2018年のPFNのインターン選考のコーディング課題のうち、machine learning部門の問題を解いてみました。
問題: https://github.com/kamata1729/pfn_intern_ml_2018/blob/master/README-ja.pdf
解答: https://github.com/kamata1729/pfn_intern_ml_2018
課題1
問題



解答
とりあえず使いそうな関数をutils.pyにまとめておきます。
import math
def add(x: list, y: list):
assert len(x) == len(y), 'lengths of both vectors must be same'
return list(map(lambda a, b: a+b, x, y))
def sub(x: list, y: list):
assert len(x) == len(y), 'lengths of both vectors must be same'
return list(map(lambda a, b: a-b, x, y))
def product(x: list, y: list):
assert len(x) == len(y), 'lengths of both vectors must be same'
return sum(list(map(lambda x, y: x*y, x, y)))
def mul(A: list, x: list):
assert len(A[0]) == len(x), 'incorrect dimension'
return list(map(lambda a: product(a, x), A))
def scalor_add(a, x: list):
return list(map(lambda x: a + x, x))
def scalor_product(a, x: list):
return list(map(lambda x: a*x, x))
def transpose(A: list):
height = len(A)
width = len(A[0])
result = [[0] * height for _ in range(width)]
for i in range(len(A)):
for j in range(len(A[0])):
result[j][i] = A[i][j]
return result
これを使って課題1の検証用プログラムは以下のように書けます。
from utils import *
if __name__ == '__main__':
x = [-1,2]
y = [2,3]
A = [[1, 2], [3,4]]
print("x = ", x)
print("y = ", y)
print("A = ", A)
print("x+y = ", add(x, y))
print("Ax = ", mul(A, x))
print("A^T = ", transpose(A))
print("reu(x) = ", relu(x))
print("softmax(x) = ", softmax(x))
実行結果
$ python kadai1.py
x = [-1, 2]
y = [2, 3]
A = [[1, 2], [3, 4]]
x+y = [1, 5]
Ax = [3, 5]
A^T = [[1, 3], [2, 4]]
reu(x) = [0, 2]
softmax(x) = [0.04742587317756678, 0.9525741268224331]
課題2
問題


解答
utils.pyに新たに以下の関数を追加しておきます。
def relu(x: list):
return list(map(lambda x: max(x, 0), x))
def softmax(x: list):
exp_list = list(map(lambda a: math.exp(a), x))
return list(map(lambda a: a/sum(exp_list), exp_list))
def zero_vector(length: int):
return [0 for _ in range(length)]
def argmax(lis: list):
return lis.index(max(lis))
def cast(x: list, dtype: type):
return list(map(lambda a: dtype(a), x))
def accuracy(x: list, y: list):
assert len(x) == len(y), 'lengths of both vectors must be same'
return sum(list(map(lambda x, y: 1 if x == y else 0, x, y))) / len(x)
def one_hot(t, length):
res = zero_vector(length)
res[t] = 1
return res
def sign(x: list):
return list(map(lambda a: 1 if a > 0 else -1, x))
これらを使って課題2は以下のように書けます
from utils import *
from tqdm import tqdm
def read_img(path):
with open(path) as f:
f = f.read()
f = f.split("\n")
img = sum([vec.split() for vec in f[3:35]], [])
img = cast(img, dtype=float)
img = scalor_product(1/255, img)
return img
def read_params(path="param.txt"):
H = 256
C = 23
with open(path) as f:
f = f.read()
f = f.split("\n")
result = {'W_1': [], 'b_1': [], 'W_2': [], 'b_2': [], 'W_3': [], 'b_3': []}
for i in range(2*H + C + 3):
if i < H:
result['W_1'].append(cast(f[i].split(), dtype=float))
if i == H:
result['b_1'].append(cast(f[i].split(), dtype=float))
if H < i and i < 2*H + 1:
result['W_2'].append(cast(f[i].split(), dtype=float))
if i == 2*H + 1:
result['b_2'].append(cast(f[i].split(), dtype=float))
if 2*H + 1 < i < 2*H + C + 2:
result['W_3'].append(cast(f[i].split(), dtype=float))
if i == 2*H + C + 2:
