Data Science Experience Local(DSXL)のMachine LearningのModelビルダー(モデル作成ウィザード)を使って、故障予知モデルを作ってみます
環境
DSXL 1.1.3.00 (20180122_0943) x86_64
参照
Machine learning models - IBM Data Science Experience
https://datascience.ibm.com/docs/content/local/models.html?audience=local&context=analytics#create-a-model-with-the-model-builder
A.事前準備
A1. 以下からプロジェクトのファイルをzipでダウンロードします。
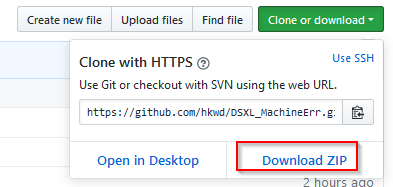
hkwd/DSXL_MachineErr
https://github.com/hkwd/DSXL_MachineErr
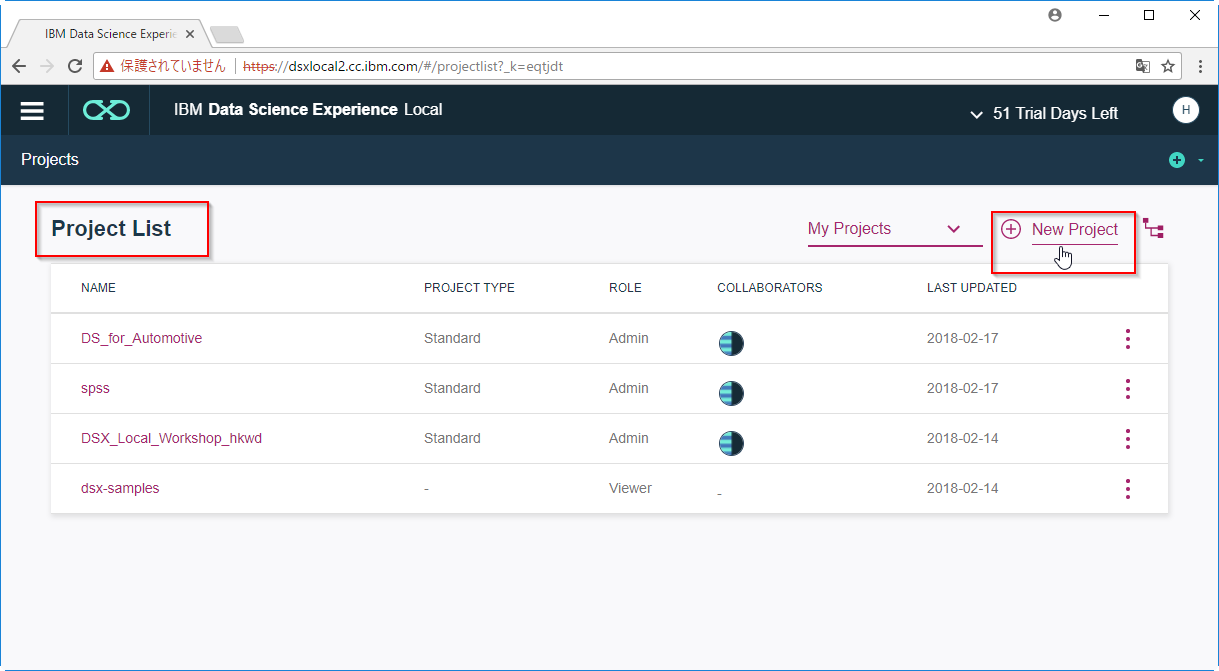
A2. DSXLにログインしプロジェクトにインポートします。
プロジェクトリストを開き、NewProjectでプロジェクトを作ります。
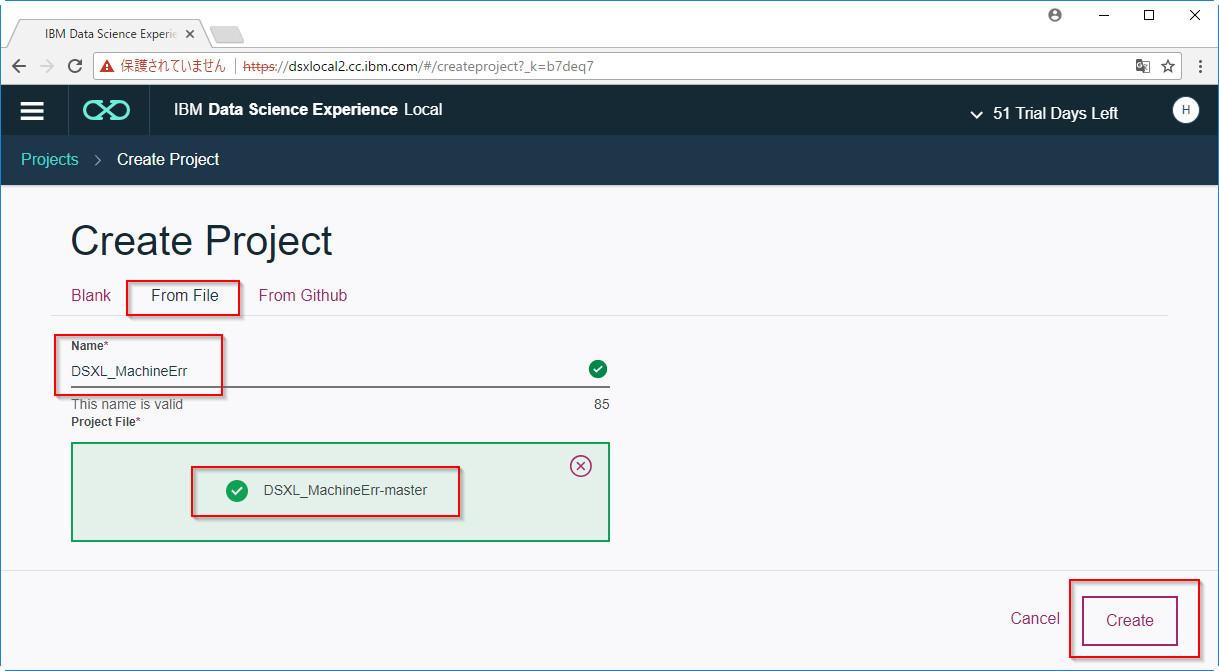
