タイトルのまんまです。いくつかハマるところがあったのと,数日後には忘れてしまうと思ったのでメモすることにしました。
経緯と目的
経緯
諸事情により自分のプライベートリポジトリ内のissueに挙がっているコメントを一覧にする必要が発生したのだけど,手作業とかしたくなかったので調べてやってみた。
目的
- GitHubAPIをRから利用する
- 自分のプライベートリポジトリにアクセス
- 欲しかった情報を取得する
手順
全体の流れ
- GitHubのPersonal access tokenを取得
- APIのためのurlを作成
- 情報取得して内容を確認
GitHubのPersonal access tokenを取得
GitHub APIにアクセスする際に使います。GitHubのAPIにアクセスしようとする際,プライベートリポジトリでは認証(アクセスできるものかどうか)をクリアしないといけません。BASIC認証などを利用する方法もあるのですが,さくっと使うというのであれば,このPersonal access tokenを利用するほうがいいでしょう1。
このPersonal access tokenの説明についてはすでにWebに多くの解説が公開されていますので省略します。[github api token]で検索すればすぐにたくさんヒットするはずです。
取得したPersonal access tokenは,以下のような感じでtknに格納したとします:
tkn <- "SHUUMATUNANISHITEMASUKAHIMADESUKASUKUTTE"
APIのためのurlを作成
ここからがメインです。今回サンプルとしてkazutan/private_ripo_testというプライベートリポジトリを作成してみましたので,これを例として使います。
なお,apiの詳しい仕様については,以下の公式のドキュメントにあたってください:
基本的な部分の準備
けっこう長くなりますんで,ここでパラメータを準備しときます。
# 以降使うパッケージを宣言しとく
library(RCurl)
library(magrittr)
library(jsonlite)
# access token部分の準備
token <- paste("?access_token=", tkn, sep = "")
# apiのアドレス
base_url <- "https://api.github.com"
# scopeをセット
scope <- "repos"
# 組織・ユーザーの指定
orgs <- "kazutan"
# リポジトリ名
repo_name <- "private_ripo_test"
# イシューの番号
issues_no <- "2"