result['b_3'].append(cast(f[i].split(), dtype=float))
return result
def read_labels(filename="labels.txt"):
with open(filename) as f:
f = f.read()
f = f.split("\n")
return scalor_add(-1, cast(f[:-1], dtype=int)) # label range is 0 to 22
def predict(params, img):
def linear(x, W, b):
return add(mul(W, x), b)
a_1 = linear(img, params['W_1'], params['b_1'][0])
h_1 = relu(a_1)
a_2 = linear(h_1, params['W_2'], params['b_2'][0])
h_2 = relu(a_2)
y = linear(h_2, params['W_3'], params['b_3'][0])
result = softmax(y)
return result
def predict_all():
params = params = read_params()
labels = read_labels()
predicts = zero_vector(len(labels))
for i in tqdm(range(len(labels))):
img = read_img("pgm/{}.pgm".format(i+1))
predicted_values = predict(params, img)
predicts[i] = argmax(predicted_values)
return accuracy(predicts, labels)
if __name__ == '__main__':
acc = predict_all()
print("accuracy: ", acc)
実行結果
正解率が83.7%出ているので正しく実装できています。
$ python kadai2.py
100%|█████████████████████████████████████████| 154/154 [00:08<00:00, 18.76it/s]
accuracy: 0.8376623376623377
課題3
問題

解答
これまでで実装した関数などを用いて、以下のように実装できます。
問題文に書いてある通りに実装するだけです。
python kadai3.py --show_graphで正解率のグラフを出せるようにしています。
import os
import random
import argparse
from tqdm import tqdm
from utils import *
from kadai2 import *
def predict_with_backward(params, img, t):
def linear(x, W, b):
return add(mul(W, x), b)
def backward(x, y):
assert len(x) == len(y), 'lengths of both vectors must be same'
return list(map(lambda p, q: p if q > 0 else 0, x, y))
# forward
a_1 = linear(img, params['W_1'], params['b_1'][0])
h_1 = relu(a_1)
a_2 = linear(h_1, params['W_2'], params['b_2'][0])
h_2 = relu(a_2)
y = linear(h_2, params['W_3'], params['b_3'][0])
f_x = softmax(y)
# backward
nabla_y = sub(f_x, one_hot(t, len(f_x)))
nabla_h2 = mul(transpose(params['W_3']), nabla_y)
nabla_a2 = backward(nabla_h2, a_2)
nabla_h1 = mul(transpose(params['W_2']), nabla_a2)
nabla_a1 = backward(nabla_h1, a_1)
nabla_x = mul(transpose(params['W_1']), nabla_a1)
return nabla_x
def fgsm_img(params, img, t, eps_0=0.1):
nabla_x = predict_with_backward(params, img, t)
img_fgsm = add(img, scalor_product(eps_0, sign(nabla_x)))
return img_fgsm
def encode_pgm(img, path):
folder_path = ''.join(path.split('/')[:-1])
os.makedirs(folder_path, exist_ok=True)
img = scalor_product(1/max(img), img)
img = scalor_product(255, img)
img = list(map(lambda x: max(int(x), 0), img))
des = "P2\n32 32\n255\n"
for i in range(32):
des += ' '.join(cast(img[i*32: (i+1)*32], dtype=str)) + '\n'
with open(path, mode='w') as f:
f.write(des)
def baseline_img(img, eps_0=0.1):
eps = [eps_0*random.randint(-1, 1) for _ in range(len(img))]
return add(img, eps)
def execute_fgsm(params, labels, eps_0=0.1, save_fgsm=False, save_baseline=False):
predicts_fgsm = zero_vector(len(labels))
predicts_baseline = zero_vector(len(labels))
for i in tqdm(range(len(labels)), desc='eps_0={}'.format(eps_0)):
img = read_img("pgm/{}.pgm".format(i+1))
img_fgsm = fgsm_img(params, img, labels[i], eps_0)
predicts_fgsm[i] = argmax(predict(params, img_fgsm))
if save_fgsm:
encode_pgm(img_fgsm,
"pgm_fgsm_{}/{}.pgm".format(str(eps_0).replace('.', ''), i+1))
