概要
- Light weight convolution, Dynamic convolution を提案
- Light weight Convolution : Depthwise Convolution のパラメータを更に削減したもの
- Dynamic Convolution : Light weight Convolution かつ,畳み込みカーネルを対象とする単語embedding から動的に作成する方法
- Transformer の self-attention 部分を両手法で置き換えた翻訳モデルで 翻訳タスクSoTA達成
- Dynamic Conv : WMT En-De タスクにおいて BLEU 29.7
- 従来のself-attention を用いる Transformer 等を上回った.
-
主張:前後全ての情報を用いる self-attention を用いなくても精度が出せるよ!
- 計算時間も 20% 削減できた ( self-attention は全ての単語に対して attention を計算するので計算コストが高い)
Lihgnt weight convolutions
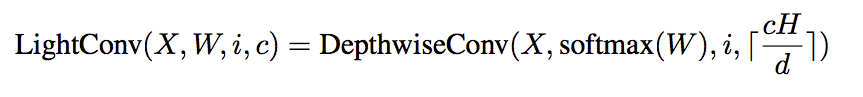
-
Depthwise convolution を使用して計算
- この定式化だと入力データの一部のチャネルしか計算に用いないことになるが合っているか
- $H=20, d=100$ だとすると出力のチャネル 1~5 は 共通の重みで,かつ入力の チャネル1 から計算されることになるので,全く同じ値になる??
-
Depthwise convolution
- 各チャネル毎に畳み込み計算を行う
- kernnel 幅 k のフィルタをチャネル数分用意して,各チャネル毎に対応するフィルタで特徴量計算
- パラメータ数は $k \times d$
- 入力 $X \in R^{n\times d}$ に対してDepth convolution した際の出力 $O \in R^{n\times d}$ の i番目,チャネル c の要素は下の式で表される
- 入力$X$ i番目周辺 [kernel幅/2] 要素のチャネル c を畳み込んだ結果が $O_{ic}$ になる
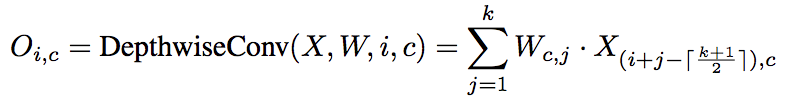
- 入力$X$ i番目周辺 [kernel幅/2] 要素のチャネル c を畳み込んだ結果が $O_{ic}$ になる
Weight sharing
- 連続する $\frac{d}{H}$ チャネル分の特徴量を共通のものとする
- 従来のdepth wise が dチャネルそれぞれに異なる重みを用いているのに比較してパラメータ数が大きく減る
- d = 1024, k = 7 の場合
- regular convolution:$d^2 \times k = 7340032$
- depthwise separate convolution:$d \times k = 7168$
- weight sharing:$H(=16) \times k= 112$
Softmax-normalization
- Softmaxを計算することで,重み$W \in R^{H \times k}$ 時間方向の次元 k に対して正規化する
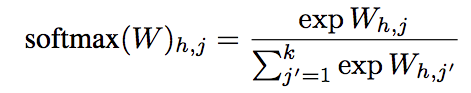
Module
- 計算の順番は
- 線形変換 d -> 2d次元
- GLU 2d -> d 次元
- LightConv d -> d 次元
- 線形変換 d -> d次元
Dynamic Convolutions
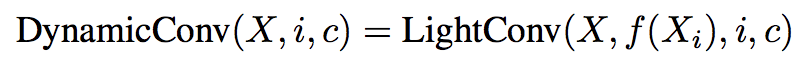
- LightConv と同様の計算方法だが,畳み込みを行う位置(time-step) に応じて,関数 $f :R^d \to R^{H \times k}$(下記式)を用いてカーネルを動的に変更する.
