地域再生計画をテキストマイニングして地方創生分析ー単語カウント&ワードクラウド編の続きです。
認定年毎の傾向分析
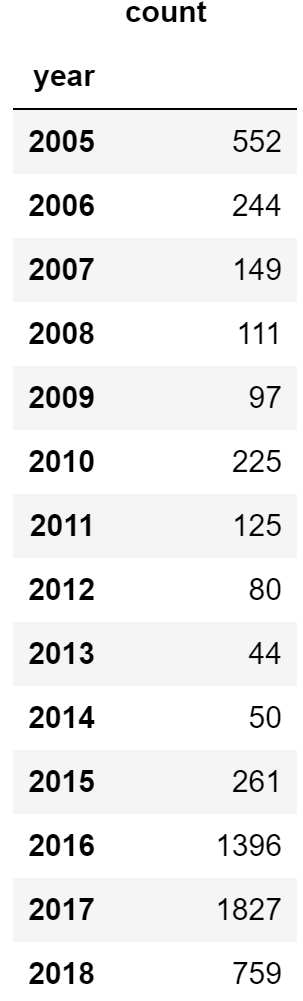
ここからは、認定年毎に地域再生計画概要のテキストを分解して、年毎にどのような特徴があるのか分析していきたいと思います。改めて、認定年毎の地域再生計画数の確認。
data[['year','plan_name']].groupby(['year']).agg(['count'])
label = list(data['year'].unique())
os.chdir('/mnt/c/ubuntu_home/text_mining/regional_plan/year')
for i in range(len(label)):
data[data['year']==label[i]]['plan_abs'].to_csv("{}.txt".format(label[i]), index=False, line_terminator='\n')
files = glob.glob('*.txt')
subdata_year = word_list_with_fileID('txt')
os.chdir('/mnt/c/ubuntu_home/text_mining/regional_plan/')
regional_plan/yearというフォルダに、年毎のテキストデータを保存していきます。filesというのは後にカラム名で使うためです。実際の単語の分かち書きはword_list_with_fileIDで行っています。コーディングスキルがないので、時間かかります…。
まずはコラム名から.txtを削除。
col_names = files
for i in range(0,len(col_names)):
col_names[i] = col_names[i].replace(".txt","")
次に必要なデータのみ抽出、subdata_year1の名前で格納。
stop_term = ['ある','いう','いる','する','できる','なる','思う','いる','れる','図る','行う','*',
'等','地域','事業','活用','整備','目指す','促進','推進','進める','取り組む','活かす','実施',
'本市','本町','本村','平成','実践','向上','分野']
subdata_year1 = subdata_year[(subdata_year['pos1']=='名詞') |
(subdata_year['pos1']=='形容詞') |
(subdata_year['pos1']=='動詞')]
subdata_year1 = subdata_year1[(subdata_year1['pos2']=='一般') |