img_baseline = baseline_img(img, eps_0)
predicts_baseline[i] = argmax(predict(params, img_baseline))
if save_baseline:
encode_pgm(img_baseline,
"pgm_baseline_{}/{}.pgm".format(str(eps_0).replace('.', ''), i+1))
return {"fgsm": accuracy(predicts_fgsm, labels),
"baseline": accuracy(predicts_baseline, labels)}
def plot(epss, fgsm_accs, baseline_accs, filename='plot.png'):
import matplotlib.pyplot as plt
plt.plot(epss, fgsm_accs, label='FGSM')
plt.plot(epss, baseline_accs, label='baseline')
plt.xlabel('eps_0')
plt.ylabel('accuracy')
plt.legend()
plt.savefig(filename)
print("saved ", filename)
return
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument('--eps_0', type=float)
parser.add_argument('--save_fgsm', action='store_true')
parser.add_argument('--save_baseline', action='store_true')
parser.add_argument('--show_graph', action='store_true')
args = parser.parse_args()
assert not args.eps_0 or not args.show_graph, "either --eps_0 or --show_graph can be specified"
if args.eps_0 or (not args.eps_0 and not args.show_graph):
eps_0 = args.eps_0 if args.eps_0 else 0.1
params = read_params()
labels = read_labels()
result = execute_fgsm(params, labels, eps_0,
args.save_fgsm, args.save_baseline)
print("accuracy fgsm (eps_0={}): {:.7f}".format(
args.eps_0, result['fgsm']))
print("accuracy baseline (eps_0={}): {:.7f}".format(
args.eps_0, result['baseline']))
if args.show_graph:
epss = [0, 0.05, 0.1, 0.2, 0.5, 0.8]
fgsm_accs = zero_vector(len(epss))
baseline_accs = zero_vector(len(epss))
params = read_params()
labels = read_labels()
for i in range(len(epss)):
if epss[i] == 0:
pred = predict_all()
fgsm_accs[i] = pred
baseline_accs[i] = pred
else:
result = execute_fgsm(params, labels, epss[i],
args.save_fgsm, args.save_baseline)
fgsm_accs[i] = result['fgsm']
baseline_accs[i] = result['baseline']
print("accuracy fgsm (eps_0={}): {:.7f}".format(
epss[i], fgsm_accs[i]))
print("accuracy baseline (eps_0={}): {:.7f}".format(
epss[i], baseline_accs[i]))
plot(epss, fgsm_accs, baseline_accs)
実行結果
FGSMを使用すると急激に正解率が下がっていることがわかります。
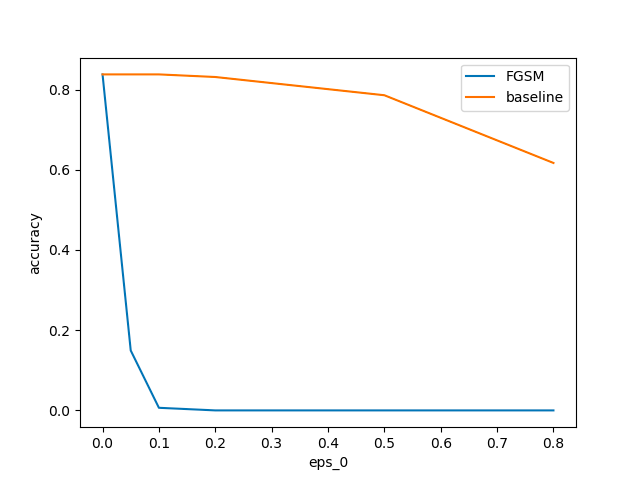
$epsilon_0=0.1$の場合の例を以下に示します。
少しの変化で大きく予測結果が変わってしまうことがわかります。
| original | FGSM | baseline |
|---|---|---|
 |
 |
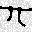 |
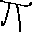 |
 |
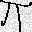 |
 |
 |
 |
課題4
問題

解答
今回はせっかくなので、3つの方向性全てをやってみたいと思います
一度全部numpyで書き直すことにします(リストのままやると結構時間がかかるので...)
全体のコードは最後に載せますが、先に汎用性のある関数をまとめておきます
import numpy as np
from tqdm import tqdm
import matplotlib.pyplot as plt
import cv2
import argparse
def cast(x: list, dtype: type):
return list(map(lambda a: dtype(a), x))
def read_img(path):
img = cv2.imread(path, 0) / 255
return img.reshape(-1)
def read_params(path="param.txt"):
H = 256
C = 23
N = 1024
with open(path) as f:
f = f.read()
f = f.split("\n")
result = {'W_1': [], 'b_1': [], 'W_2': [], 'b_2': [], 'W_3': [], 'b_3': []}
for i in range(2*H + C + 3):
if i < H:
result['W_1'].append(cast(f[i].split(), dtype=float))
if i == H:
result['b_1'].append(cast(f[i].split(), dtype=float))
if H < i and i < 2*H + 1:
result['W_2'].append(cast(f[i].split(), dtype=float))
if i == 2*H + 1:
result['b_2'].append(cast(f[i].split(), dtype=float))
