がY軸のどこを通るか)ですね。このケースでは、
- 電気代:目的変数 = 最終的に予測・推論したいもの
- 気温:説明変数 = 予測・推論に活用するもの
- a, b:パラメータ(または重み)
であり、これらをまとめてモデルと呼びます。これらのうち、モデルパラメータ(今回のケースではaおよびb)をデータから決定するためのステップを学習と呼びます。さらに、学習済みのモデルを利用して、説明変数から目的変数を計算するステップを予測・推論などと呼びます(次節)。
機械学習の「予測」ステップ
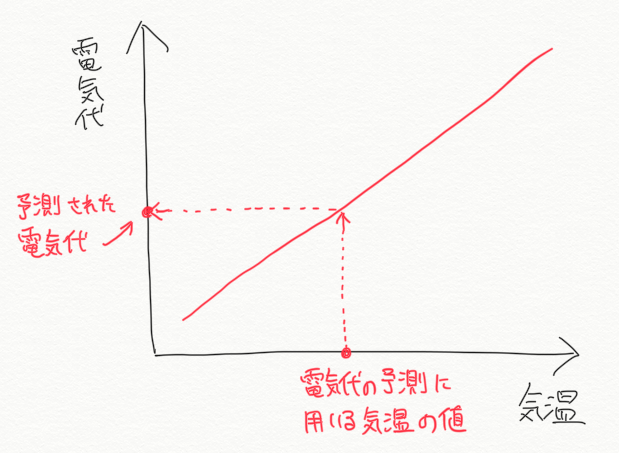
今回の例題の場合、「学習済みモデル」と「明日の予想気温の情報」があれば、「明日の電気代」を予想することができます。このステップを、機械学習の「予測・推論」ステップなどと呼びます(様々な呼び方があります)。
ここで重要なのは機械学習により予測された値・推論された結果は「100%あたるものではない」「誤差が含まれる」こともある、もっと言ってしまえば「間違うこともある」という点です。
機械学習における誤差
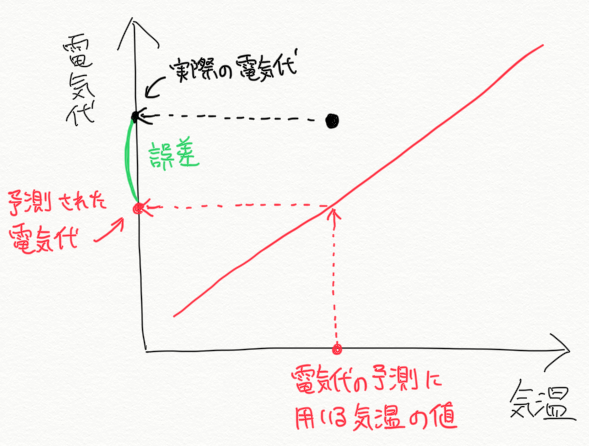
翌日、実際にかかった電気代と前日予測した電気代を比べてみると、100%一致することはまずありえません。このとき、「予測値と実際の値のずれ」を誤差と呼びます。色々なデータ(今回の例題の場合は異なる日付)でこの誤差を評価して、誤差が最小になるようなものが優れた学習済みモデルということになります。
良い学習 = 誤差が最小になるようにモデルパラメータを決定すること
ここで学習のステップに立ち返り、「良い学習」もとい「良いモデルパラメータ」とはどういうものか、という点を考えてみます。良い予測とは、「様々な(将来得られる)データに対して、予測値と実際の値のずれが総じて小さい」ものでした。同じ考えを学習ステップでも採用すると「様々な(過去に得られた)データに対して、モデルで計算された値(赤線)と実際の値のずれが総じて小さい」ものが良い学習であると言えます。
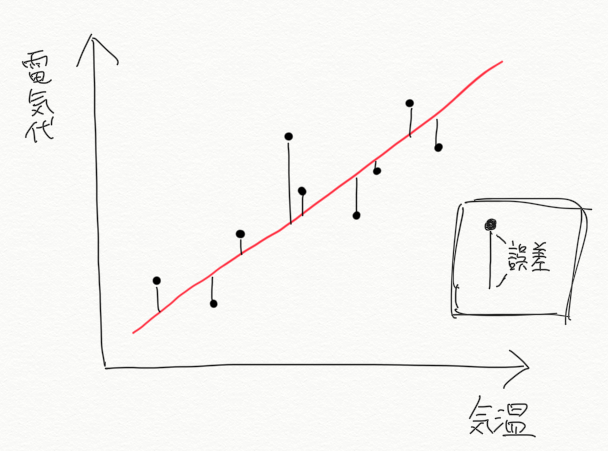
上の図で言うと、「赤線(モデル)と各データ(黒点)の差(距離、誤差)の総和を最も小さくするようにパラメータの値を決定する」というのが学習ステップでの目標になります。このステップを効率的に行うためのアルゴリズムがいくつも提案されており、代表的なものに最小二乗法があります。
機械学習のモデル拡張:より複雑な問題へのアプローチ
説明変数の拡張
上の例題では、電気代を予測するのに説明変数を1個だけ使っていました。しかしもっと多くの情報を使えば、より正確な予測ができそうです。例えば、家族のスケジューラ (Googleカレンダーなど) から得られる(と仮定します)1日の在宅時間の情報を使って、モデルを拡張します。
