SPSS Modelerには@OFFSETという関数があります。
@OFFSETが使いこなせるようになると特徴量生成の幅が広がります。筆者もいくつかの記事でこの関数を取り上げてきました。ただ、少しややこしく、実例がないと活用方法がわかりにくいところがありますので、改めてマーケティング系とセンサーデータ系でそれぞれの典型的な利用方法を2つの記事に分けて紹介をしたいと思います。
①売上データ編←この記事はこちら
②センサーデータ編
この記事では@OFFSET関数を使って
- 前日売上比
- カテゴリごとの前日売上比
- カテゴリごとの商品売上ランキング
という3つのタイプの加工を行っていきます。
■サンプル
サンプルは以下に置きました。
https://github.com/hkwd/201105OFFSET/archive/master.zip
ストリーム
marketing/OFFSET_Marketing1.str
データ
marketing/sales_by_category_product.csv
marketing/sales_by_date.csv
marketing/sales_by_date_category.csv
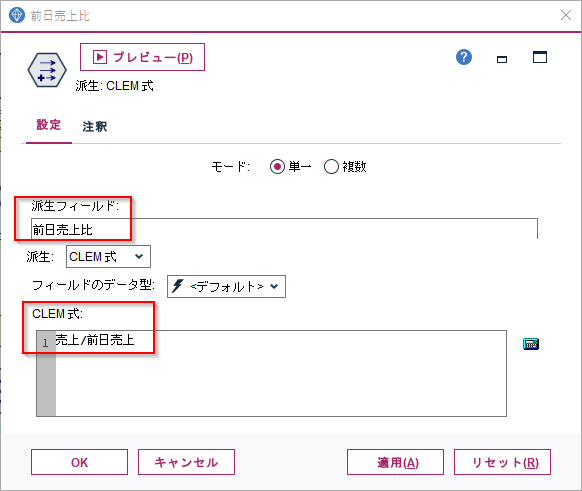
1.前日売上比の計算
@OFFSET関数は前後のレコードを参照するという関数です。
日毎の売上を日付でソートすれば、一行前のデータは一日前の売上ということになります。
以下のデータをつかって計算していきます。
いつ(DATE)いくら(売上)購入したかが記録されています。
まずソートノードをつかって、日付順に売上データを並べ替えます。
- ソート項目にDATEを設定します
- 順序は昇順のままとします
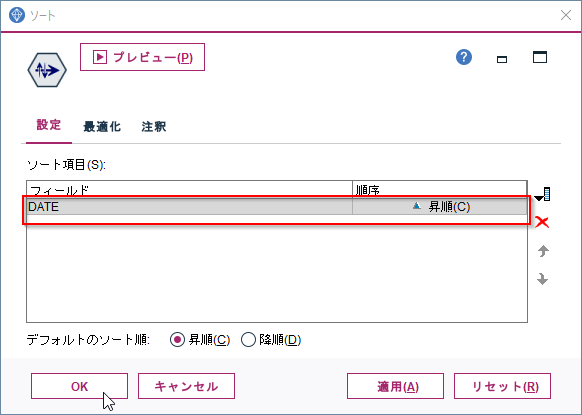
次にフィールド作成ノードをつかって、前日売上を参照します。
- CLEM式に@OFFSET(売上,1)を入力します。これは売上データの1行前を参照するという意味です。先ほど日付順でデータを並べ替えましたので、1行前とは前日を意味します。ですのでこれが前日売上になります。