- $W^Q \in R^{H \times k \times d}$ は学習させる
$$ f(X_i) = \sum_{c=1}^d W_{h,j,c}^Q X_{i,c}$$
- 現在の time-step 情報のみを用いてカーネルを決定する
- self-attention の場合は前後全ての情報を用いており, attention の計算に$センテンス長^2$回の演算が必要
- dynamic convolution のカーネル計算回数はセンテンス長に対して線形増加なので長いセンテンスに対しても適用可能
実験設定
モデル詳細
- Transformer に類似した encoder-decoder アーキテクチャを採用
- encoder, decoder それぞれ Nブロック存在
- 各encoder はサブブロック1, 2 とサブブロックを飛ばした Residual connection, 最後の LayerNormalization から構成される
- サブブロック1の候補
- self-attention module
- LightConv module
- DynamicConv module
- サブブロック2(Feed Forward module)
- $ReLU(W^1X + b_1)W^2 + b_2$
- $W^1 \in R^{d \times d_{ff}}$ $W^2 \in R^{d_{ff} \times d}$
- d=1024, $d_ff$=4096
- $ReLU(W^1X + b_1)W^2 + b_2$
- サブブロック1の候補
- 各decoder は encoder と同様のサブブロック1,2とそれらの間に source-target attention サブブロックを持つ
- source-target attention サブブロックでは,Transformer 同様,decoder 側各単語毎に encoder へのattention を計算し,encoder 隠れ状態を足し合わせる
- Transformer Big とパラメータ数が大体同じになるように,ブロック数 N=7 に設定
- Transformer 同様, positional embedding を使用
実験結果
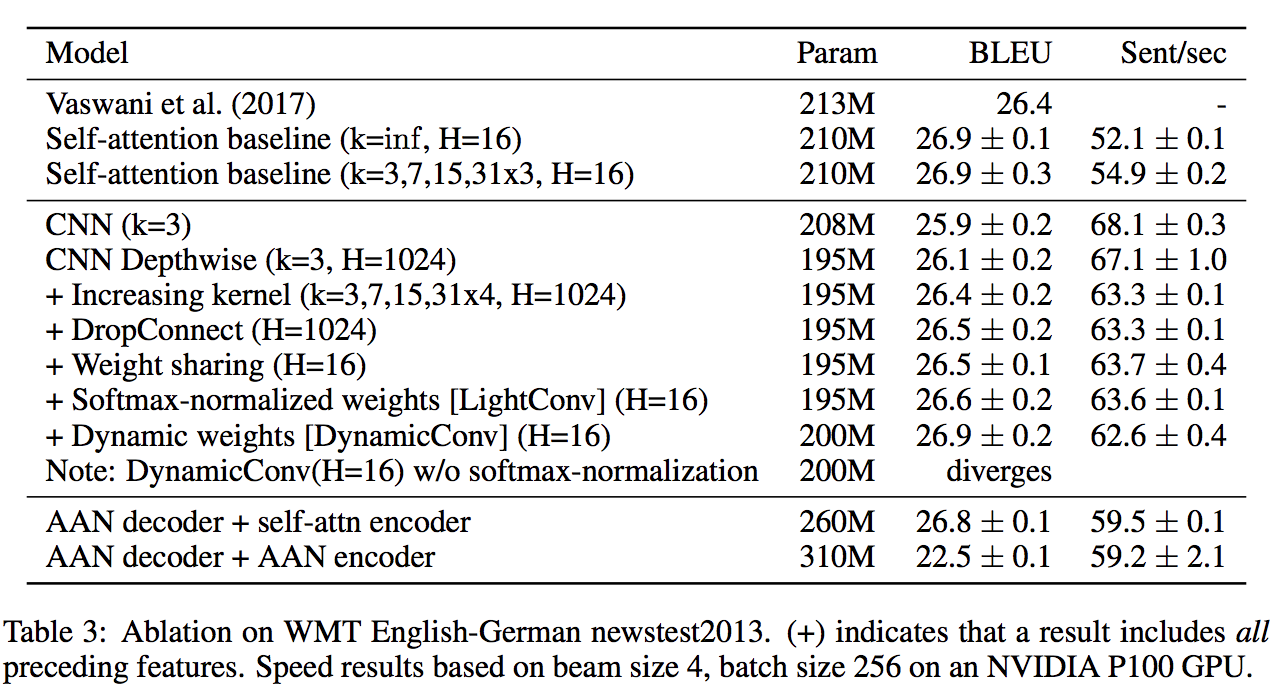
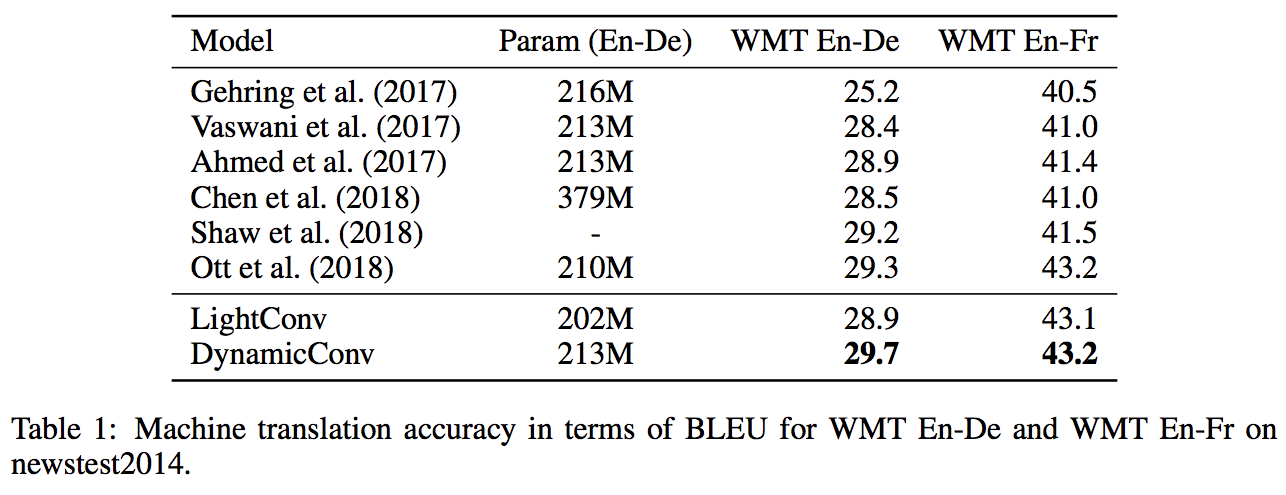
DynamcConv を用いた手法は,self-attention を用いた先行研究を上回るパフォーマンスを示した
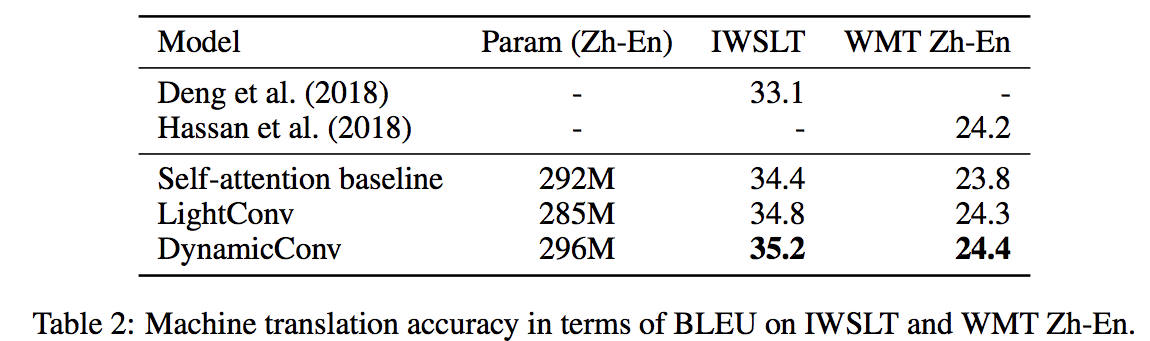
ヨーロッパ圏以外の言語との翻訳においても DynamicConv は SoTA
-
モデルの各要素の効果を調べたところ 下記2つが大きくパフォーマンスに効いていることがわかった
- depthwise conv のカーネルサイズを大きくすること
- DynamicConv
Weight sharing をしてもパラメータ数があまり変わっていないのは何故か???実装の都合??
パフォーマンスが Self-attention baseline と変わっていないのは何故なのか?