目的
- AzureのDSVM(Data Science Virtual Machine)上でDeeplearning環境を作る。
- Tensorflowを使う。
- Object Detection APIを使う。
- NVIDIAのGPUを使う。
- 【重要】DSVMの初期バージョンのTensorflow-GPUではなく、最新のものを使いたい
バージョン
DSVMデプロイ時バージョン
| Name | Version |
|---|---|
| DSVM | NC6 Standard |
| OS | CentOS 7 |
| GPU | NVIDIA Tesla K80 |
| NVIDIA Driver | 390.12 |
| Cuda | 8.0 |
| Python | 3.5.2 |
| Tensorflow-gpu | 1.4.1 |
最終的なバージョン
| Name | Version |
|---|---|
| DSVM | NC6 Standard |
| OS | CentOS 7 |
| GPU | NVIDIA Tesla K80 |
| NVIDIA Driver | 384.125 |
| Cuda | 9.0 |
| Python | 3.5.2 |
| Tensorflow-gpu | 1.7.0 |
つまづきポイント
- そもそもDSVMでGPUマシンが選べない
- TensorflowのObjectDetectionAPIなどを使用する場合は、Tensorflow1.4じゃ動かないロジックがある。
- なのでTensorflow1.5以上を使用する必要がある。
- Tensorflowのバージョンを上げると、CUDAをバージョンアップする必要がある。
- CUDAを最新バージョンにすると動かない。なので9.0を指定してアップする必要がある。
- CUDAを上げると、必然的にNVIDIAのDriverも更新する必要がある。
- ObjectDetectionAPIをビルドするprotbufも最新バージョンだとうまいくいかないから、3.3でやる必要がある。
- CUDAのバージョンを上げたので、対応するcuDNNも必要になる。
結論:
とにかく大変なので、NVIDIAのDockerイメージを作ってそれを使いまわした方が後々便利。
