(2017/08/16 追記)
この記事は当時のアレな知識に基づくものです.
明らかな間違いも含まれてるので,ほどほどに参考にしていただければ幸いです.
まだ2月半ばとやや早いですが、連日二桁気温とすっかり春の陽気ですね。
こちらをご覧の皆様の周りにも、『サクラサク』便りが届き始めていることと思います。
一方、私は見事に就活5連敗中です。
さて、3週間ほど前に『Googleの囲碁AI『AlphaGo』が史上初めてプロ棋士に勝つ』という衝撃的なニュースが飛び込んできました。
囲碁は未解決問題とされており、先日も「これが評価につかえるのでは」という話をしたばかりだったので、実は昨年10月に既に決着していたというこのニュースには非常に驚きました。
そして、同時にこんなことも考えました。
『我々が知らないだけで、既に解決済みになっている問題は沢山あるのではないか?』
意外に思われるかもしれませんが、実は幾つかのゲームでは既に、人よりも優れた動作が学習可能になっています。(こちらが非常に詳しいです)
こちらの動画で用いられているDeep Q-Networkは2013年の手法であり、当時の論文では非常に簡単なモデルを使用しています。
一方、画像処理の界隈ではこの数年で研究が進み、Deep Q-Networkで用いられていたモデルよりも遥かに難しいモデルの有効性が認められるようになりました。
AlphaGoの成果もこうした画像処理のフィードバックがあってこそのものです。
そこで、『AlphaGoのように、あるいはAlphaGoよりも更に進んだ画像処理技術を持ち込めば、試されてないだけで既に複雑なアクションゲームも内部情報を使わずに攻略可能になっているのではないか』と考えたのです。
これはそんなことを考え、行動しちゃった、とある学生の2週間ちょっとの軌跡です。
背景
Deep Q-Networkやそれに類する研究では、主に1977年に発売されたAtari 2600のゲームがベンチマークとして用いられます。
これはライブラリが揃っているなどの理由もありますが、『Atari 2600よりも複雑なゲームを攻略することが難しい』という大きな理由があります。
特に立体的な情報処理の難しさから、3Dアクションゲームは難しいとされています。
そこで、Atari 2600よりも難しく3Dよりも簡単かつ適切な難易度のものとして、2Dシューティングゲームに着目しました。
2Dシューティングゲームは2Dであるため3Dほど高度な情報は求められませんが、Atari 2600のゲームよりも複雑かつ迅速な処理が求められます。
その中でも今回は、体験版が無料公開されており入手が容易な東方紺珠伝 ~ Legacy of Lunatic Kingdom.を攻略対象としました。
実際は単に東方Projectが好きって理由の方が大きいですが
設計
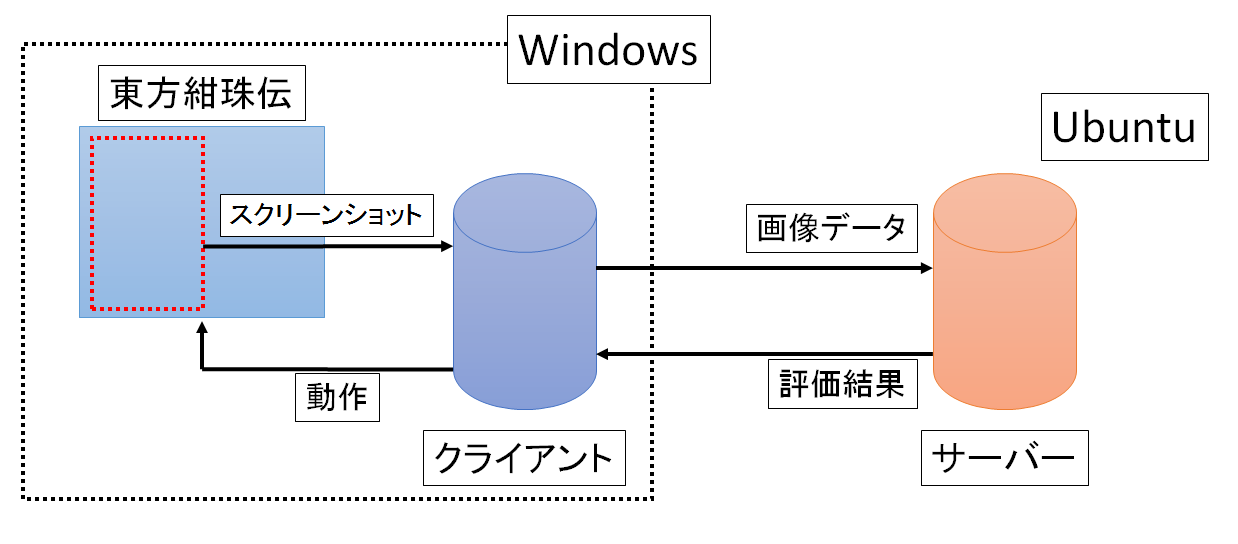
ざっくり言うとWindowsとUbuntu間でゲーム画面のスクリーンショットをやり取りして、ゲームに動作を返すという仕組みになっています。
実際の動作例
Twitterで簡単な動画を公開しています。
プログラム
modelを除く主なプログラムをgithubに公開しています…
が、試作状態のピーキーな設定のままになっています。
これをベースに何か書くのは向かないと思います。
プログラムの説明
クライアントはPILでスクリーンショットを撮ってnumpy化し、socketで画像を送ります。
サーバーはsocketで受け取ったらnumpyとOpenCVで整形し、Chainerで死亡判定と行動決定をします。
死亡判定が出なかった場合はsocketで行動を返します。
死亡判定が出た場合はメタ文を返し、エピソードを終えます。
また、場合に応じてChainerで学習を開始します。
クライアントは返答に応じてSendInputでDirectInput(DirectXゲーム用入力システム)に対応する動作を送ります。
死亡判定のメタ文が帰って来た場合には動作を一時停止し、待機します。