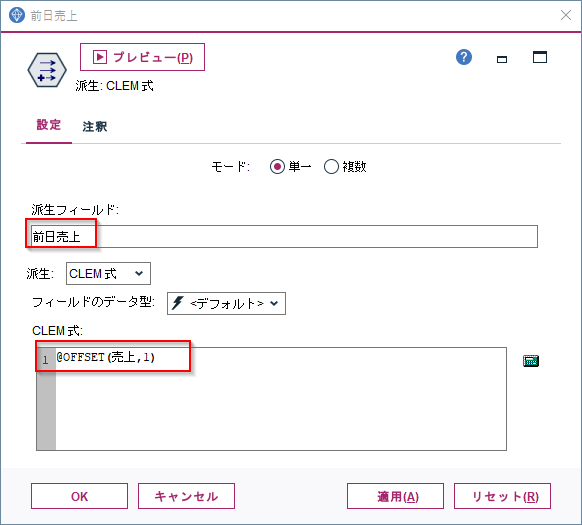
プレビューをしてみると以下のように「前日売上」という新しい列が作られ、一日前の売上が入っていることがわかります。
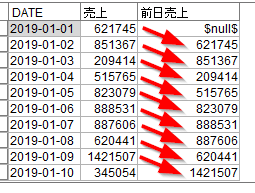
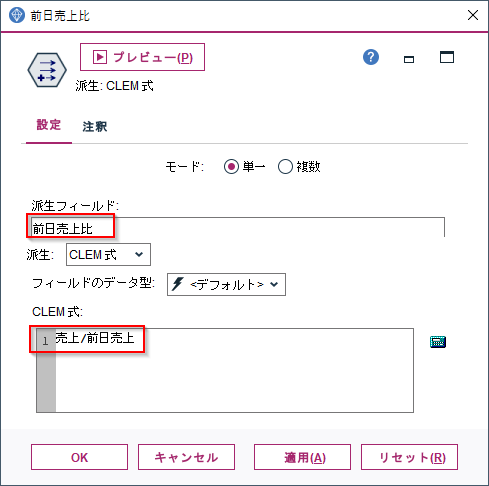
後はフィールド作成ノードで前日売上比を計算します。
- CLEM式に売上/前日売上を入力します
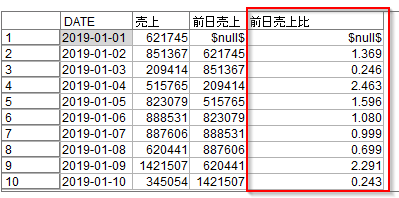
テーブルノードを接続して、結果をみると毎日の前日売上比が計算されています。
2.カテゴリごとの前日売上比の計算
次に少し応用編です。
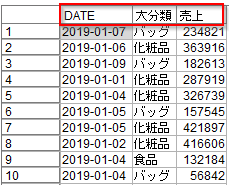
以下のデータをつかって計算していきます。
いつ(DATE)何(商品大分類)をいくら(売上)購入したかが記録されています。先ほどのデータと違うのはバッグや化粧品、食品などの商品カテゴリの列があることです。
商品カテゴリごとに前日からの売上比を確認したいと思います。カテゴリごとに調べることで、例えば水曜日は食品特売日なので火曜日からの売上比がいつも1.5倍くらい大きいとか、バッグや化粧品は週末に売れやすいというようなことが見えてくるかもしれません。
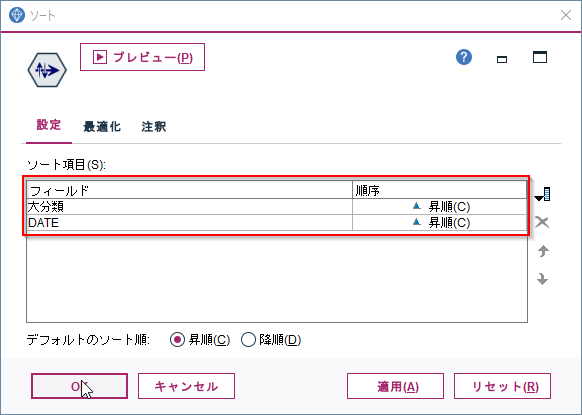
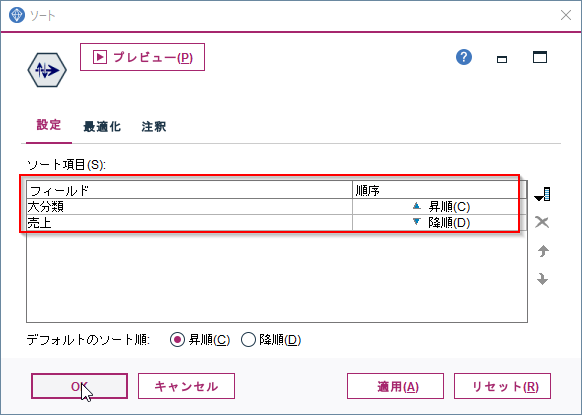
まずソートノードをつかって、大分類と日付順に売上データを並べ替えます。
- ソート項目に大分類、DATEを設定します
- 順序は昇順のままとします
結果をテーブルノードで見てみると以下のように商品カテゴリごとに日付順で並べられています。
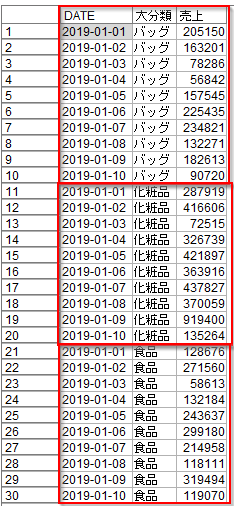
次にフィールド作成ノードをつかって、前日売上を参照します。
- 派生モードを「CLEM式」ではなく、「条件付き」に変更します