しかしここでやったことは、Dockerを作る際の知見にもなるので記録しておく。
手順
1、NVIDIA Driverのバージョン変更(390.12→384.125)
現状のバージョンの確認
nvidia-smi
Sat Apr 7 07:03:11 2018
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 390.12 Driver Version: 390.12 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
|===============================+======================+======================|
| 0 Tesla K80 Off | 00000434:00:00.0 Off | 0 |
| N/A 43C P0 75W / 149W | 0MiB / 11441MiB | 59% Default |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: GPU Memory |
| GPU PID Type Process name Usage |
|=============================================================================|
| No running processes found |
+-----------------------------------------------------------------------------+
ドライバのダウンロード
http://www.nvidia.co.jp/Download/index.aspx?lang=jp
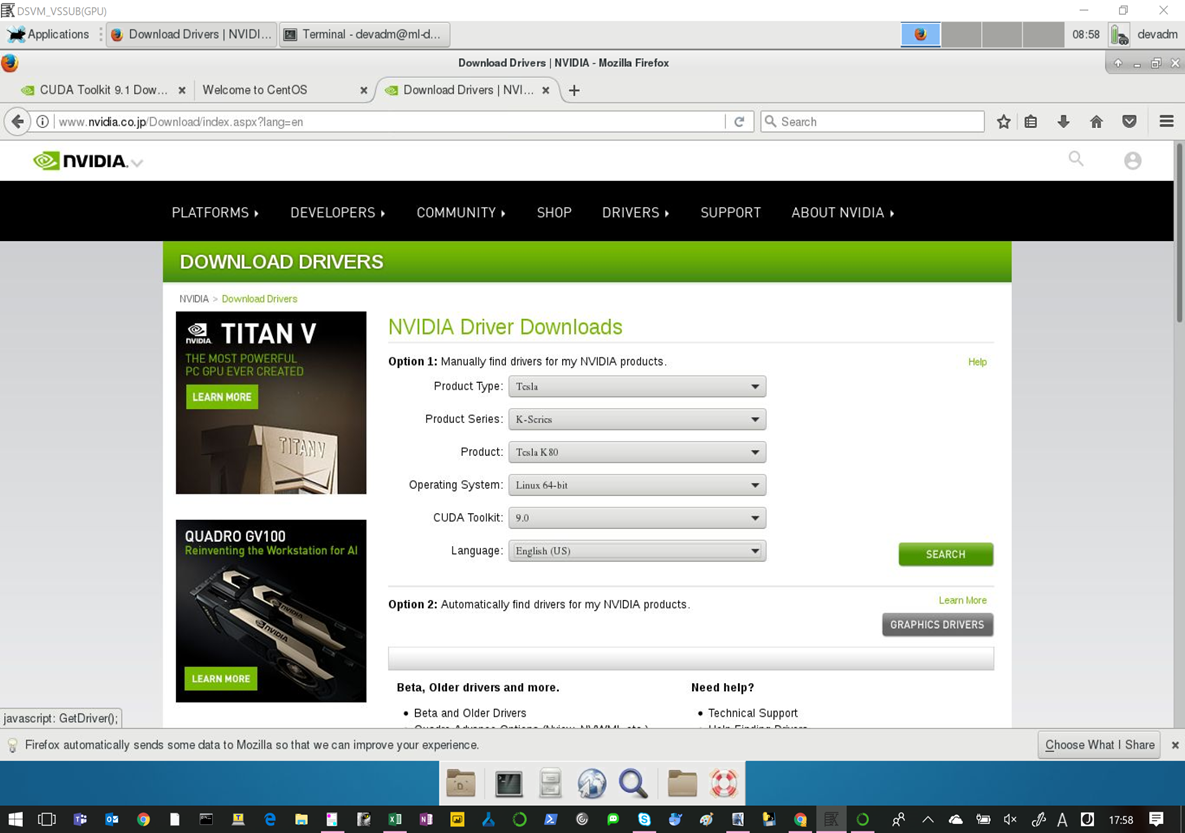
※現状のバージョン確認で確認したものと同じProductを選択し、CUDAのバージョンを9.0にする。
NCシリーズはTeslaのK80だが、NCV2シリーズはTeslaのP100なので要注意。
インストール
cd ~/Downloads/
