はじめに
東大松尾研のデータサイエンティスト養成講座を受けてみて、アウトプットしないのももったないので、今後データサイエンティストを目指そうという方に向けて自分がためになったと思ったことをつらつらと書いていきます。
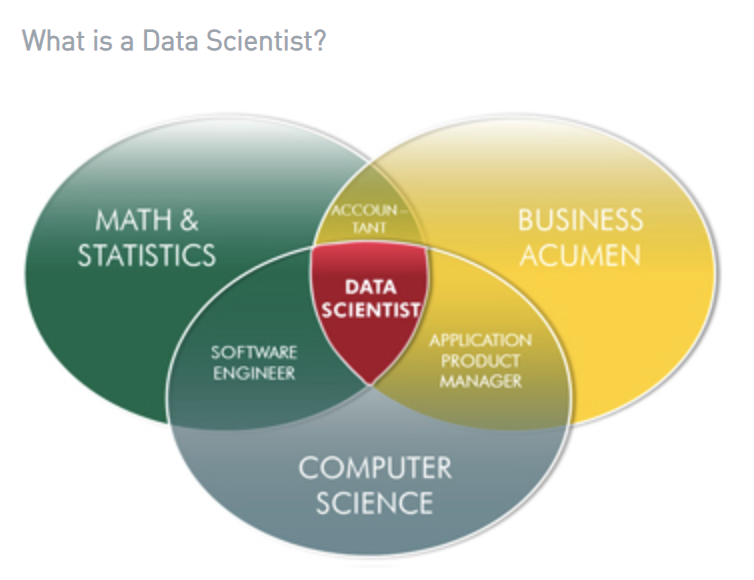
データサイエンティストとは(定義)
- ビジネスの課題に対して、統計や機械学習(数学)とプログラミング(IT)スキルを使って解決する人
次のうちどれかが欠けてもデータサイエンティストとは言えない
- 数学や統計の知識
- 実装できるエンジニアリング能力
- ビジネス課題を解決していくコンサルティング能力
参考URL: https://www.zs.com/services/technology/technology-services/big-data-and-data-scientist-services.aspx
これを聞くとデータサイエンティストになるにはすごい難しいと自分は感じました。
しかし、全ての分野でエキスパートであることに越したことはありませんが、それぞれの強みを持っている人たちでグループを作り、データサイエンスチームを結成することもあります。
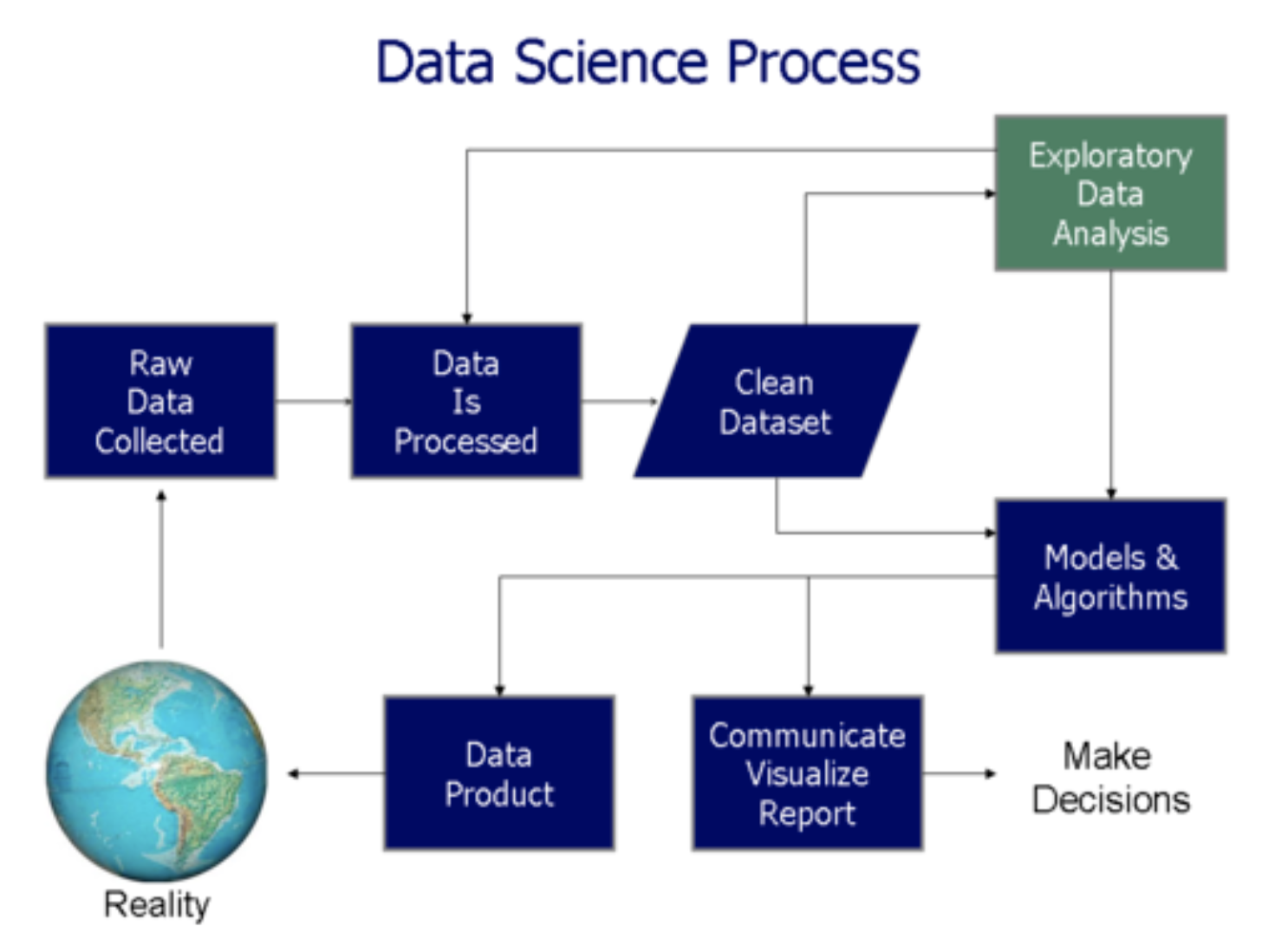
データ分析の流れ
データ分析で重要なこと、それは流れを作ること。
例えばビジネスデータを分析するプロジェクトでの一般的な流れは上から順に以下。
- そのビジネス理解
- データ理解
- データ加工
- 処理
- モデリング
- 検証
- 運用
参考URL: https://www.kdnuggets.com/2016/03/data-science-process.html
この流れのうち、特に重要度が高いのがビジネス理解。
ここをはずすと、データ分析の意味がなくなってしまう!