scopeというのは,apiで見に行く対象を指定する,みたいなものかと思います。今回はあくまでリポジトリが対象なので"repo"を指定しました。もしユーザー情報がメイン対象であれば"users"としてください。あとはコメントで付記したとおりです。
プライベートリポジトリの情報を取得
APIに投げるurlを整形します:
get_url_repo <- paste(base_url, scope, orgs, repo_name, sep = "/") %>%
paste(token, sep = "")
整形されたurlは以下のような感じになります:
> get_url_repo
[1] "https://api.github.com/repos/kazutan/private_ripo_test?access_token=SHUUMATUNANISHITEMASUKAHIMADESUKASUKUTTE"
今回はaccess tokenを一番後ろに持ってきて,?でつないでいます。urlにこの?以降がひっついていれば,このトークンを利用します。ではこれを投げます:
res_repo <- getURI(url = get_url_repo,
httpheader = c('User-Agent'="kazutan",
Accept="application/vnd.github.VERSION.full+json")) %>%
fromJSON()
RCurl::rgetURL()で取得し,それをjsonlite::fromJSON()にてリスト型に変換しています。
なお,引数httpheaderで指定している要素には注意が必要です。まず,GitHub APIではUser-Ajentの指定が必須です。詳しくは公式ドキュメントのここを確認してほしいのですが,ユーザーアカウント名でもOKです。なので今回は私のGitHubアカウント名を利用しています。この引数を指定しないと全く相手にされませんので気をつけてください。
また,引数Acceptについては,公式ドキュメントのこちらを参照してください。受け取るメディアタイプ(データ形式など)を指定します。
取得したデータをlistviewer::jsonedit()で一部表示てみた内容がこちらです:
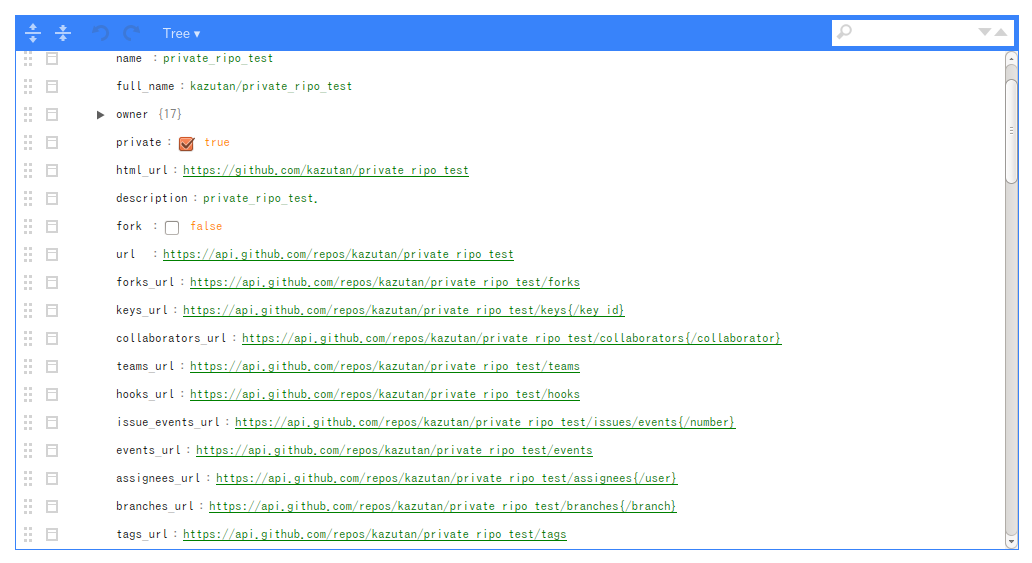
private:にチェックが入っていることから,このリポジトリがプライベートだというのがわかります。また,色々なurlが情報として取得できています。これらのurlに必要な情報をひっつけていけば簡単にアクセスできます(後述)。
issues情報(全体)を取得
考え方はリポジトリ情報の時とほぼ同一で,もうひとつ階層を降りるイメージです。まずurlを整形して準備します:
get_url_repo_issues_all <- paste(base_url, scope, orgs, repo_name, "issues", sep = "/") %>%
paste(token, sep = "")
上述のリポ情報取得用urlと比較してもらえればすぐわかると思うので省略します。これをAPIに送ります:
res_repo_issues_all <- getURI(url = get_url_repo_issues_all,
httpheader = c('User-Agent'="kazutan",
Accept="application/vnd.github.VERSION.full+json")) %>%
fromJSON()
取得した情報をlistviewer::jsonedit()で一部表示してみた内容がこちらです:
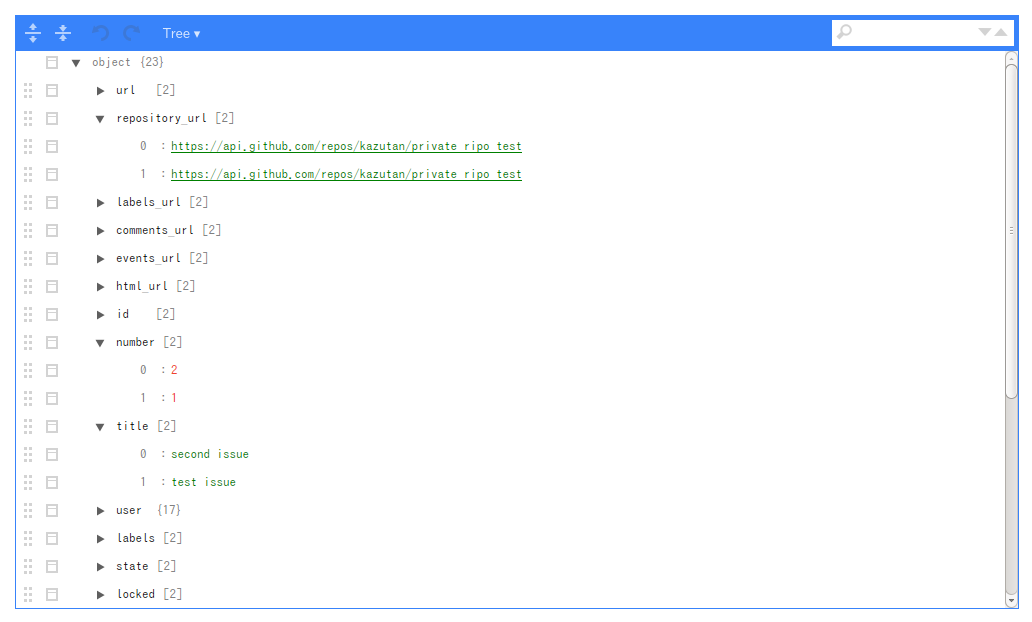
今回はissuesが2つ存在し,1レコード(行)がissue1件となったdata.frameで取得できました。これでそれぞれのissueについての情報を取得できました。
単一のissue情報を取得
issue番号を指定すれば,単一の情報を取得できます:
# イシュー#2の情報をゲットするためのurlを作成
get_url_repo_issues <- paste(base_url, scope, orgs, repo_name, "issues", issues_no, sep = "/") %>%
paste(token, sep = "")
# ゲットしにいく
res_repo_issues <- getURI(url = get_url_repo_issues,
httpheader = c('User-Agent'="kazutan",
Accept="application/vnd.github.VERSION.full+json")) %>%
fromJSON()
これで取得した情報をlistviewer::jsonedit()で一部表示してみた内容がこちら:
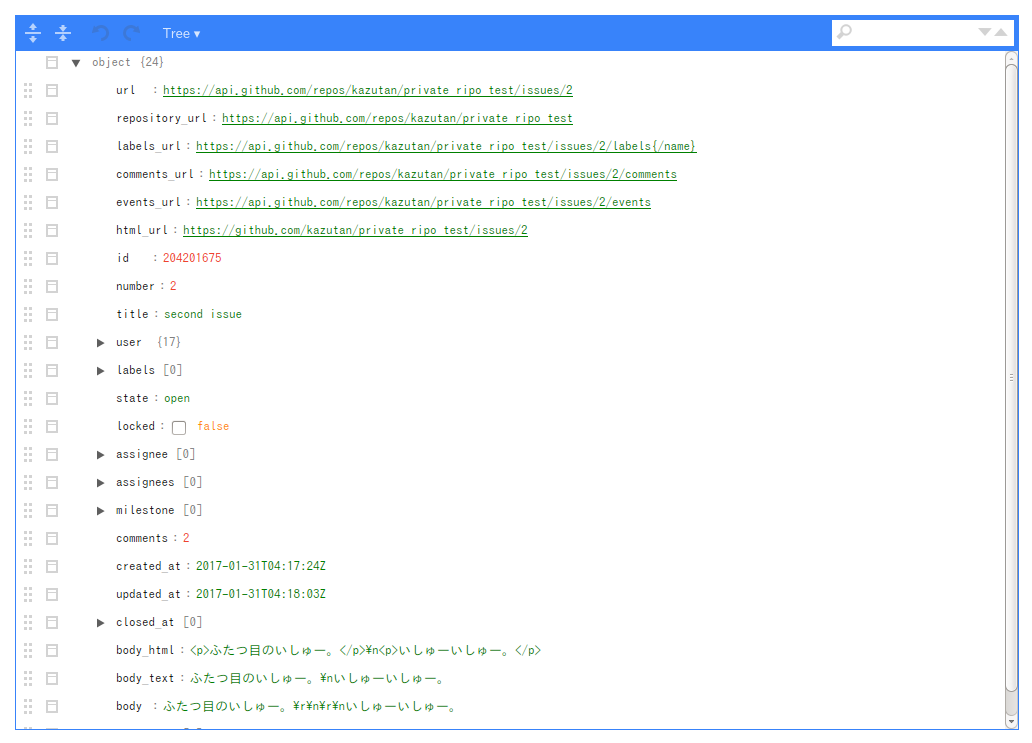
なお,このissue情報(全体取得でも)は,コメントの内容までは持ってきてくれません。issueについたコメントを取得するには,もう一段階降りる必要があります。
issue内についたコメントを取得
今回は直上の単一のissue情報で取得したres_repo_issues内にあるcomment_urlを利用して取得してみます:
# イシュー#2の全てのコメントをゲットするためのurlを作成
get_url_comme_all <- paste(res_repo_issues$comments_url, token, sep = "")