if 2*H + 1 < i < 2*H + C + 2:
result['W_3'].append(cast(f[i].split(), dtype=float))
if i == 2*H + C + 2:
result['b_3'].append(cast(f[i].split(), dtype=float))
for key in result.keys():
result[key] = np.array(result[key])
if key.startswith('b'):
result[key] = result[key][0]
return result
def read_labels(filename="labels.txt"):
with open(filename) as f:
f = f.read()
f = f.split("\n")
return np.array(cast(f[:-1], dtype=int)) - 1 # label range is 0 to 22
def one_hot(t, length):
return np.eye(length)[t]
def relu(x):
return np.maximum(x, 0)
def softmax(x):
return np.exp(x)/np.sum(np.exp(x))
def sign(x):
x = x.copy()
x[x > 0] = 1
x[x <= 0] = -1
return x
def plot(ygrid, ygrid_name, fgsm_accs, baseline_accs, filename):
plt.plot(ygrid, fgsm_accs, label='FGSM')
plt.plot(ygrid, baseline_accs, label='baseline')
plt.xlabel(ygrid_name)
plt.ylabel('accuracy')
plt.legend()
plt.savefig(filename)
print("saved: ", filename)
return
方向性1
FGSMの出力をもう一度FGSMに入力することを繰り返すことで敵対的入力を作る
さきほどのコードに以下を追加します。
execute_fgsm_repeatのrepeat_countに繰り返す回数を入れることで実現できるようにしています
#################################################
# Derection 1
#################################################
def predict(params, img):
a_1 = params['W_1']@img + params['b_1']
h_1 = relu(a_1)
a_2 = params['W_2']@h_1 + params['b_2']
h_2 = relu(a_2)
y = params['W_3']@h_2 + params['b_3']
f_x = softmax(y)
return f_x
def predict_with_backward(params, img, t, return_prob=False):
def backward(p, q):
return p * (q > 0)
# forward
a_1 = params['W_1']@img + params['b_1']
h_1 = relu(a_1)
a_2 = params['W_2']@h_1 + params['b_2']
h_2 = relu(a_2)
y = params['W_3']@h_2 + params['b_3']
f_x = softmax(y)
# backward
nabla_y = - one_hot(t, len(f_x)) + f_x
nabla_h2 = params['W_3'].T @ nabla_y
nabla_a2 = backward(nabla_h2, a_2)
nabla_h1 = params['W_2'].T @ nabla_a2
nabla_a1 = backward(nabla_h1, a_1)
nabla_x = params['W_1'].T @ nabla_a1
if return_prob:
return nabla_x, f_x
else:
return nabla_x
def baseline_img(img, eps_0=0.1):
return img + eps_0 * (np.random.randint(0, 2, len(img))*2 - 1)
def fgsm_img(params, img, t, eps_0=0.1):
nabla_x = predict_with_backward(params, img, t)
img_fgsm = img + eps_0 * sign(nabla_x)
return img_fgsm
def execute_fgsm_repeat(params, labels, eps_0=0.01, repeat_count=1):
predicts_fgsm = np.zeros(len(labels))
predicts_baseline = np.zeros(len(labels))
for i in tqdm(range(len(labels)), desc='eps_0={}'.format(eps_0)):
img = read_img("pgm/{}.pgm".format(i+1))
img_fgsm = img.copy()
img_baseline = img.copy()
for _ in range(repeat_count):
img_fgsm = fgsm_img(params, img_fgsm, labels[i], eps_0)
img_baseline = baseline_img(img_baseline, eps_0)
predicts_fgsm[i] = predict(params, img_fgsm).argmax()
predicts_baseline[i] = predict(params, img_baseline).argmax()
return {"fgsm": np.sum(predicts_fgsm == labels) / len(labels),
"baseline": np.sum(predicts_baseline == labels) / len(labels)}
def direction1():
params = read_params()
labels = read_labels()
max_count = 10
fgsm_accs = np.zeros(max_count)
baseline_accs = np.zeros(max_count)
for i, repeat_count in enumerate(range(max_count)):
result = execute_fgsm_repeat(
params, labels, repeat_count=repeat_count)