今まで自分はモデリングばかり学んできたが、真のデータサイエンティストになるにはビジネス的な話を抜きにして語れないのが現実だとわかった。
ここまでのポイント
データ分析の現場で大事になるのは、ビジネス理解やその目的を明確化し、PDCAのサイクルの流れ(データ分析のプロセス)を創ること。
また手を動かして習得することも大事!
なぜプログラミング言語としてPythonを用いるか
他のプログラミング言語と比べてコーディングがしやすく、様々なこと(データの加工、取得、モデリング等)が一貫して簡単にできるから。
また、データ解析や機械学習系のライブラリが揃っていることも特徴。
こうした理由で多くのデータサイエンティストが、データ解析にPythonを利用している。
主に学んでおくべきこと
- Numpy
基本中の基本。行列演算が得意。
- Scipy
Numpyをさらに機能強化するライブラリ。統計や信号計算ができる。
- Pandas
データの前処理に欠かせない。主にデータを加工するためのライブラリ。
- Matplotlib
データをグラフ化するためのライブラリ。
- scikit-learn
機械学習のためのライブラリ。様々な機能がある。
- PyTorch、TensorFlow、Keras
ディープラーニング(深層学習)のためのライブラリ。KerasはTensorFlowをラップして使いやすくしたものという認識。
- Jupyter Lab(Jupyter Notebook)
Pythonの実行環境。試行錯誤していろいろ試しながら実行できる。
また上記のPython関連の技術の他、RDBを操作するためSQLも必須。
以上がだいたい必要になってくる技術だと思います
おわりに
ここまでつらつらと書いてきましたが、この記事がこれからデータサイエンティストを目指そうとしている人の指針になってくれると嬉しいです。
最後まで読んでくださりありがとうございました!