FromFileで先ほどダウンロードしたZIPファイルを指定し、Createします。
B.データの確認
B1. データを確認します
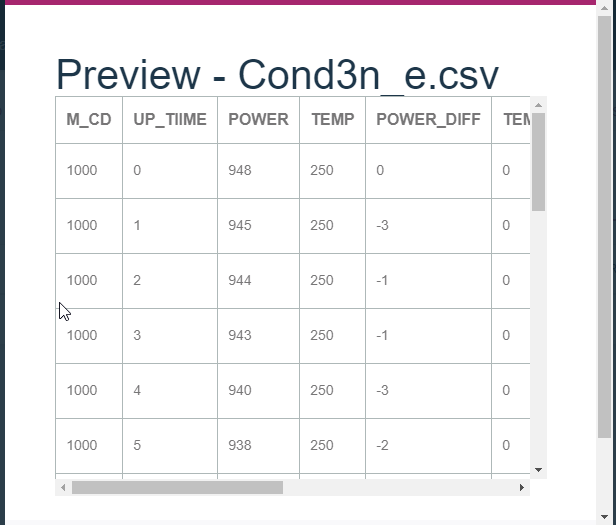
プロジェクトのAssetのDataSetsからCond3n_eというデータをPreviewします
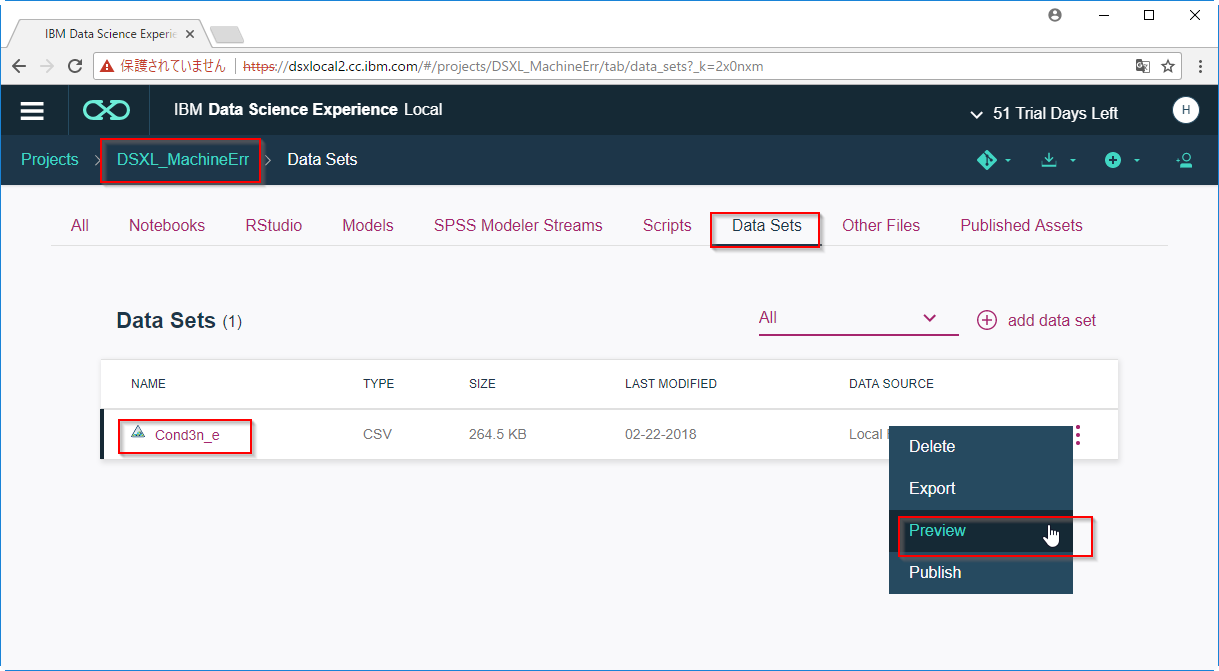
以下のようなデータが入っています。各列の意味は以下です。
M_CD: マシンコード
UP_TIIME: 起動時間
POWER: 電力
TEMP: 温度
POWER_DIFF: 電力差分
TEMP_DIFF: 温度差分
