※ 詳細は最後に書いてありますがこの方法は100枚しか画像を収集できないという致命的な欠点があります。
はじめに
画像中にある物体認識の機械学習モデルを作成するに当たってまず必要になるのが大量の訓練画像の収集です。
犬や車といった一般的なものであればImageNetなどのサービスからダウンロードすることができますが、例えばピカチュウやアンパンマンと言ったキャラクターの画像はありません。そこで思いつくのがGoogle検索を使って画像を集める方法です。
今回はそのGoogle Custom Search API を使って機械学習用の画像データを集める方法をご紹介します。
カスタム検索エンジンの作成
まずCSEでカスタム検索エンジンを作成します。
まず検索エンジンの編集の下にあるAddをクリックします

次にフォームに適当に値を入れていきます。ここで注意点として「検索するサイト」は一旦 "*.com" など何か適当な値を入れておきます。いやいやおれは全てのサイトを検索対象にしたいんだー!と思って"*"にすると一生先に進めなくなります。(自分は結構ここでハマりました)後ほど全てが検索対象になるように変更します。後の設定は適宜行って作成ボタンを押します。
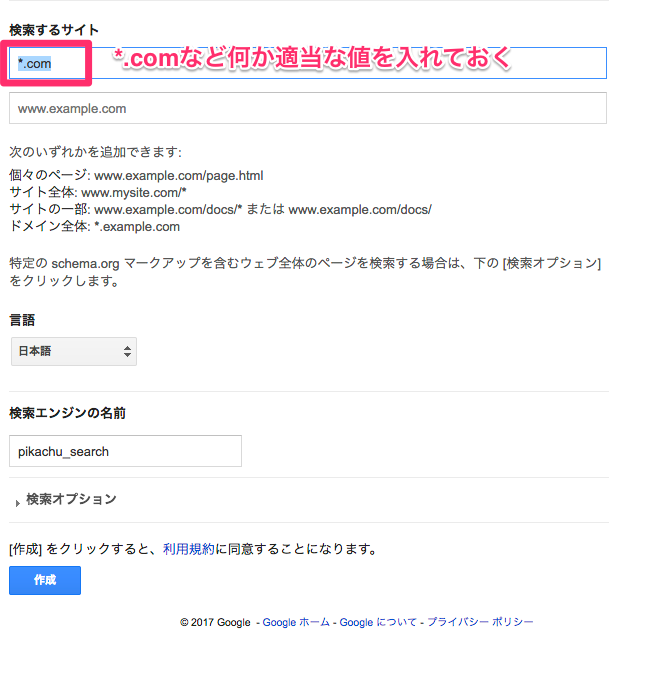
作成ボタンを押すと作成が完了しました。となるのでコントロールパネルを選択します。
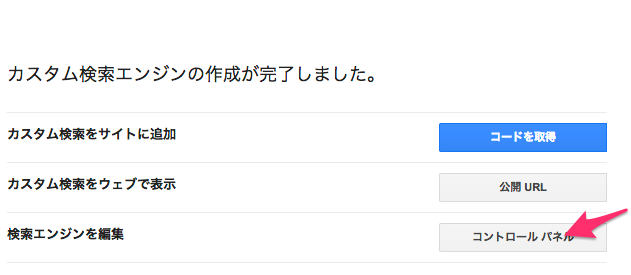
このコントロールパネルで3つ必要な操作を行います
まず画像検索をONにします。

次に検索するサイトから先ほど追加した "*.com"を削除します。
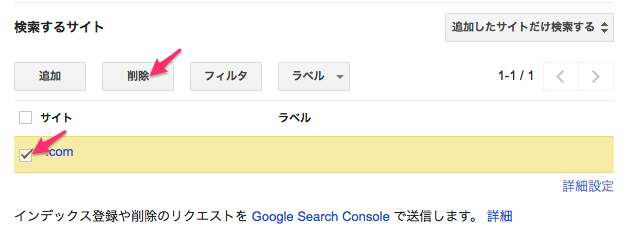
最後に「追加したサイトだけを検索する」となっているのを「追加したサイトを重視してウェブ全体を検索する」に変更します。