fgsm_accs[i] = result['fgsm']
baseline_accs[i] = result['baseline']
plot(list(range(max_count)), "repeat count",
fgsm_accs, baseline_accs, "plot_repeat.png")
if __name__ == '__main__':
direction1()
実行結果
$\epsilon_0 = 0.01$として、0~9回まで繰り返す回数を変えて正解率を比較した結果です。
baselineのほうは何度繰り返しても正解率がほぼ変わっていないのに対し、FGSMの方は繰り返すごとに正解率が下がっています。
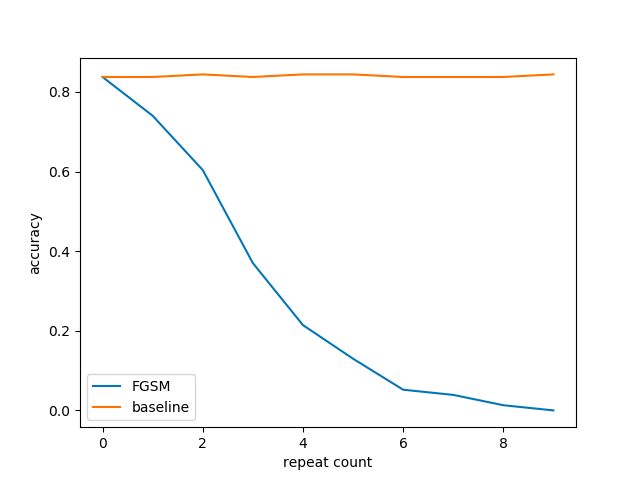
方向性2
入力がモノクロ化されてしまうことに対する攻撃
今までの方法では、小さな摂動を加えるだけだったので、モノクロ化した際にはその摂動が切り捨てられてしまい、攻撃できなくなってしまいます。
そこで今回は、$\nabla_x L$の絶対値が大きい画素を$+1$もしくは$-1$することによって、モノクロ化されても攻撃できるようにしています。
以下のコードをこれまでのコードに追加します。
#################################################
# Derection 2
#################################################
# nabla_x Lの絶対値が大きい画素を変更する
def fgsm_img_mono(params, img, t, rho=0.2):
img_fgsm = img.copy()
nabla_x = predict_with_backward(params, img, t)
noise = np.zeros_like(nabla_x)
noise[nabla_x > 0] = 1
noise[nabla_x <= 0] = -1
flag = np.argsort(np.abs(nabla_x)) > (1 - rho)*len(nabla_x)
img_fgsm[flag] += noise[flag]
img_fgsm = np.clip(img_fgsm, 0, 1)
return img_fgsm
def baseline_img_mono(img, rho=0.2):
noise = np.random.randint(-1, 2, len(img))
flag = np.random.rand(len(img)) < rho
return np.clip(img+flag*noise, 0, 1)
def execute_fgsm_mono(params, labels, rho=0.05):
predicts_fgsm = np.zeros(len(labels))
predicts_baseline = np.zeros(len(labels))
for i in tqdm(range(len(labels)), desc='rho={}'.format(rho)):
img = read_img("pgm/{}.pgm".format(i+1))
img_fgsm_mono = fgsm_img_mono(params, img, labels[i], rho)
img_baseline = baseline_img_mono(img, rho)
predicts_fgsm[i] = predict(params, img_fgsm_mono).argmax()
predicts_baseline[i] = predict(params, img_baseline).argmax()
return {"fgsm": np.sum(predicts_fgsm == labels) / len(labels),
"baseline": np.sum(predicts_baseline == labels) / len(labels)}
def direction2():
params = read_params()
labels = read_labels()
rhos = [0, 0.05, 0.1, 0.2, 0.5, 0.8]
fgsm_accs = np.zeros_like(rhos)
baseline_accs = np.zeros_like(rhos)
for i, rho in enumerate(rhos):
result = execute_fgsm_mono(params, labels, rho)
fgsm_accs[i] = result['fgsm']
baseline_accs[i] = result['baseline']
plot(rhos, 'noise proportion', fgsm_accs,
baseline_accs, 'plot_mono.png')
if __name__ == '__main__':
direction2()
実行結果
ノイズの割合が大きくなるほど正解率が下がっています。
割街が0.2より大きくなると正解率はほぼ0%になっています。
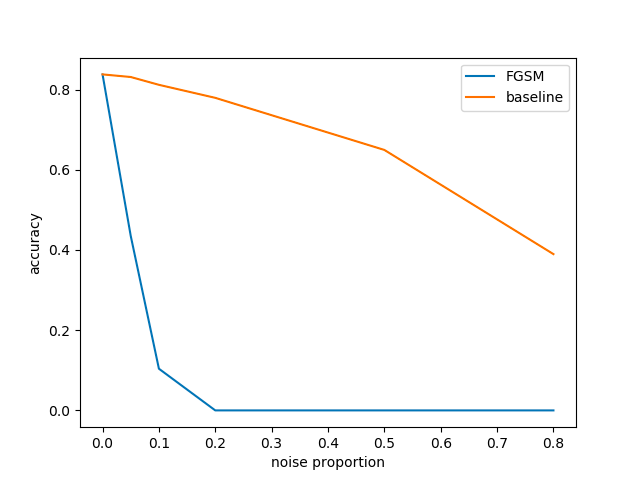
それぞれのノイズの割合で画像がどのように変化するかのサンプルは以下になります。
割合0.1や0.2ではそこまで変化させていないものの、正解率を大きく下げることができていることがわかります。
| 0 | 0.1 | 0.2 | 0.5 | 0.8 |
|---|---|---|---|---|
|
 |
 |
 |
 |
方向性3
モデルアンサンブルの実装とそれに対する攻撃
一般に複数のモデルでアンサンブルをすると精度は上がります。
それに対する攻撃としては、単純にそれぞれの$\nabla_x L$を足し合わせて、それに対してFGSMを行なっています。もっといい方法があったら教えてください。
足し合わせる時に、weighted_sum=Trueにすると正解ラベルの予測値の大きさに比例して足し合わせるようになっています。
#################################################
# Derection 3
#################################################
def predict_ensamble(params_list, img):
result = 0
for params in params_list:
result += predict(params, img)
return result / len(params_list)
def fgsm_img_ensemble(params_list, img, t, eps_0=0.1, weighted_sum=True):
nabla_x = 0
if weighted_sum:
nabla_x = np.zeros((len(params_list), 1024))
f_x = np.zeros((len(params_list), 23))
for i, params in enumerate(params_list):
nabla_x[i], f_x[i] = predict_with_backward(