POWER_5MAVG: 電力差分5期移動平均
TEMP_5MAVG: 温度差分5期移動平均
ERR_CD_5FUTURE: 5期先エラーコード

C.モデル作成
DSXLのModelビルダーを使って、電力や温度の変化などから5期先のエラーコードを予測するモデルを作成します。
C1. Modelsのタブを開き、Add ModelでModelビルダーを開始します。
C2. 任意の名前を付けてManual MethodでCreateします
C3. 学習データとしてCond3n_e.csvを選択しNextをクリックします。
C4. 学習データを事前加工します。カテゴリーデータのIndex化などはAutomatic Data Prepatrationの機能で自動で行われます。ここではそのままNextをクリックします。
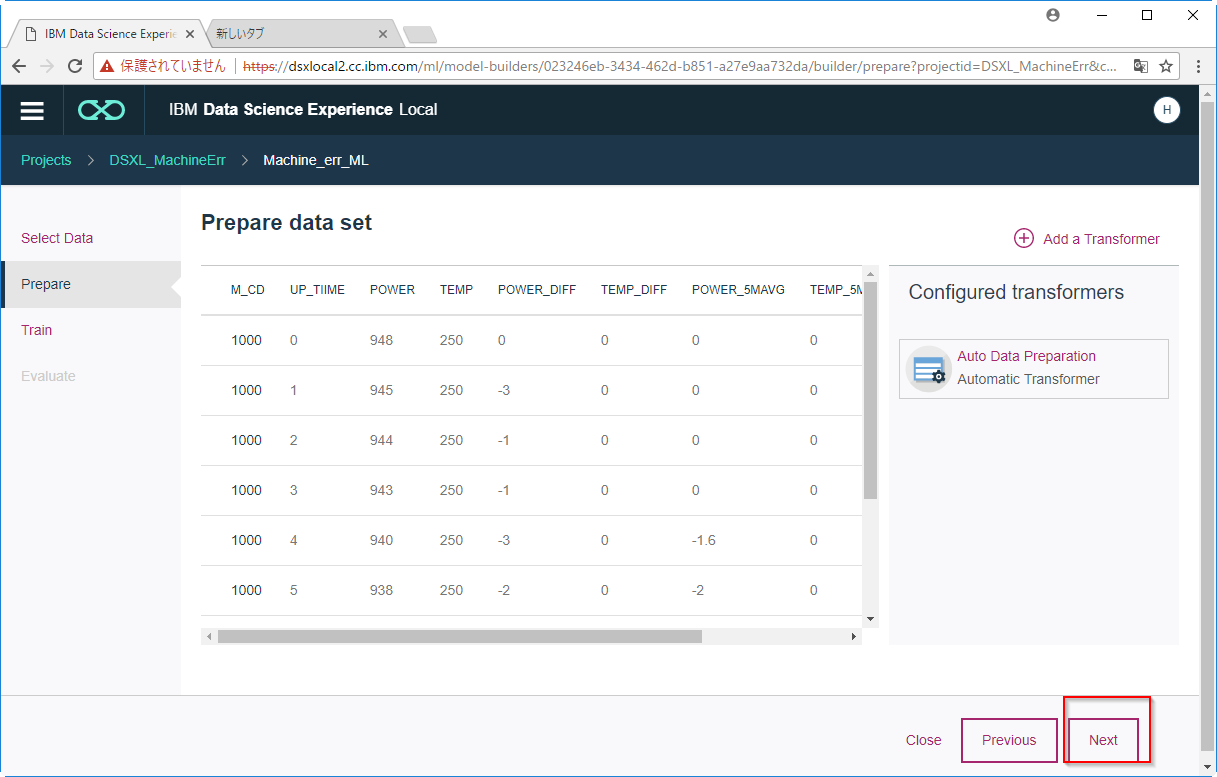
C5. 予測モデルを定義します。
まず、予測対象列である5期先のエラーである「ERR_CD_5FUTURE」を選択します。
次に 「ERR_CD_5FUTURE」は0,101,202,303などの複数の値を持っているため、Multiclass Classificationを選択します。
またValidation Splitは交差検証のためのデータの分割割合を示しています。ここでは60%を学習に使い、20%をテストに使う設定になっています。
