はじめに
粒子系の並列シミュレーションフレームワークFDPSを使ってみる。
その4ではカットオフのあるLennard-Jones粒子系の二体衝突のシリアル計算を行った。次は全く同じ計算の並列版を実行し、軌道、エネルギーが一致するか確認する(基本)。
コードはここにおいてある。
https://github.com/kaityo256/fdps_sample
並列化にあたっての修正
まずはmakefileに、FDPSの並列化マクロなどを追加指定する。
CPPFLAGS += -DPARTICLE_SIMULATOR_MPI_PARALLEL
LDFLAGS=-lmpi -lmpi_cxx
フレームワークの初期化直後にMPIのrankとプロセス数も取得しておこう。
PS::Initialize(argc, argv);
const int rank = PS::Comm::getRank();
const int procs = PS::Comm::getNumberOfProc();
粒子を追加するにあたって、とりあえずプロセス0に突っ込んで、粒子の分配はフレームワークに任せることにする。
const int N = 2;
if (rank == 0){
lj_system.setNumberOfParticleLocal(N);
lj_system[0].id = 0;
lj_system[0].p = PS::F64vec(1.0, 0.0, 0.0);
lj_system[0].q = PS::F64vec(2.5, 5.0, 5.0);
lj_system[1].id = 1;
lj_system[1].p = PS::F64vec(-1.0, 0.0, 0.0);
lj_system[1].q = PS::F64vec(7.5, 5.0, 5.0);
}else{
lj_system.setNumberOfParticleLocal(0);
}
dinfo.decomposeDomainAll(lj_system); // 領域分割
lj_system.exchangeParticle(dinfo); // 粒子の分配
エネルギーの計算だが、既に二体関数であるポテンシャルエネルギーを一体関数として分配してあるため、AllReduceするだけで良い。そのラッパーであるPS::Comm::getSumを呼ぶと、エネルギーを返す関数は
template<class Tpsys>
PS::F64
energy(const Tpsys &system){
PS::F64 e = 0.0;
const PS::S32 n = system.getNumberOfParticleLocal();
for(PS::S32 i = 0; i < n; i++) {
FPLJ a = system[i];
e += (a.p*a.p)*0.5;
e += a.potential;
}
return PS::Comm::getSum(e); //←ここを修正
}
と書ける。
結果の保存
各プロセスごとに、自分が持っている粒子を個別に吐く関数を作っておく。
template<class Tpsys>
void
dump(std::ostream &os, const PS::F64 s_time, Tpsys &system){
const PS::S32 n = system.getNumberOfParticleLocal();
if (n == 0)return;
os << s_time << " ";
for (PS::S32 i = 0; i < n; i++) {
os << system[i].q.x << " ";
}
os << std::endl;
}
メインループ
計算のメインループはこんな感じになる。
char filename[256];
sprintf(filename,"trac%02d.dat",rank);
std::ofstream ofs(filename);
for(int i=0;i<LOOP;i++){
drift(lj_system, dt*0.5);
tree_lj.calcForceAllAndWriteBack(CalcForceLJ(), lj_system, dinfo);
kick(lj_system, dt);
drift(lj_system, dt*0.5);
dump(ofs, s_time, lj_system);
tree_lj.calcForceAllAndWriteBack(CalcForceLJ(), lj_system, dinfo);
PS::F64 e = energy(lj_system);
if (rank==0){
std::cout << s_time << " " << e << std::endl;
}
s_time += dt;
}
結果の出力まわり以外、シリアル版とほとんどかわらない。なお、エネルギーの計算ルーチンenergyの内部でMPI_Allreduceを呼んでいるため、
if (rank==0){
std::cout << s_time << " " << energy(lj_system) << std::endl;
}
みたいなことをするとデッドロックする1。なので一度外で変数に受けてから表示するようにしている。
結果
1プロセスでシリアル実行した場合と、2プロセスで並列実行した場合の粒子の軌道は以下の通り。
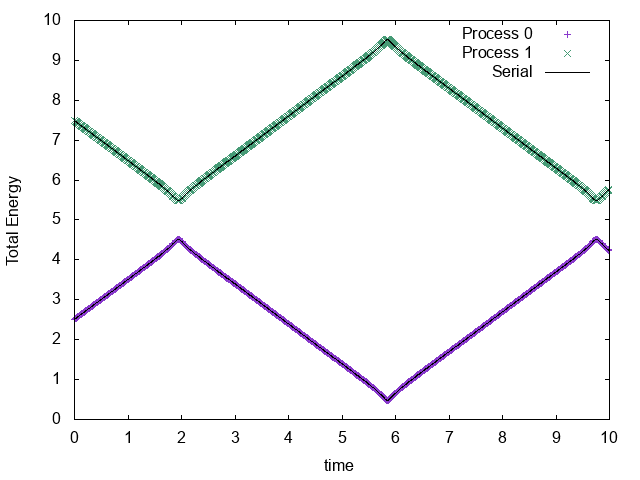
それぞれのプロセスが1粒子ずつ担当し、かつシリアル実行した場合と軌道が一致していることがわかる。
エネルギーの時間発展はこんな感じ。
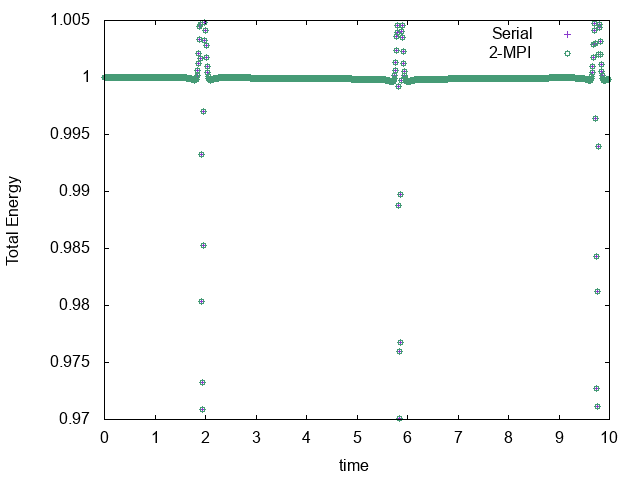
当然のことながら、完全に一致している。
まとめ
FDPSを使って相互作用のある粒子系を定義し、二粒子衝突の計算を並列化してみた。シリアル版がかけてしまえば、並列版に修正するのは容易だと思う。
以下のリポジトリのstep5でmake testすれば、コンパイルして、シリアル実行、2並列実行した結果の比較グラフまで作ってくれるはず。
その6に続く。
-
・・・というようなことを意識しなくて良いフレームワークが設計できれば、より美しいと思う。 ↩