- Ifに「大分類 = @OFFSET(大分類,1)」を入力します。これは前の行と大分類のカテゴリが同じという条件です。
- Thenに@OFFSET(売上,1)を入力します。これは売上データの1行前を参照するという意味です。先ほど日付順でデータを並べ替えましたので、1行前とは前日を意味します。ですのでこれが前日売上になります。
- ElseにはNULLを意味するundefを入力します。つまり大分類が変わった場合にはカテゴリも違いますし、前日の売上のデータでもないので@OFFSET(売上,1)は行わずにNULLを入れるということです。これによって大分類ごとにグルーピングして集計しています。
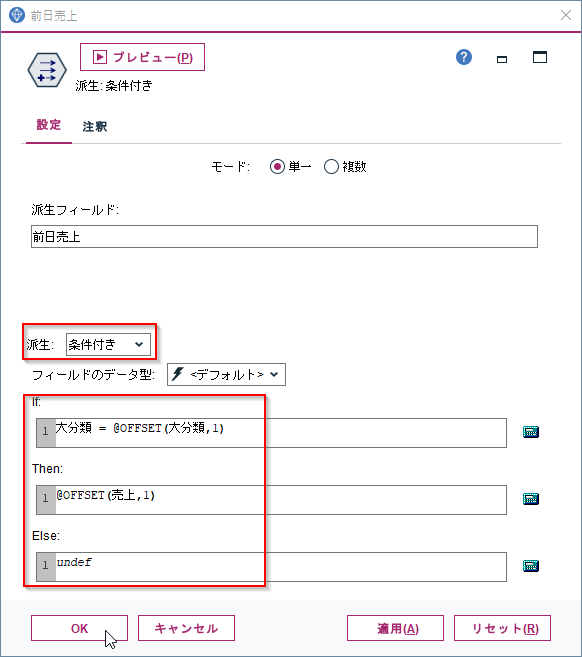
プレビューをしてみると以下のように「前日売上」という新しい列が作られ、カテゴリごとの一日前の売上が入っていることがわかります。
Ifに「大分類 = @OFFSET(大分類,1)」を入れたことで、カテゴリが切り替わる11行目や21行目では前行を参照せずにNULLが入りました。
先ほどの「1.前日売上比の計算」のようにIFの条件をいれないで、CLEM式でただ前の行を参照してしまうと、例えば1月1日の化粧品の前日売上に1月10日のバッグの売上がはいってしまい、間違ったデータになってしまいますので注意が必要です。データをグルーピングしながら処理する場合には「大分類 = @OFFSET(大分類,1)」のようなIF条件が必要になります。
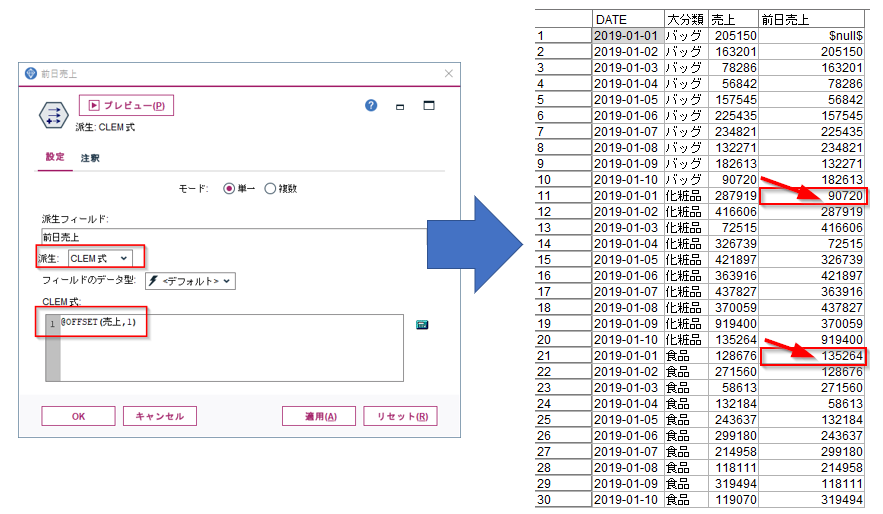
後は、前日売上比は先ほどの「1.前日売上比の計算」と全く同じように計算できます。
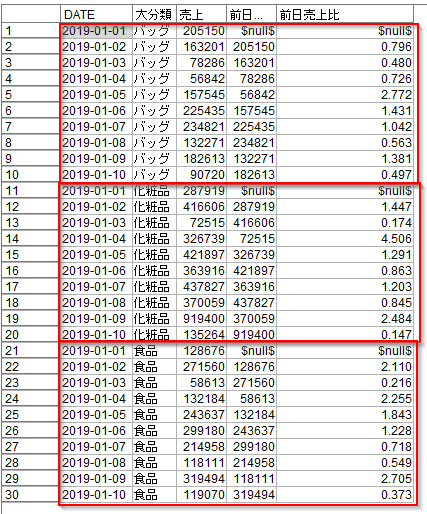
結果は以下のようになります。
各商品カテゴリごとに前日売上比が算出されました。1月1日の前日売上と前日売上比は12月31日のデータがないのでNULLになります。
化粧品は、1月3日には前日比0.17倍、翌日の1月4日には前日比4.5倍の売上になっていて変動が激しいカテゴリであるかもしれないことなどが見えてきます。
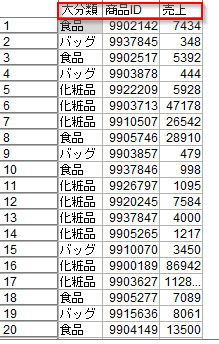