そして、Add Estimatorをクリックします。
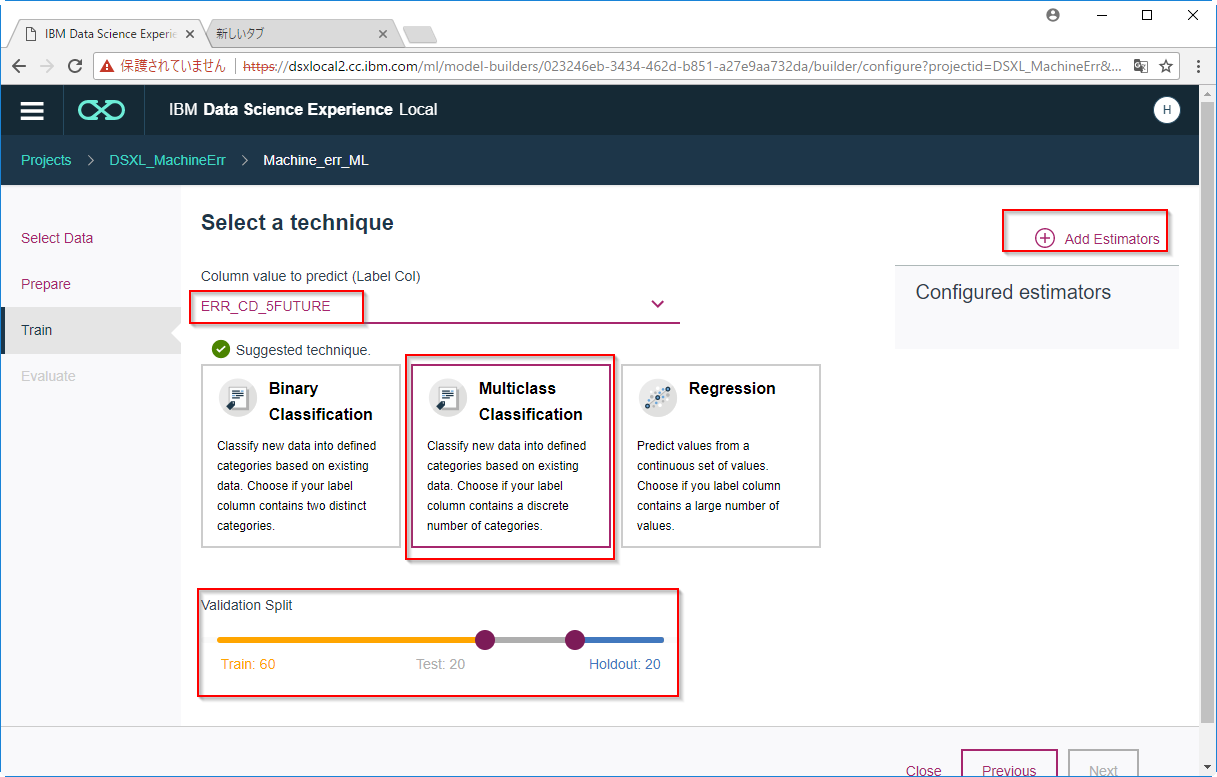
C6. ここでは選択可能なモデル作成アルゴリズムうち、Decision TreeとRandom Forrestを選んでみます(Naive Bayesはマイナス値がある場合には動きません)。
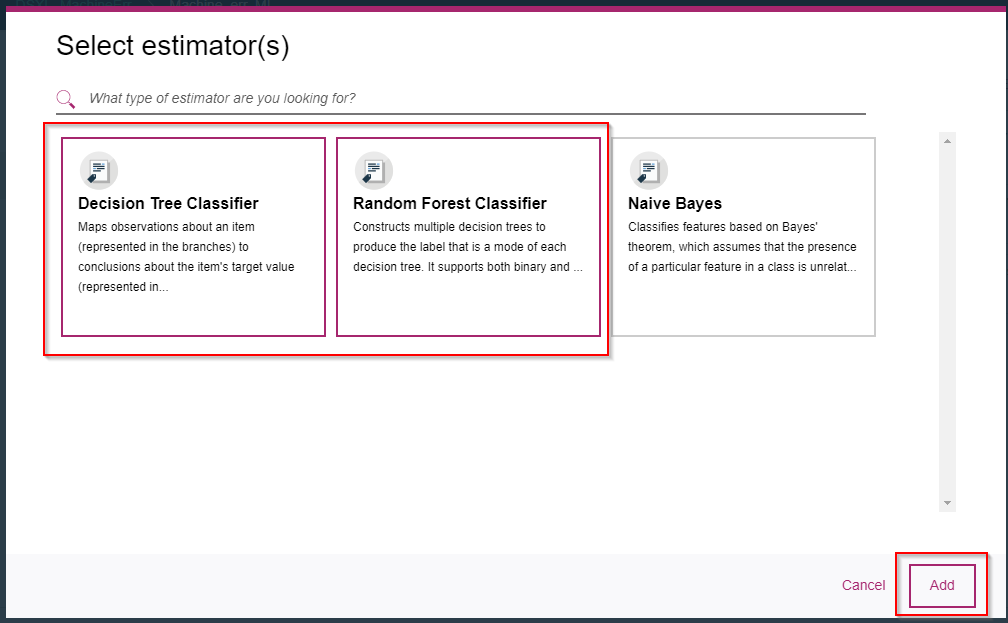
C7. 準備が整ったのでNextをクリックし、モデリングを開始します。
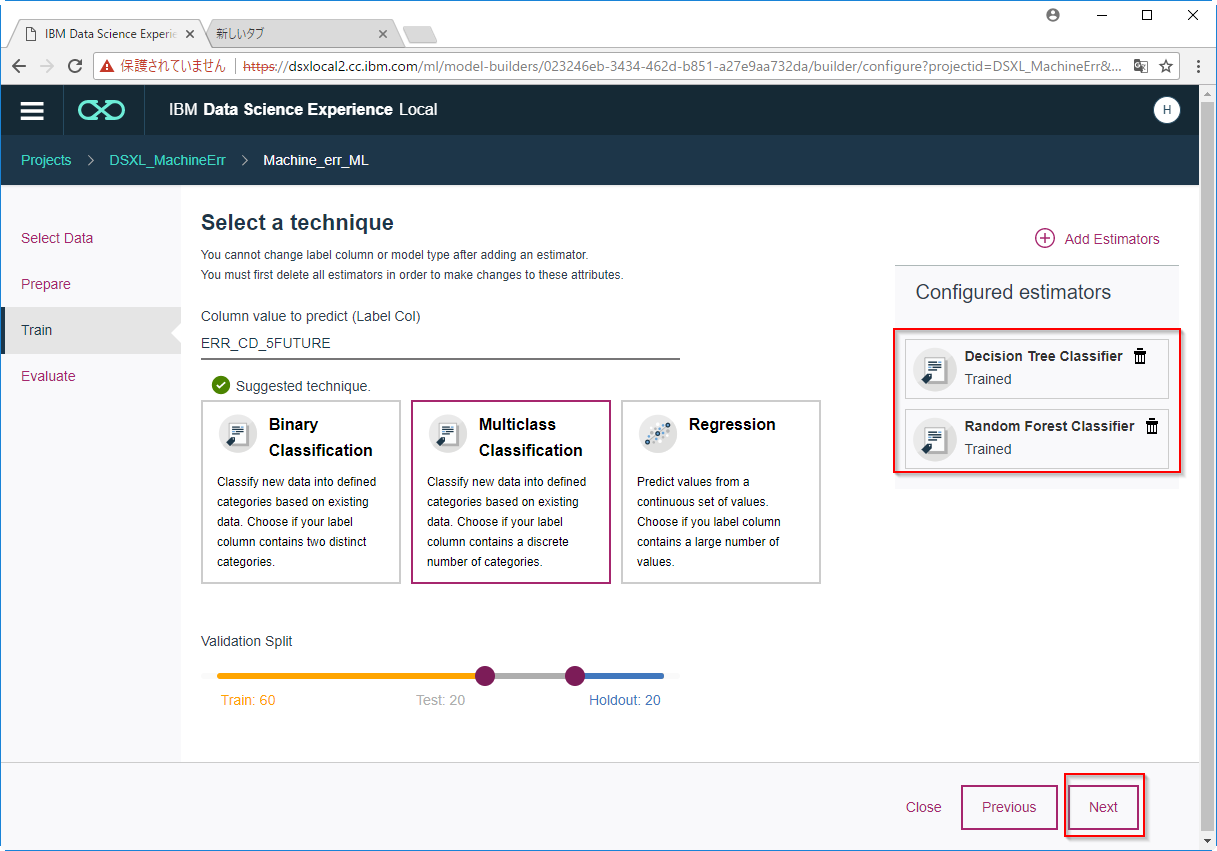