# ゲットしにいく
res_repo_issues_comme_all <- getURI(url = get_url_comme_all,
httpheader = c('User-Agent'="kazutan",
Accept="application/vnd.github.VERSION.full+json")) %>%
fromJSON()
取得した内容の一部はこんな感じです:
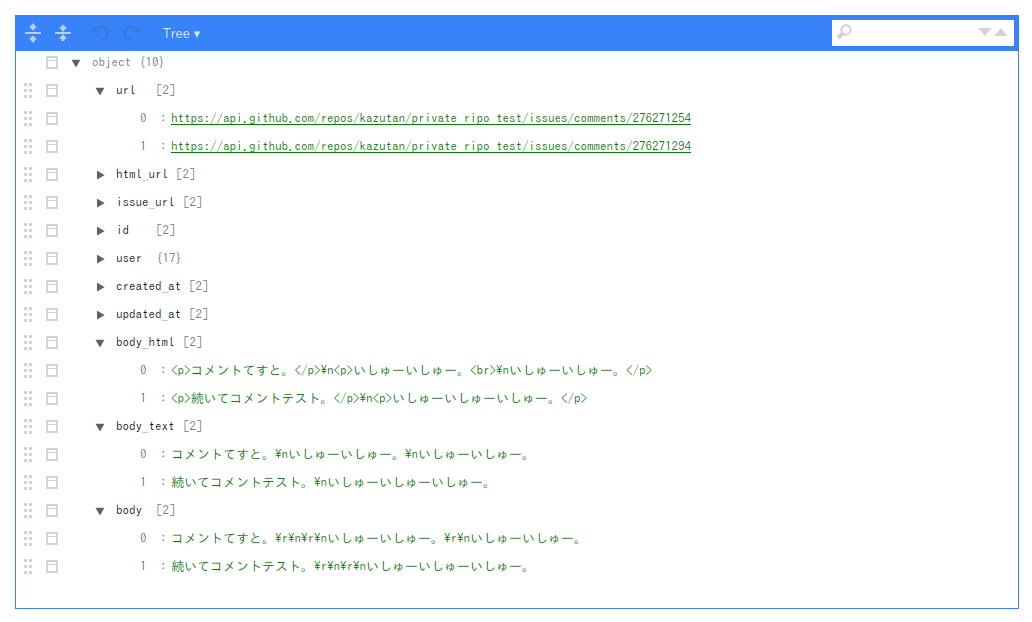
今回の場合,#2のissueには2件コメントをつけていたので,それを取得しています。また,1レコード(行)がコメント1件となっているdata.frame型となって返ってきました。
おわりに
手順とポイントさえ抑えておけば,あとはそれほど難しいものではないです。今回はissueとそのコメントの閲覧に絞りましたが,これをちょっと変更すればcommit情報なども取得できるようになるはずです。ただ詳しいところは公式のドキュメントを参照してください。
また,私はエンジニアでもない素人なので,間違いがありましたらご指摘いただけると助かります。
Enjoy!
実際にやりたかったこと(蛇足)
実のところ,これらで取得したコメントデータを整形してレポートにしたかった。結局ゴリゴリと以下のようなコードで作ってしまった…2
library(lubridate)
# modify data
title <- res_repo_issues$title
body_html_all <- c(res_repo_issues$body_html, res_repo_issues_comme_all$body_html) %>%
paste(paste("#### no.", 1:length(.)), ., sep = "\n\n") %>%
paste(collapse = "\n\n<hr>\n\n")
update_time <- paste("最終更新:", ymd_hms(res_repo_issues$updated_at, tz = "Asia/Tokyo")) %>%
paste("### ", ., "\n\n<hr>\n\n")
# make .md and render to html
doc_md <- paste("#", title, "\n\n")
doc_md <- c(doc_md, update_time)
doc_md <- c(doc_md, body_html_all)
cat(paste0(doc_md, collapse = ""), file = "issue.md")
rmarkdown::render("issue.md")
かっこわるいけど,後学のため晒しときます。