学習が行われる場合は待機を続け、それ以外では動作を再開します。
死亡判定

東方紺珠伝では死亡時に「攻略失敗」の文字が表示されます。
そこで、これを死亡の判定に用いています。
具体的にはこの文字が表示される領域を切り出すようにサーバー側で指定し、ゲーム画像かどうかを3層の簡単なモデルで判定します。
これは、99%以上の性能で判定が可能でした。
(とはいえたまに誤作動しちゃうのが玉に瑕)
行動決定

上のような、ある1フレームの画像に対して評価が最大の行動を選択します。
行動は計18パターン存在し、以下のようなものになります。
z(ショットボタン)
z(ショットボタン)+8方向
z(ショットボタン)+SHIFT(低速移動)
z(ショットボタン)+SHIFT(低速移動)+8方向
また、評価は行動と生存時間の組み合わせで学習、推定を行うという形式を取りました。
で、性能はどうだったの?
Lunatic(最高難易度)をベースに様々な組み合わせを試したものの、最初のチャプターを超えることが出来ませんでした。
先ほどの簡単な動画を見ていただければ分かるのですが、RANDOMでない場合、行動を一意に決定してしまっています。
これでは、操作キャラクターを狙う攻撃を避けきれず、死亡してしまいます。
これは、学習が進んでいないことが原因と考えられます。
上記の動画の中では、ある程度行動を終えるたびに学習を挟むことで評価を学習することを試みました。
実際に2000枚程度の画像を各5回使って学習した結果が上記のものです。
これは一般的な画像処理においても、充分な学習とは言い難い量です。
しかし、現在画像処理で用いられている100層以上のモデルで学習を行うためには、相当な計算量が必要となります。
自分の環境では、数千枚程度でも一度すべての画像を扱うために1時間近い時間がかかりました。
とはいえ一度扱うだけでも簡単な分類問題であれば充分に解けるのですが、今回試した限りではそう簡単なものではなかったようです。
じゃあ東方Projectを攻略するにはどうすりゃいいの!?
これ以上の学習を行うためには、近日公開が予定されている「Distributed TensorFlow」などの並列GPU計算ライブラリを使ってガッツリ処理する必要があると考えられます。
上記の記事では500台で300倍もの並列処理を行った事例が紹介されています。
この300倍の処理を用いることが出来れば、上記の問題は解決できると考えられます。
(実際にコレ使えば、700日近い計算時間が必要なAlphaGoも2日とちょっとで学習できちゃう計算になりますね)1
しかし、仮に現在市販されている中で最も高性能なGPU、TitanXを500個買うとなると、それだけで7000万以上となります。
貧乏学生にはとても出せる金額ではないのですが、この計算量はなんとかならないものですかねェ…。
それより先に僕は就職したいんですが、なんとかならないものですかねェ…。
参考文献
DQNの生い立ち + Deep Q-NetworkをChainerで書いた
Python版Pillowでスクリーンショットを撮る
OpenCVでRaspberry Piから画像を転送する
Simulate Python keypresses for controlling a game
訂正とお詫び (平成28年2月18日追記)
AlphaGoではDeep Q-Networkという手法が用いられています。
初稿では冒頭に上記の一文を掲載していました。
ですが「モデルを最適化する過程で強化学習は行われているが、Deep Q-Networkは使っておらず、明確な誤りである」とのご指摘を頂き、訂正させていただきました。
誤った情報を掲載してしまったことを、この場を借りてお詫び申し上げます。
-
少し時間が出来たので色んな文献を確認していたのですが、『これは勘違いで、そもそも分散して2年だったんじゃないか』という疑念が出てきました。確認が取れるまで、しばらく原文ママで掲載しておきます。(2016/3/13追記) ↩