params, img, t, return_prob=True)
nabla_x = nabla_x.T @ f_x[:, t] / np.sum(f_x[:, t])
else:
for params in params_list:
nabla_x += predict_with_backward(params, img, t)
nabla_x /= len(params_list)
img_fgsm = img + eps_0 * sign(nabla_x)
return img_fgsm
def execute_fgsm_ensemble(params_list, labels, eps_0=0.1, weighted_sum=True):
predicts_fgsm = np.zeros(len(labels))
predicts_baseline = np.zeros(len(labels))
for i in tqdm(range(len(labels)), desc='eps_0={}'.format(eps_0)):
img = read_img("pgm/{}.pgm".format(i+1))
img_fgsm = fgsm_img_ensemble(
params_list, img, labels[i], eps_0, weighted_sum)
img_baseline = baseline_img(img, eps_0)
predicts_fgsm[i] = predict_ensamble(params_list, img_fgsm).argmax()
predicts_baseline[i] = predict_ensamble(
params_list, img_baseline).argmax()
return {"fgsm": np.sum(predicts_fgsm == labels) / len(labels),
"baseline": np.sum(predicts_baseline == labels) / len(labels)}
def direction3(weighted_sum):
params_list = [read_params(
'extra/param_{}.txt'.format(i+1)) for i in range(9)]
labels = read_labels()
epss = [0, 0.05, 0.1, 0.2, 0.5, 0.8]
fgsm_accs = np.zeros_like(epss)
baseline_accs = np.zeros_like(epss)
for i, eps in enumerate(epss):
result = execute_fgsm_ensemble(
params_list, labels, eps_0=eps, weighted_sum=weighted_sum)
fgsm_accs[i] = result['fgsm']
baseline_accs[i] = result['baseline']
plot(epss, 'eps_0', fgsm_accs, baseline_accs, 'plot_ensamble_' +
('' if weighted_sum else 'non_') + 'weighted.png')
if __name__ == '__main__':
direction3(True)
direction3(False)
実行結果
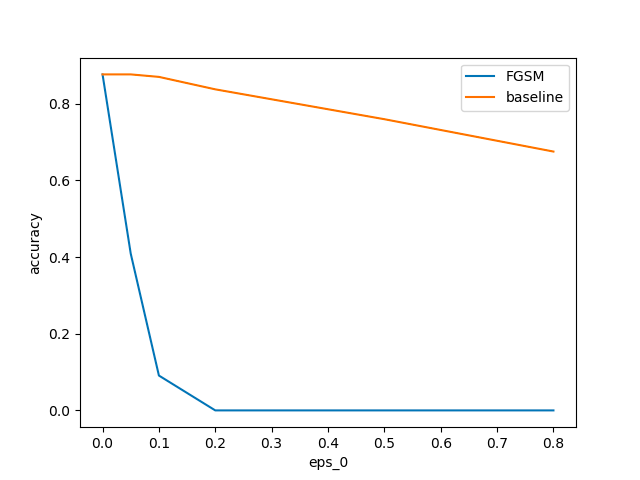
若干weighted_sum=Trueの方が正解率が下がっているが、大した差はなかった
* weighted_sum=True の場合
-
weighted_sum=Falseの場合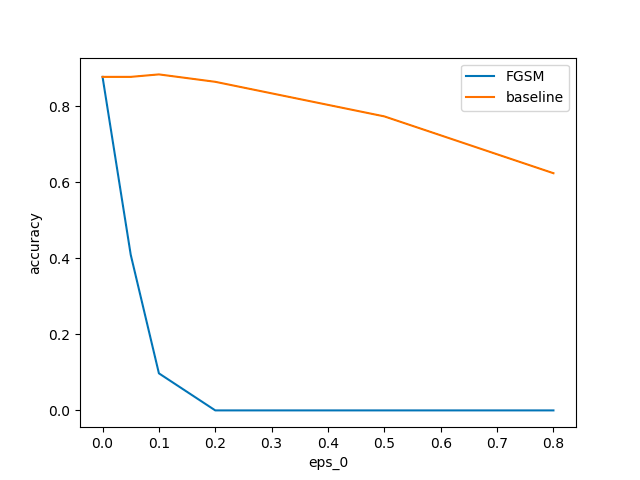
課題4のコード全体
import numpy as np
from tqdm import tqdm
import matplotlib.pyplot as plt
import cv2
import argparse
def cast(x: list, dtype: type):
return list(map(lambda a: dtype(a), x))
def read_img(path):
img = cv2.imread(path, 0) / 255
return img.reshape(-1)
def read_params(path="param.txt"):
H = 256
C = 23
N = 1024
with open(path) as f:
f = f.read()
f = f.split("\n")
result = {'W_1': [], 'b_1': [], 'W_2': [], 'b_2': [], 'W_3': [], 'b_3': []}
for i in range(2*H + C + 3):
if i < H:
result['W_1'].append(cast(f[i].split(), dtype=float))
if i == H:
result['b_1'].append(cast(f[i].split(), dtype=float))
if H < i and i < 2*H + 1:
result['W_2'].append(cast(f[i].split(), dtype=float))
if i == 2*H + 1:
result['b_2'].append(cast(f[i].split(), dtype=float))
if 2*H + 1 < i < 2*H + C + 2:
result['W_3'].append(cast(f[i].split(), dtype=float))
if i == 2*H + C + 2:
result['b_3'].append(cast(f[i].split(), dtype=float))
for key in result.keys():
result[key] = np.array(result[key])
if key.startswith('b'):
result[key] = result[key][0]
return result
def read_labels(filename="labels.txt"):
with open(filename) as f:
f = f.read()
f = f.split("\n")
return np.array(cast(f[:-1], dtype=int)) - 1 # label range is 0 to 22
def one_hot(t, length):
return np.eye(length)[t]
def relu(x):
return np.maximum(x, 0)
def softmax(x):
return np.exp(x)/np.sum(np.exp(x))
def sign(x):
x = x.copy()
x[x > 0] = 1
x[x <= 0] = -1
return x
def plot(ygrid, ygrid_name, fgsm_accs, baseline_accs, filename):