sudo sh NVIDIA-Linux-x86_64-384.125.run
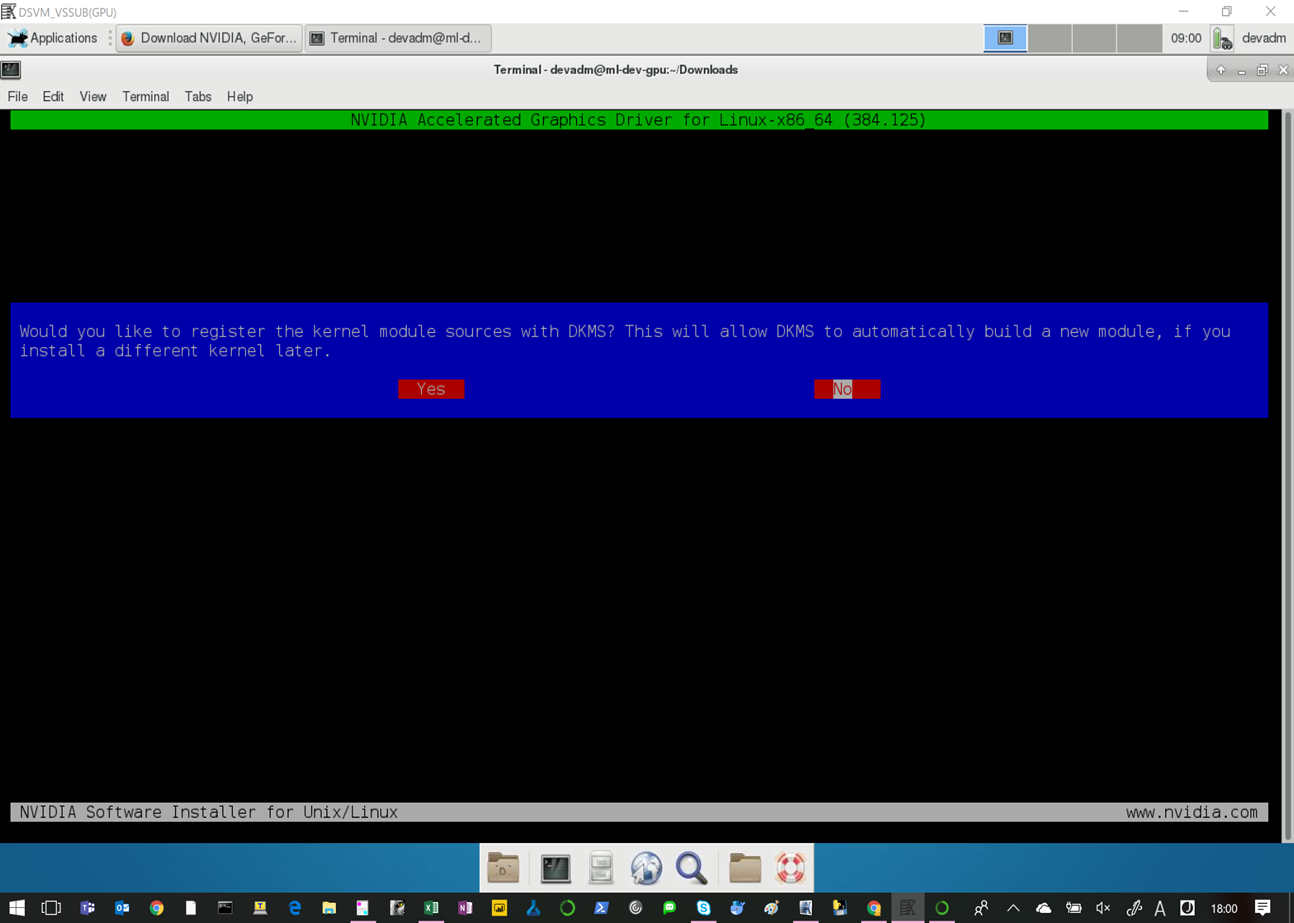
全部YESとOKで良い。
結果
nvidia-smi
Sat Apr 7 09:03:57 2018
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 384.125 Driver Version: 384.125 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
|===============================+======================+======================|
| 0 Tesla K80 Off | 00000434:00:00.0 Off | 0 |
| N/A 43C P0 75W / 149W | 0MiB / 11439MiB | 65% Default |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: GPU Memory |
| GPU PID Type Process name Usage |
|=============================================================================|
| No running processes found |
+-----------------------------------------------------------------------------+
sudo sh cuda_9.0.176_384.81_linux.run
2、CUDAのバージョン変更(8.0→9.0)
必ず9.0のサイトからダウンロードすること。最新版は不具合がある。
https://developer.nvidia.com/cuda-90-download-archive
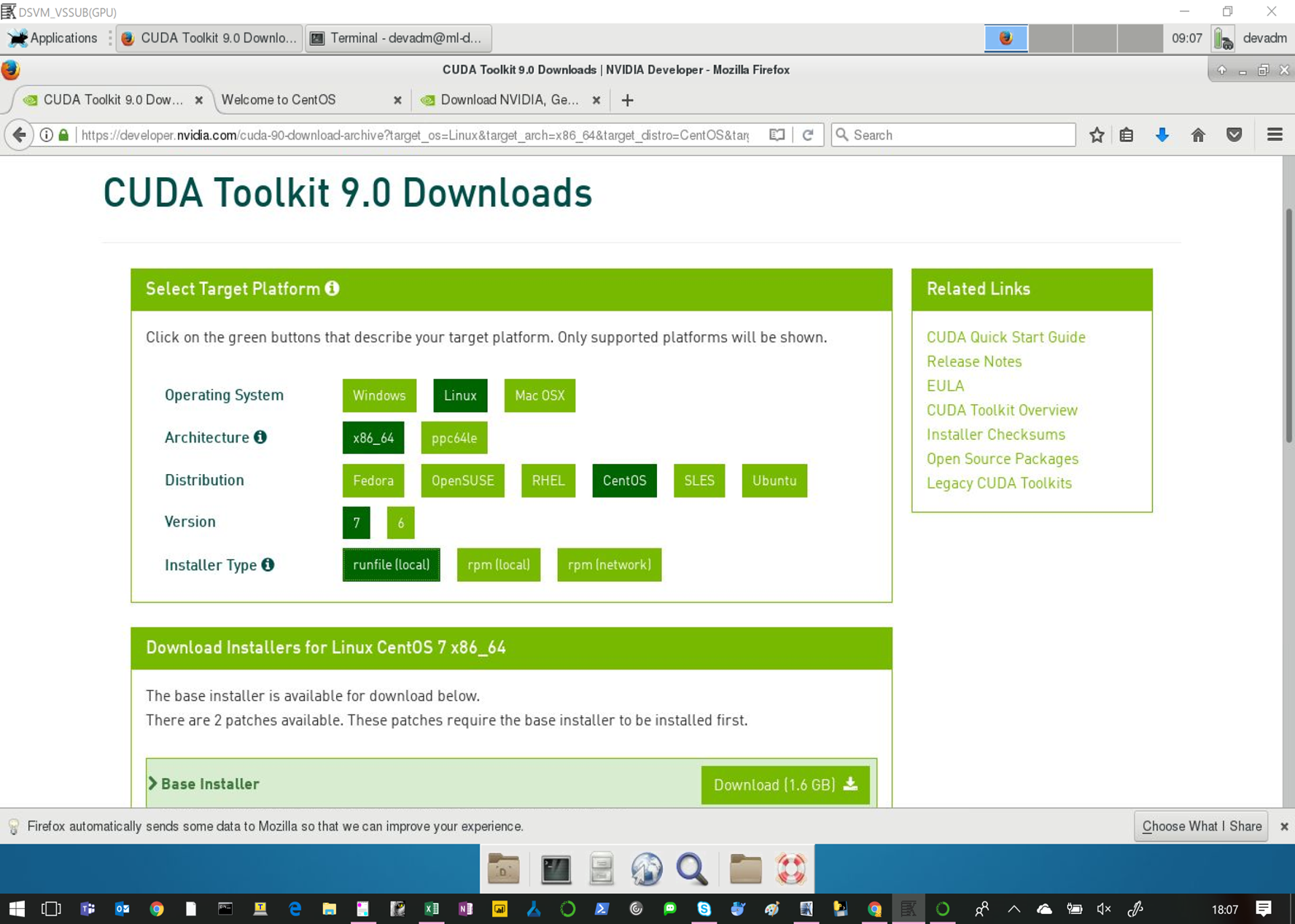
インストール
sudo sh cuda_9.0.176_384.81_linux.run