お疲れ様でした。これでカスタム検索エンジンの作成が完了しました。
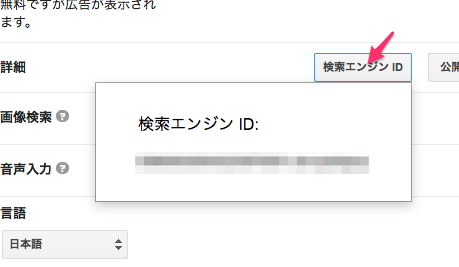
「検索エンジンID」を押すと出てくるIDをメモしておきます。
CustomAPISearchの有効化とAPIキーの取得
続いてCustomSearchAPIを有効化します。
これはとても簡単で
https://console.developers.google.com
にアクセスして(プロジェクトがなければプロジェクトを作成します。)左メニューのライブラリを選択、CustomeSearchAPIを選択します。
遷移先で「有効にする」を押してAPIを有効化します。
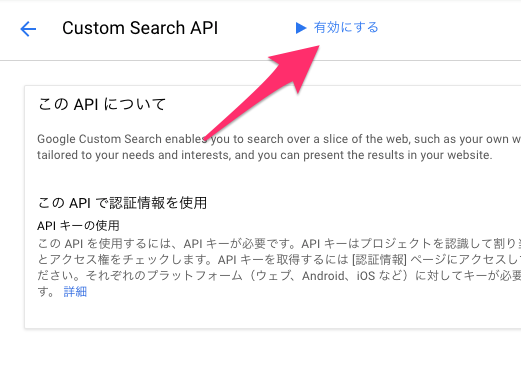
今度は左側の認証情報からAPIキーを取得します。
認証情報を作成のタブからAPIキーを選択します。
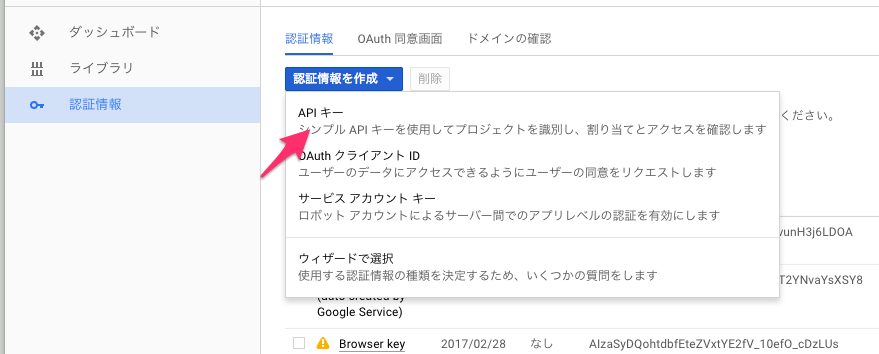
選択するとキーが作成されるのでこれをメモしておきます。
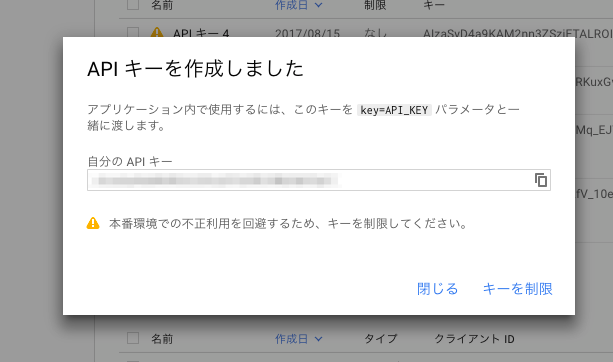
長かったですが、これで準備が整いました!!
画像を収集する
上記で作成したカスタム検索エンジンとCustomeSearchAPI&APIキーを使って画像を収集します。
スクリプトは以下のように非常にシンプルなものです。実行したディレクトリ配下にあるimagesというディレクトリに番号.pngの形で画像を保存します。
検索エンジンIDとAPIキーについては上記でメモしておいたものを、それぞれ入力してください。
(import しているライブラリは適宜pipでインストールしてください。)
import requests
import shutil
API_PATH = "https://www.googleapis.com/customsearch/v1"
PARAMS = {
"cx" : "999999999999999999:abcdefghi", #検索エンジンID
"key": "xxxxxxxxxxxxxxxxxxxxxxxxxxxx", #APIキー
"q" : "ピカチュウ", #検索ワード
"searchType": "image", #検索タイプ
"start" : 1, #開始インデックス
"num" : 10 #1回の検索における取得件数(デフォルトで10件)
}
LOOP = 100
image_idx = 0
for x in range(LOOP):
PARAMS.update({'start': PARAMS["num"] * x + 1})
items_json = requests.get(API_PATH, PARAMS).json()["items"]
for item_json in items_json:
path = "images/" + str(image_idx) + ".png"
r = requests.get(item_json['link'], stream=True)
if r.status_code == 200:
with open(path, 'wb') as f:
r.raw.decode_content = True
shutil.copyfileobj(r.raw, f)
image_idx+=1
実際これを実行してみると以下のような画像が取得できました。



最後に
後になって気づいたのですがこの方法で大量に画像を取得しようとすると
Traceback (most recent call last):
File "get_image.py", line 31, in <module>
items_json = requests.get(API_PATH, PARAMS).json()["items"]
KeyError: 'items'
となって100枚以上画像が取得できないことがわかりました。
どうやらGoogle Custom Search APIでは11ページ目以降の取得を許可していないようです。(記載されていたリンクがあったのですが見失ってしまいました。)