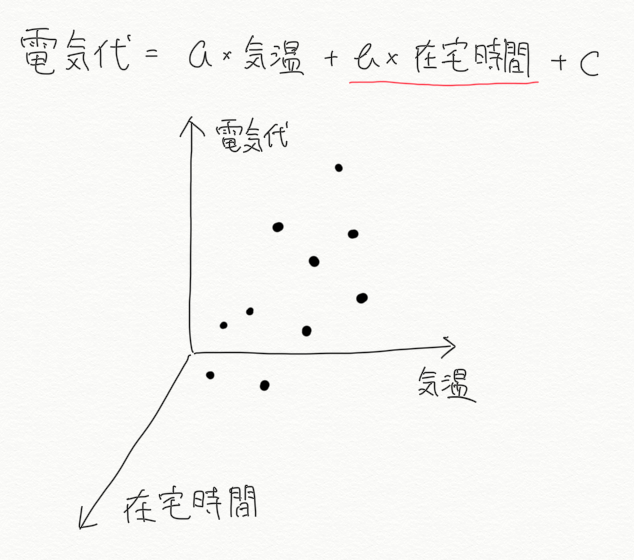
3軸(3D)のグラフになりイメージしにくくなっていますが、「気温が高くなるほど、また在宅時間が長くなるほど電気代も高くなる」という関係性を表しています。モデル自体も、
$$ 電気代=a \times 気温 + b \times 在宅時間 + c$$
と説明変数とパラメータが1つずつ増えています。これが説明変数の拡張です(単純に変数を追加すると言うことが多いです)。原理上は、説明変数とパラメータはいくらでも追加できます。ただし、軸が増えてくると人間がイメージして関係性を導き出すというアプローチは困難になってきます。例えば画像解析の場合、画像を構成するすべての(例えば数千万の)ピクセルがそれぞれ説明変数として学習に用いられます。そう言った場合、機械学習を用いた数学的なアプローチが有効になってきます。
モデルの形を拡張
上の例題では、「夏の期間のみ」の電気代について扱ってきました。しかし冬の期間を考えた場合、気温が下がると、夏と同様にエアコンを使ったり、電気ヒーターを使うことで、やはり電気代は高くなることが考えられます。この傾向に対応するためのアプローチの1つとして、一次関数ではなく2次関数を用いることが考えられます。。
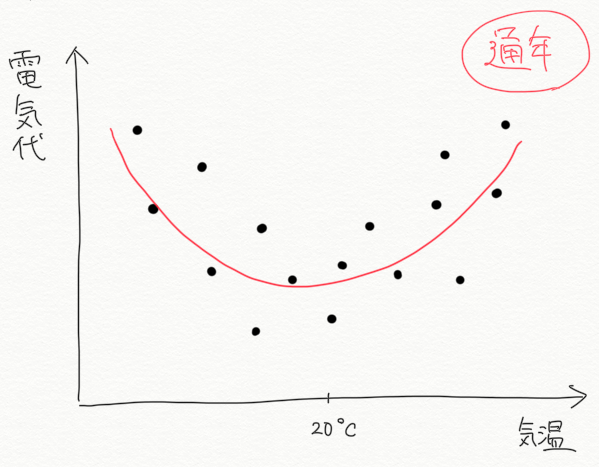
この例では、20℃付近が一番快適で暖房も冷房も使わないため電気代が一番安く、そこから離れるにつれて電気代が高くなる、という傾向が見えます。これを表現するために、
$$ 電気代=a \times 気温^2 + b \times 気温 + c$$
という形のモデルを使っています。
以上で見たように、「どの説明変数を使うか」や「どのようなモデルを使うか」は事前に人間が決めておく必要があります。このステップは、対象とする問題に精通したドメインエキスパートとデータ分析に精通したデータサイエンティストが連携して進めることが重要です。目的変数との関連が薄い説明変数を自動的に捨ててモデルを構築するようなアプローチや、事前にモデルを規定しなくてもよいアプローチ(ディープラーニングなど)も存在しますが、そういったアプローチでは一般的に学習に必要となるデータ数が増大していきますので、自身の問題設定や使えるデータ数に応じて検討する必要があります。
データの数と質の重要性
学習に用いるデータが少ないとどういうことが起きるのかを表したのが下の図です。
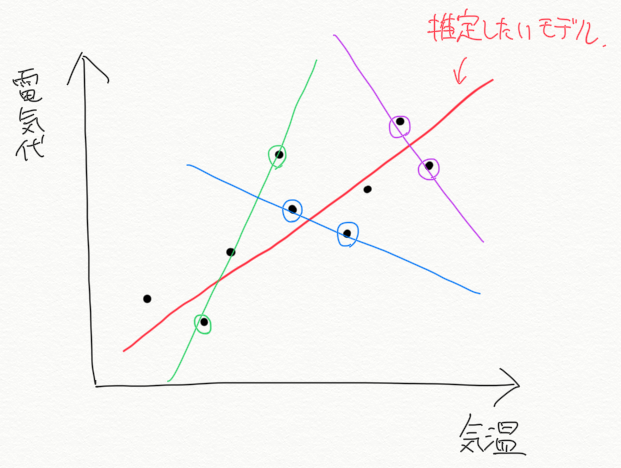
すべてのデータ(黒点)を使って学習した場合は、(データとモデルの誤差を最小化することで)赤線のモデルが得られるのは上で説明した通りです。仮に、学習に使えるデータがもっと少ない場合どうなるのか、上図は極端に、データが2個しかなかった場合に、どうなるのかを示しています。