3.カテゴリごとの商品売上ランキング
次は累積和の考え方でカテゴリごとの商品売上ランキングを作ってみます。
以下のデータをつかって計算していきます。
何(商品大分類、商品ID)をいくら(売上)購入したかが記録されています。
まず、ソートノードで大分類を昇順、売上を降順で並べ替えます。
これで、大分類ごとに売上が高い順にデータが並び変えられました。
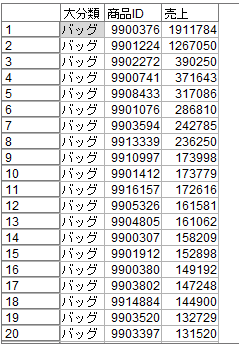
次にフィールド作成ノードをつかって、各商品が何位かというランキングを振っていきます。
- 派生モードを「CLEM式」ではなく、「カウント型」に変更します
- 増分条件に「大分類 = @OFFSET(大分類,1)」を入力します。これは前の行と大分類のカテゴリが同じという条件です。
- 増分に「1」を入力します。つまり大分類が同じ間は1ずつ足していくという意味です。
- リセット条件には「大分類 /= @OFFSET(大分類,1)」を入力します。つまり大分類が変わった場合には1にリセットしなおすという意味です。
結果は以下のように商品大分類が変わると1から順に数えることになり、ランキングができました。
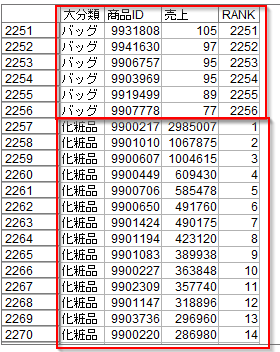
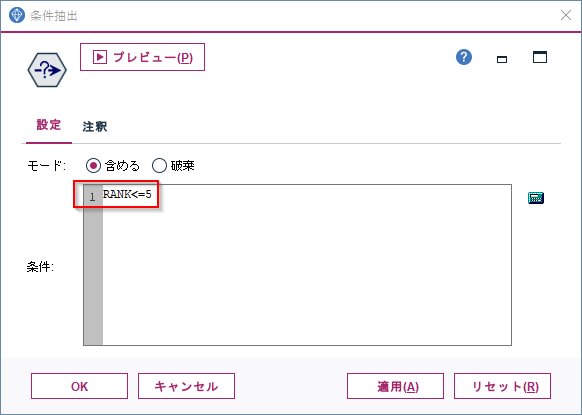
後は例えば、上位5位までのアイテムだけを絞り込むというようなことが可能です。
条件抽出ノードにRANK<=5を設定しています。
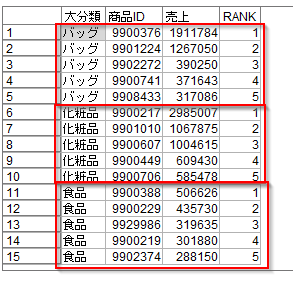
以下のように商品大分類ごとに売上順位5位までのアイテムのリストをつくることができました。
4. まとめ
このように@OFFSETは
- 前後のデータを参照することで、現在の値との差や比などの特徴量をつくる
- 直前のレコードと比較することでカテゴリをグルーピングする
- さらにグルーピングしながら、フィールド作成ノードのカウントモードで累積値をつくる
ことが可能です。
■テスト環境
Modeler 18.2.2
Windows 10 64bit