plt.plot(ygrid, fgsm_accs, label='FGSM')
plt.plot(ygrid, baseline_accs, label='baseline')
plt.xlabel(ygrid_name)
plt.ylabel('accuracy')
plt.legend()
plt.savefig(filename)
print("saved: ", filename)
return
#################################################
# Derection 1
#################################################
def predict(params, img):
a_1 = params['W_1']@img + params['b_1']
h_1 = relu(a_1)
a_2 = params['W_2']@h_1 + params['b_2']
h_2 = relu(a_2)
y = params['W_3']@h_2 + params['b_3']
f_x = softmax(y)
return f_x
def predict_with_backward(params, img, t, return_prob=False):
def backward(p, q):
return p * (q > 0)
# forward
a_1 = params['W_1']@img + params['b_1']
h_1 = relu(a_1)
a_2 = params['W_2']@h_1 + params['b_2']
h_2 = relu(a_2)
y = params['W_3']@h_2 + params['b_3']
f_x = softmax(y)
# backward
nabla_y = - one_hot(t, len(f_x)) + f_x
nabla_h2 = params['W_3'].T @ nabla_y
nabla_a2 = backward(nabla_h2, a_2)
nabla_h1 = params['W_2'].T @ nabla_a2
nabla_a1 = backward(nabla_h1, a_1)
nabla_x = params['W_1'].T @ nabla_a1
if return_prob:
return nabla_x, f_x
else:
return nabla_x
def baseline_img(img, eps_0=0.1):
return img + eps_0 * (np.random.randint(0, 2, len(img))*2 - 1)
def fgsm_img(params, img, t, eps_0=0.1):
nabla_x = predict_with_backward(params, img, t)
img_fgsm = img + eps_0 * sign(nabla_x)
return img_fgsm
def execute_fgsm_repeat(params, labels, eps_0=0.01, repeat_count=1):
predicts_fgsm = np.zeros(len(labels))
predicts_baseline = np.zeros(len(labels))
for i in tqdm(range(len(labels)), desc='eps_0={}'.format(eps_0)):
img = read_img("pgm/{}.pgm".format(i+1))
img_fgsm = img.copy()
img_baseline = img.copy()
for _ in range(repeat_count):
img_fgsm = fgsm_img(params, img_fgsm, labels[i], eps_0)
img_baseline = baseline_img(img_baseline, eps_0)
predicts_fgsm[i] = predict(params, img_fgsm).argmax()
predicts_baseline[i] = predict(params, img_baseline).argmax()
return {"fgsm": np.sum(predicts_fgsm == labels) / len(labels),
"baseline": np.sum(predicts_baseline == labels) / len(labels)}
def direction1():
params = read_params()
labels = read_labels()
max_count = 10
fgsm_accs = np.zeros(max_count)
baseline_accs = np.zeros(max_count)
for i, repeat_count in enumerate(range(max_count)):
result = execute_fgsm_repeat(
params, labels, repeat_count=repeat_count)
fgsm_accs[i] = result['fgsm']
baseline_accs[i] = result['baseline']
plot(list(range(max_count)), "repeat count",
fgsm_accs, baseline_accs, "plot_repeat.png")
#################################################
# Derection 2
#################################################
def fgsm_img_mono(params, img, t, rho=0.2):
img_fgsm = img.copy()
nabla_x = predict_with_backward(params, img, t)
noise = np.zeros_like(nabla_x)
noise[nabla_x > 0] = 1
noise[nabla_x <= 0] = -1
flag = np.argsort(np.abs(nabla_x)) > (1 - rho)*len(nabla_x)
img_fgsm[flag] += noise[flag]
img_fgsm = np.clip(img_fgsm, 0, 1)
return img_fgsm
def baseline_img_mono(img, rho=0.2):
noise = np.random.randint(-1, 2, len(img))
flag = np.random.rand(len(img)) < rho
return np.clip(img+flag*noise, 0, 1)
def execute_fgsm_mono(params, labels, rho=0.05):
predicts_fgsm = np.zeros(len(labels))