上図の、緑・青・紫で囲った2つのデータを使って学習した場合に得られる学習済みモデルをそれぞれの色の線で表しています。データが2個しかない場合、データとモデルの誤差を最小化するのは2つのデータ点を両方とも通る直線になります。上図からは、
- データの選び方によって学習によって得られる結果(モデル)が異なること
- 少ないデータで学習を行うと、正しいモデルとは乖離した結果が得られてしまうこと
がわかります。「ではどれだけのデータが必要なのか」ということをよく聞かれますが、「これだけあればよい」という絶対的な基準はありません。唯一言えるのは「データは多ければ多いほどよい」ということだけです。必要なデータ数が増えてしまう要因としては、
- 説明変数が多いこと(画像データなど)
- 学習に用いるモデルが複雑である(パラメータの数が多い)こと
- データの質が悪いこと(正しく測定できていない、ノイズが乗っている、など)
などが挙げられます。ざっくりとしたイメージだけで言うと、
- 説明変数10個の回帰分析の場合、数百から数千個のデータ(説明変数10個と目的変数1個のセット)が必要
- 猫と犬の画像分類の場合、数千から数万のデータ(画像)が必要
のような感じです。特に、データの質などは実際にデータを見てみないとなんとも言えないので、「データ集めてやるから何個必要か言って(そして結果を出せ)」とデータサイエンティストをいじめるのはやめてあげてください。
まとめ:AI (機械学習) を活用する際に押さえるべきポイント
誤差や誤りを許容できますか?
AIは神様ではありません、人間同様(もしくはそれ以上に)間違うことがあります。必要な精度を実現できるかどうか、開発開始前に実験を行いましょう。
分析対象とする事象(データを集めるべき対象・期間など)は整理できていますか?
通年使い回すモデルを、夏のデータだけから学習すると、ひどい目に合います。
変数間の関係性がどんどん変化しませんか?
機械学習は過去に得られたデータから規則性を学習して、将来予測を行います。過去と将来で、説明変数と目的変数の関係性が大きく異なる場合は、予測精度が大きく低下します。移り変わりの早いアパレル業界の売上予測などは難しいかもしれません。
データは十分ありますか?正しく測定できていますか?
データの量と質は、機械学習・AIの質に直結します。
最後に
AIプロジェクトを進めるにあたって、エンジニア・非エンジニア、自社・クライアントを問わず、全員が幸せになれるように、以上のポイントを頭の片隅にとどめ置いていただけると幸いです。
[注意] 平易な説明のため、本稿であえて取り扱っていないポイント
* 観測データに含まれる誤差により、単純な比例や一次関数の問題とは言えない点
* 誤差最小を目指して学習した場合の過剰学習の問題
これらに関しては、説明の平易化のために無視して説明していますのでご容赦ください。その他、ご意見・コメントなどありましたらお願いします!