# 規約が表示されたら、Control+Cを押して、Acceptと入力してEnter
# その後、NVIDIAのGrapicDriverはNoを選択し、それ以外はすべてYesとする
Windows platform:
%ProgramFiles%\NVIDIA GPU Computing Toolkit\CUDA\v#.#
Linux platform:
Do you accept the previously read EULA?
accept/decline/quit: accept
Install NVIDIA Accelerated Graphics Driver for Linux-x86_64 384.81?
(y)es/(n)o/(q)uit: n
Install the CUDA 9.0 Toolkit?
(y)es/(n)o/(q)uit: y
Enter Toolkit Location
[ default is /usr/local/cuda-9.0 ]:
Do you want to install a symbolic link at /usr/local/cuda?
(y)es/(n)o/(q)uit: y
Install the CUDA 9.0 Samples?
(y)es/(n)o/(q)uit: y
Enter CUDA Samples Location
[ default is /home/devadm ]:
3、cudnnのダウンロードと配置
ログイン(ユーザー登録が必要)
ダウンロード
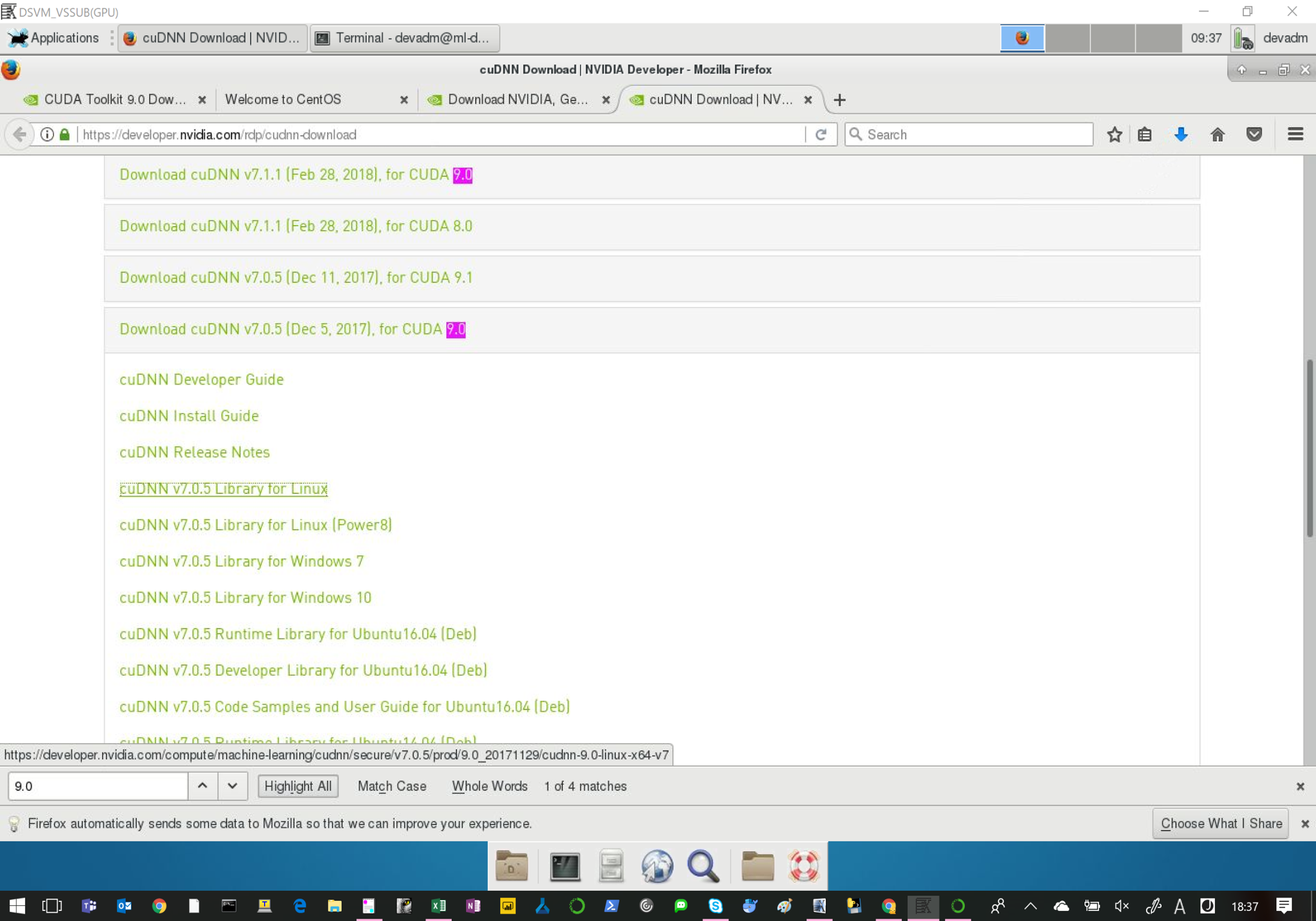
v7.0.5のfor Linuxを選択
配置
tar xvfz cudnn-9.0-linux-x64-v7.tgz
cd cuda
sudo cp lib64/libcudnn* /usr/local/cuda/lib64/
sudo cp lib64/libcudnn* /usr/local/cuda-9.0/lib64/
sudo cp include/cudnn.h /usr/local/cuda/include/
sudo cp include/cudnn.h /usr/local/cuda-9.0/include/
4、Tensorflow-gpuのアップグレード
アップグレード