(subdata_year1['pos2']=='固有名詞') |
(subdata_year1['pos2']=='自立') |
(subdata_year1['pos2']=='サ変接続')]
subdata_year1 = subdata_year1[~subdata_year1['term'].isin(stop_term)]
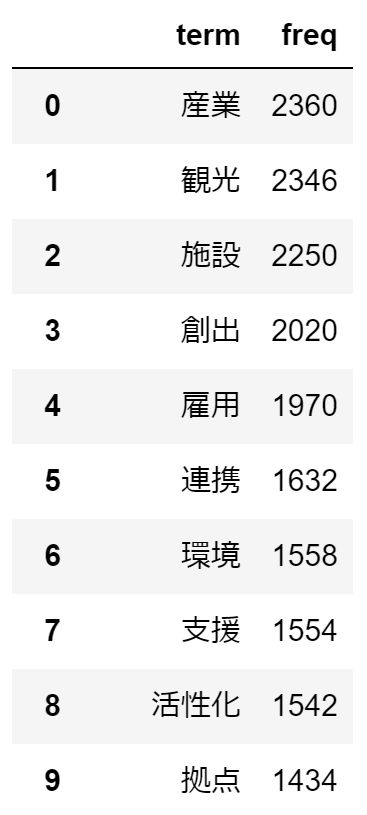
上位10単語はこちら
word_freq(subdata_year1['term']).head(10)
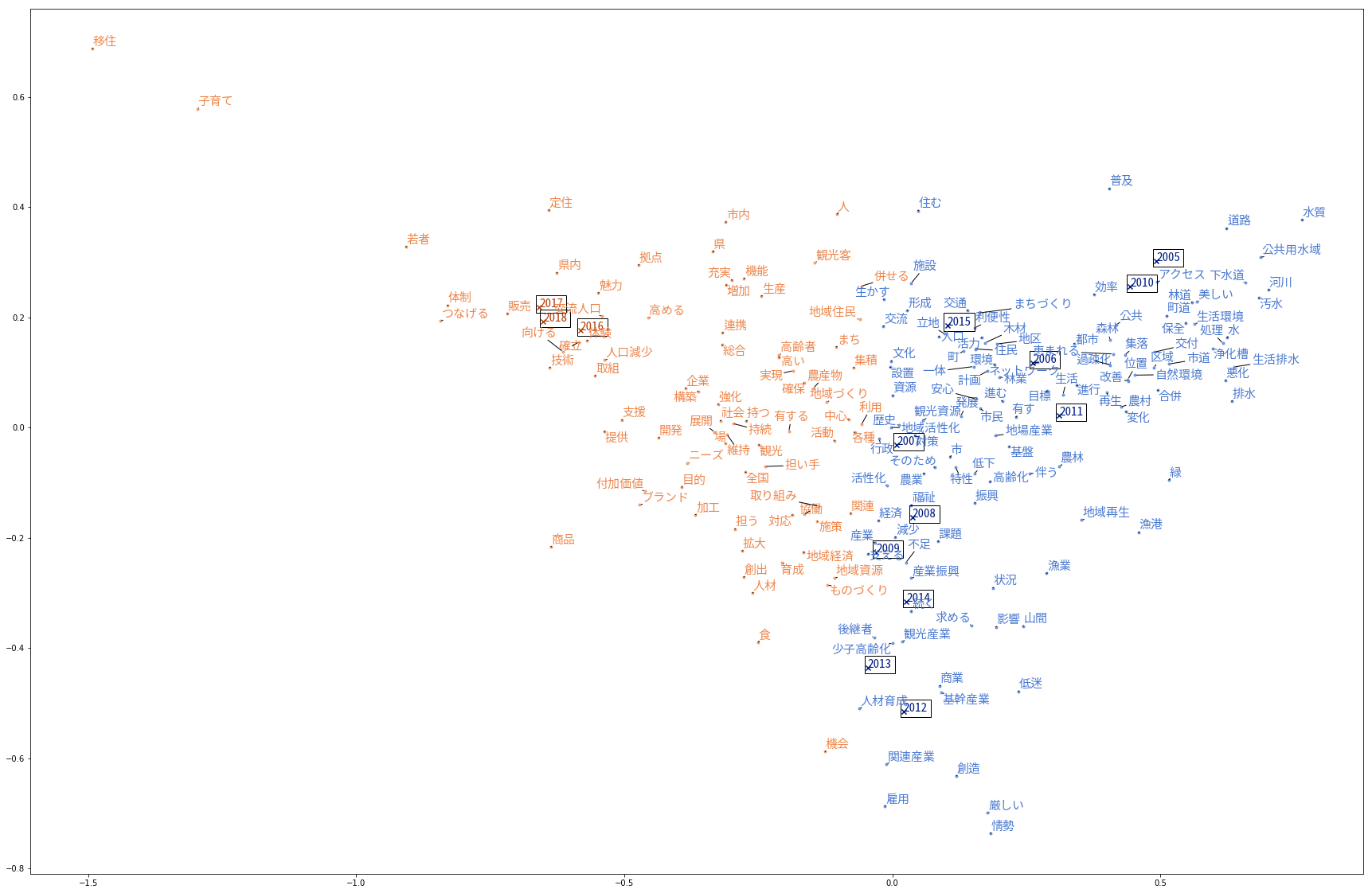
コレスポンデンス分析(頻度)
vec_data = preVectorizer(subdata_year1)
from sklearn.feature_extraction.text import CountVectorizer
vec = CountVectorizer(token_pattern='(?u)\\b\\w+\\b')
vec.fit(vec_data)
X = vec.transform(vec_data)
vec_mat = pd.DataFrame(X.toarray().transpose(), index=vec.get_feature_names())
vec_mat.columns = col_names
vec_mat['sum']= vec_mat.iloc[:,0:-1].sum(axis=1)
vec_mat.sort_values('sum', ascending =False)
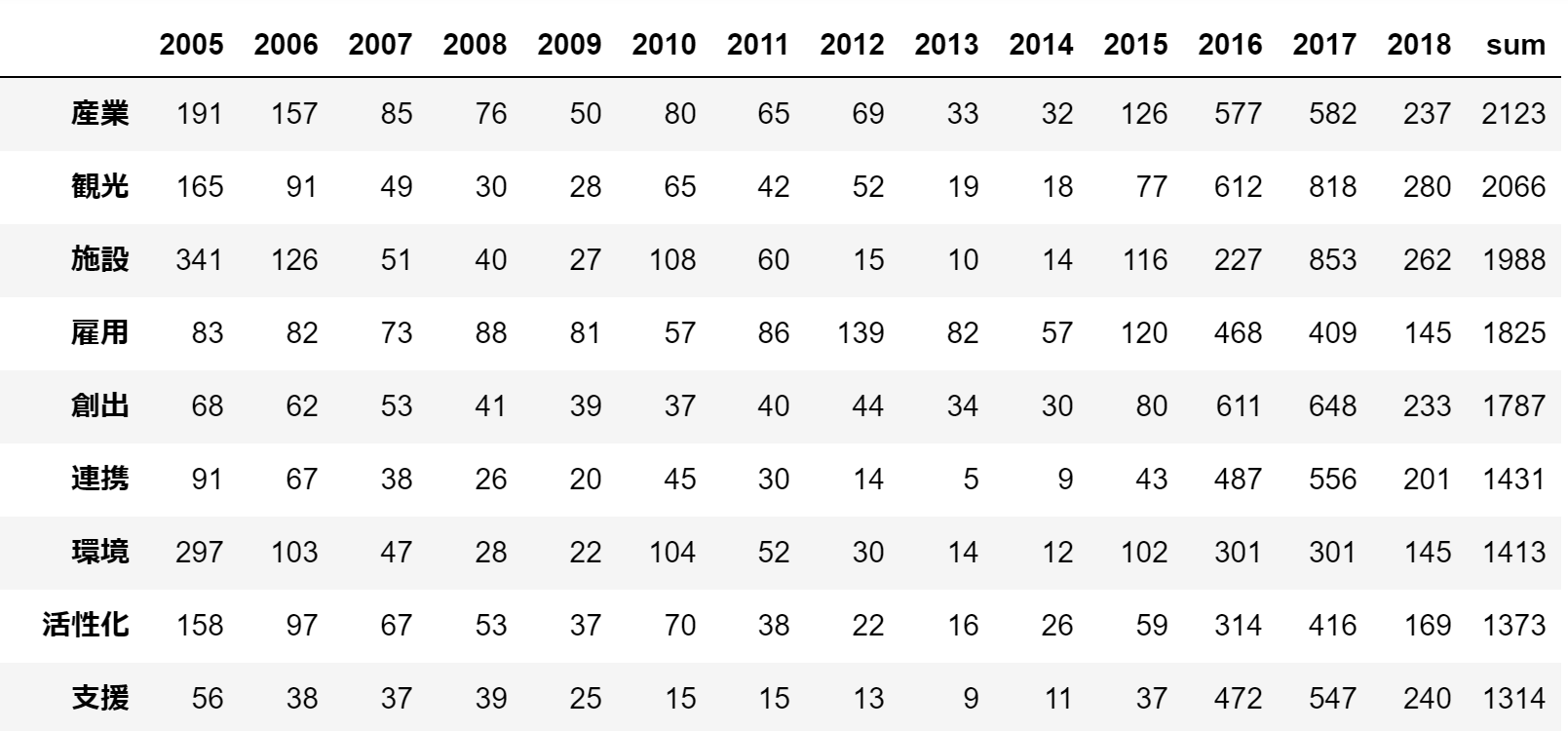
こんな表が出来ます。sumが多いもののみを抽出。
vec_mat_ca = vec_mat[vec_mat['sum']>200]
vec_mat_ca = vec_mat_ca.iloc[:,:-1]
print(vec_mat_ca.shape[0])
197単語。
data_ca = vec_mat_ca
ncol = data_ca.shape[1];
import mca
mca = mca.MCA(data_ca, ncols=ncol, benzecri=False)
result_col = pd.DataFrame(mca.fs_c(N=2));result_col.index = list(data_ca.columns)
result_row = pd.DataFrame(mca.fs_r(N=2));result_row.index = list(data_ca.index)
from sklearn.cluster import KMeans
n_cluster_col = 2