predicts_baseline = np.zeros(len(labels))
for i in tqdm(range(len(labels)), desc='rho={}'.format(rho)):
img = read_img("pgm/{}.pgm".format(i+1))
img_fgsm_mono = fgsm_img_mono(params, img, labels[i], rho)
img_baseline = baseline_img_mono(img, rho)
predicts_fgsm[i] = predict(params, img_fgsm_mono).argmax()
predicts_baseline[i] = predict(params, img_baseline).argmax()
return {"fgsm": np.sum(predicts_fgsm == labels) / len(labels),
"baseline": np.sum(predicts_baseline == labels) / len(labels)}
def direction2():
params = read_params()
labels = read_labels()
rhos = [0, 0.05, 0.1, 0.2, 0.5, 0.8]
fgsm_accs = np.zeros_like(rhos)
baseline_accs = np.zeros_like(rhos)
for i, rho in enumerate(rhos):
result = execute_fgsm_mono(params, labels, rho)
fgsm_accs[i] = result['fgsm']
baseline_accs[i] = result['baseline']
plot(rhos, 'noise proportion', fgsm_accs,
baseline_accs, 'plot_mono.png')
#################################################
# Derection 3
#################################################
def predict_ensamble(params_list, img):
result = 0
for params in params_list:
result += predict(params, img)
return result / len(params_list)
def fgsm_img_ensemble(params_list, img, t, eps_0=0.1, weighted_sum=True):
nabla_x = 0
if weighted_sum:
nabla_x = np.zeros((len(params_list), 1024))
f_x = np.zeros((len(params_list), 23))
for i, params in enumerate(params_list):
nabla_x[i], f_x[i] = predict_with_backward(
params, img, t, return_prob=True)
nabla_x = nabla_x.T @ f_x[:, t] / np.sum(f_x[:, t])
else:
for params in params_list:
nabla_x += predict_with_backward(params, img, t)
nabla_x /= len(params_list)
img_fgsm = img + eps_0 * sign(nabla_x)
return img_fgsm
def execute_fgsm_ensemble(params_list, labels, eps_0=0.1, weighted_sum=True):
predicts_fgsm = np.zeros(len(labels))
predicts_baseline = np.zeros(len(labels))
for i in tqdm(range(len(labels)), desc='eps_0={}'.format(eps_0)):
img = read_img("pgm/{}.pgm".format(i+1))
img_fgsm = fgsm_img_ensemble(
params_list, img, labels[i], eps_0, weighted_sum)
img_baseline = baseline_img(img, eps_0)
predicts_fgsm[i] = predict_ensamble(params_list, img_fgsm).argmax()
predicts_baseline[i] = predict_ensamble(
params_list, img_baseline).argmax()
return {"fgsm": np.sum(predicts_fgsm == labels) / len(labels),
"baseline": np.sum(predicts_baseline == labels) / len(labels)}
def direction3(weighted_sum):
params_list = [read_params(
'extra/param_{}.txt'.format(i+1)) for i in range(9)]
labels = read_labels()
epss = [0, 0.05, 0.1, 0.2, 0.5, 0.8]
fgsm_accs = np.zeros_like(epss)
baseline_accs = np.zeros_like(epss)
for i, eps in enumerate(epss):
result = execute_fgsm_ensemble(
params_list, labels, eps_0=eps, weighted_sum=weighted_sum)
fgsm_accs[i] = result['fgsm']
baseline_accs[i] = result['baseline']
plot(epss, 'eps_0', fgsm_accs, baseline_accs, 'plot_ensamble_' +
('' if weighted_sum else 'non_') + 'weighted.png')
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument('direction', type=int, choices=[1,2,3])
parser.add_argument('--weighted_sum', action='store_true')
args = parser.parse_args()
if args.direction == 1:
direction1()
if args.direction == 2:
direction2()
if args.direction == 3:
direction3(args.weighted_sum)