pip list | grep tensorflow
tensorflow-gpu (1.4.1)
tensorflow-tensorboard (0.4.0rc3)
pip install --upgrade tensorflow-gpu
pip list | grep tensorflow
tensorflow-gpu (1.7.0)
tensorflow-tensorboard (0.4.0rc3)
Permissionエラーの場合はこちら
# usernameは、ログインユーザー名。もちろんchmodでもOK。
sudo chown -R {username}:{username} /anaconda/envs/py35/
5、Object Detection APIのダウンロードとビルド
ダウンロード
git clone https://github.com/tensorflow/models.git
パス通す
vim ~/.bash_profile
# 一番下の行に、下記を追加。{username}はログインしているユーザーの名前
export PYTHONPATH=$PYTHONPATH:/home/{username}/models/research:/home/{username}/models/research/slim:/home/{username}/models/research/object_detection
source ~/.bash_profile
ビルド(要注意)
yumでprotocの最新版を入れるとエラーで動かない。
なので3.3を利用する。
mkdir protoc_3.3
cd protoc_3.3/
wget wget https://github.com/google/protobuf/releases/download/v3.3.0/protoc-3.3.0-linux-x86_64.zip
chmod 775 protoc-3.3.0-linux-x86_64.zip
unzip protoc-3.3.0-linux-x86_64.zip
cd ~/models/research/
~/protoc_3.3/bin/protoc object_detection/protos/*.proto --python_out=.