C8. モデルが完成し、テストデータをつかった評価も行われました。Random Forrestのほうが若干良いモデルであったためこれを保存します。
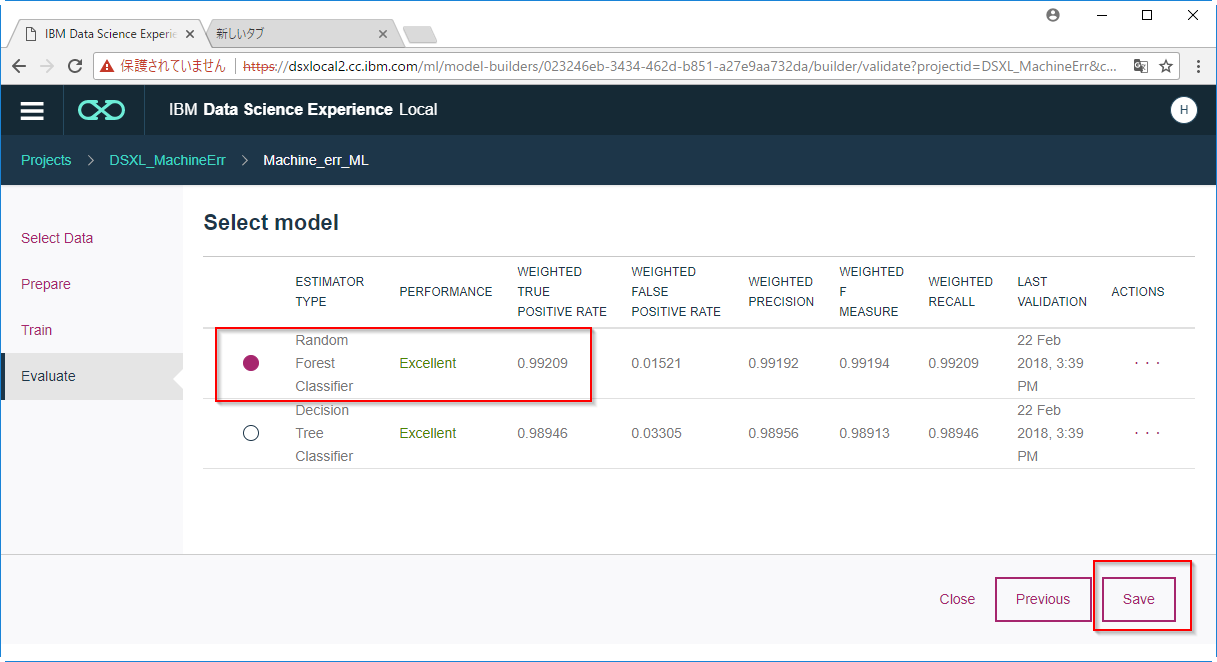
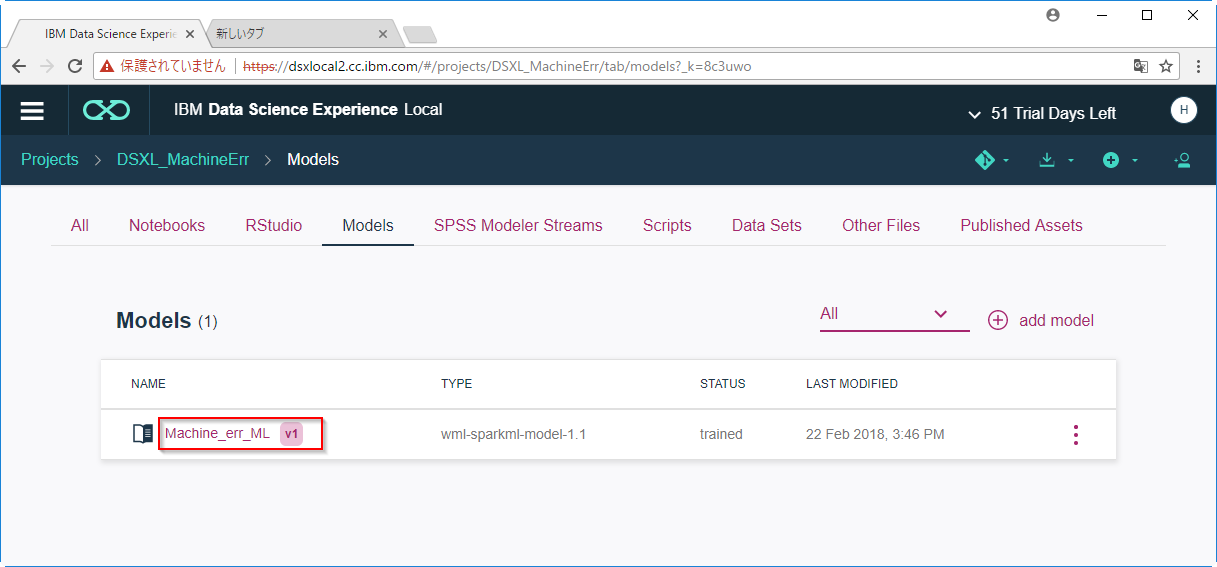
C9. モデルが完成しました。
wml-sparkml-model-1.1とDSXLのMachine Learning APIで作られたAPIであることを示しています。
モデルをクリックします。
D. テスト
D1. テストしてみます。
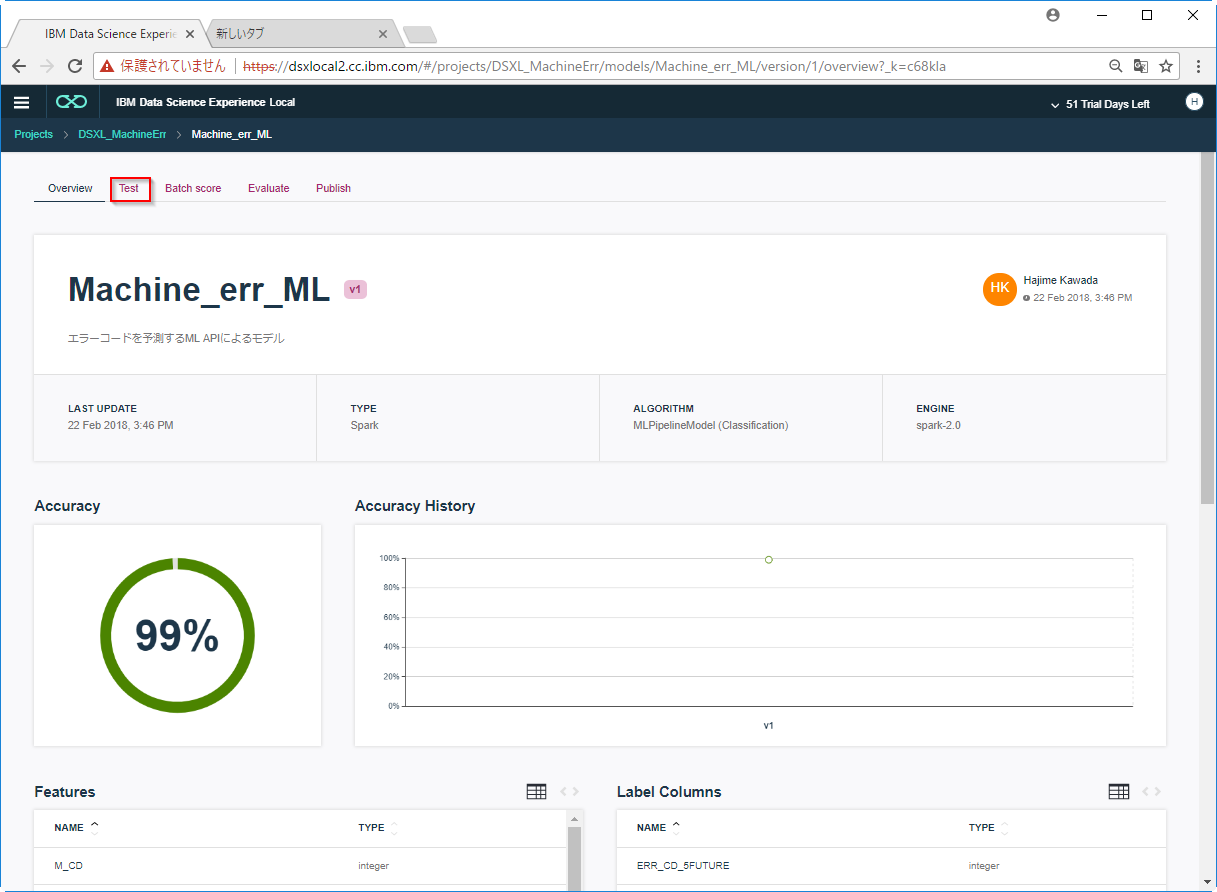