# 何も表示されなければビルド完了
学習の実行
GPUを認識している様子
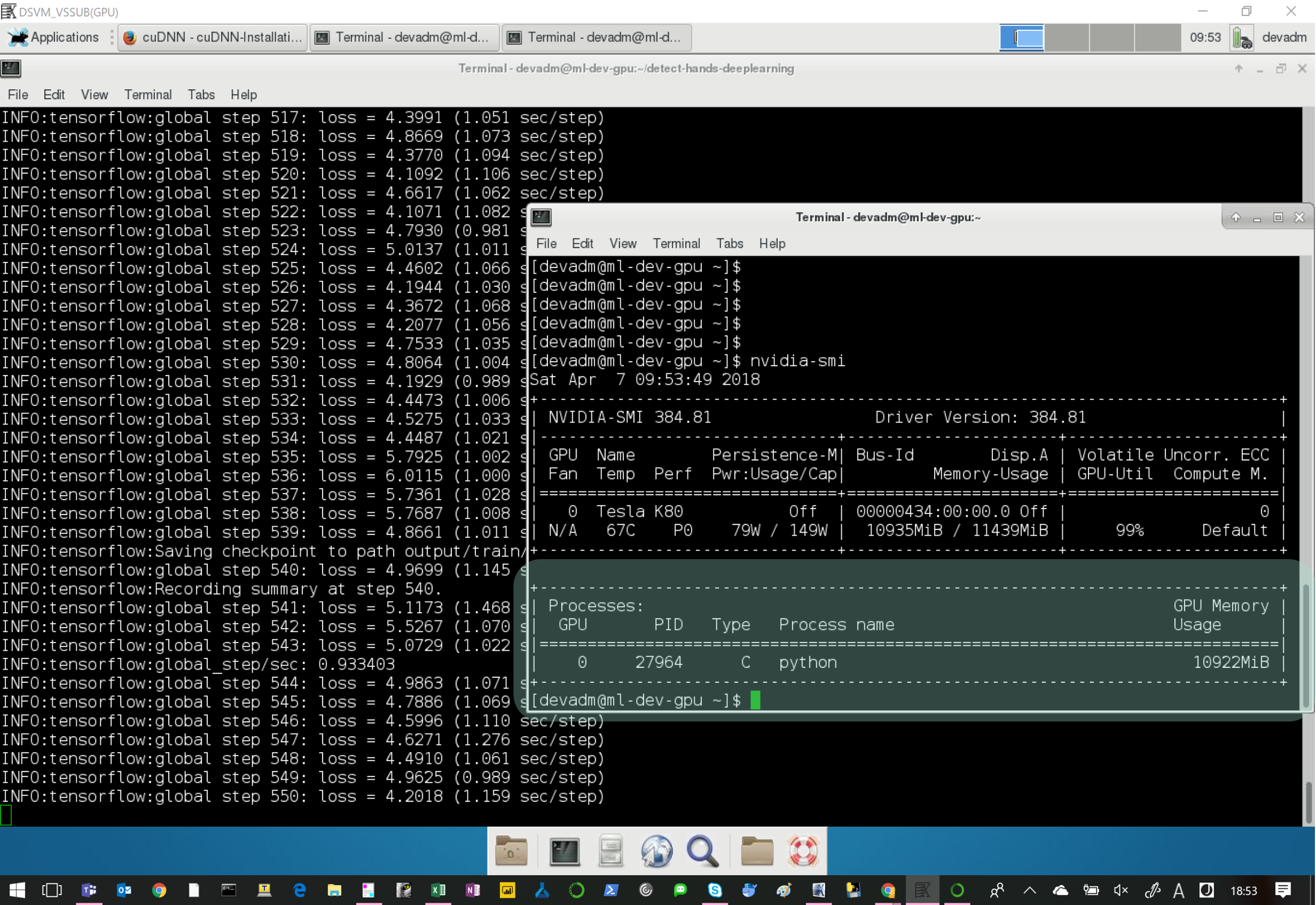
結論
- いろいろとトライ&エラーでやった結果、2日かかった。
- 今度はこれをDocker上に作成し、DockerHUBにあげるところまでやりたい。
- Object Detection APIの使い方については別途記事を書きます。
- ご指摘、ご質問などあれば気軽にご連絡ください。
以上です。