D1. 以下のようなテストデータを入力してSubmitします。
M_CD: 111
UP_TIIME: 66
POWER: 1102
TEMP: 254
POWER_DIFF: 31
TEMP_DIFF: 21
POWER_5MAVG: 10
TEMP_5MAVG: 7
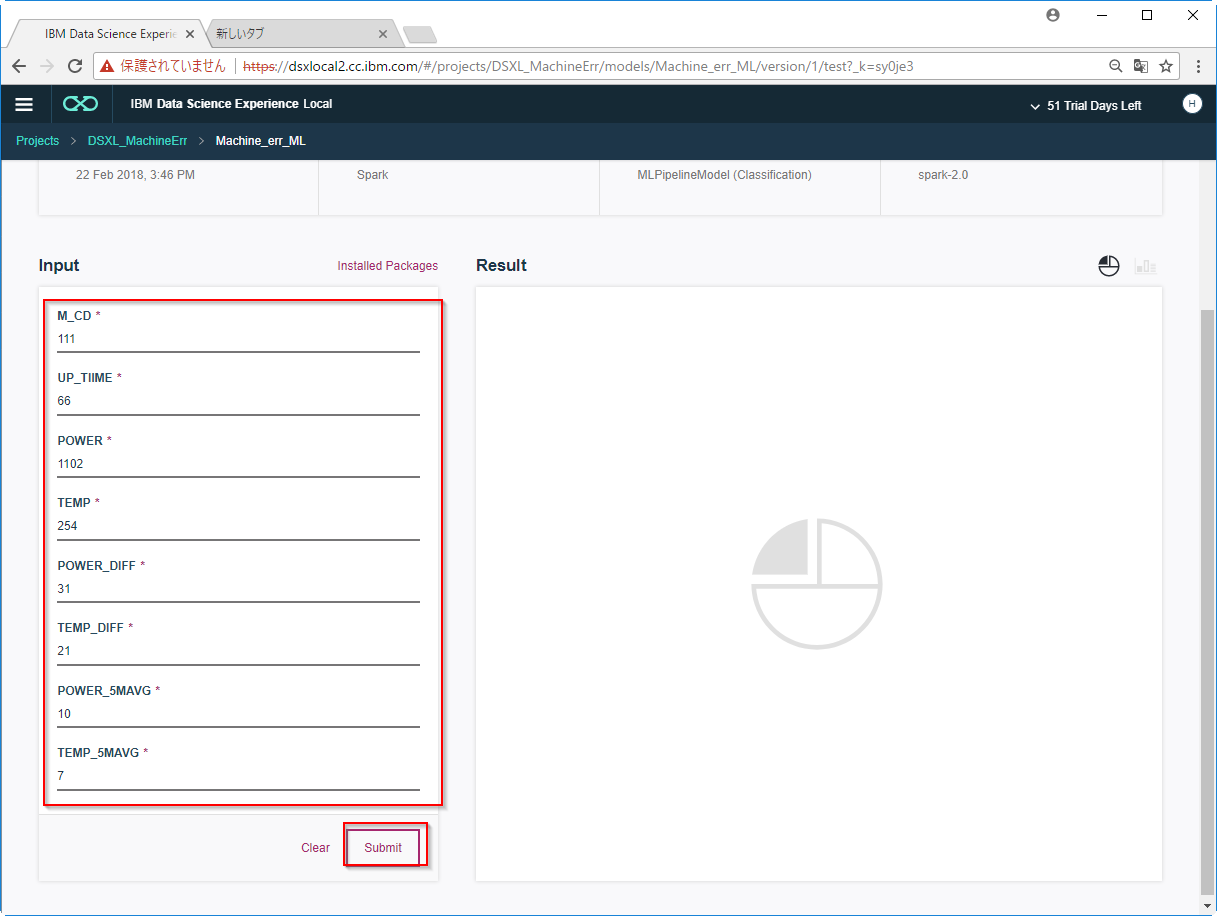
202のエラーが5期先に発生する可能性が80.2%と予測されました。
このように電力や温度の状態で将来のエラー発生を予測するモデルを作成することができました。このモデルに対してREST APIでアクセスすることで故障を予知するアプリケーションを作成することが可能です。