x_kmeans_col = KMeans(n_cluster_col).fit(result_col)
n_cluster_row = 2
x_kmeans_row = KMeans(n_cluster_row).fit(result_row)
plt.figure(figsize=(30,20))
plt.rcParams["font.size"] = 10
col_list = list(result_col.index)
result_col = result_col.join(pd.DataFrame(x_kmeans_col.labels_, index=result_col.index, columns=['group']))
myPalette_col = sns.color_palette("dark", n_cluster_col)
[plt.scatter(result_col.iloc[i,0], result_col.iloc[i,1],
color=myPalette_col[int(result_col.iloc[i,2])], marker="x") for i in range(result_col.shape[0])]
texts_col = [plt.text(result_col.iloc[i,0], result_col.iloc[i,1], col_list[i],
bbox=dict(facecolor='none', edgecolor='black'),
fontproperties=font_prop, color=myPalette_col[int(result_col.iloc[i,2])]) for i in range(result_col.shape[0]) ]
row_list = list(result_row.index)
result_row = result_row.join(pd.DataFrame(x_kmeans_row.labels_, index=result_row.index, columns=['group']))
myPalette_row = sns.color_palette("muted", n_cluster_row)
[plt.scatter(result_row.iloc[i,0], result_row.iloc[i,1],
color=myPalette_row[int(result_row.iloc[i,2])], marker=".", alpha=0.7) for i in range(result_row.shape[0])]
texts_row = [plt.text(result_row.iloc[i,0], result_row.iloc[i, 1], row_list[i],
fontproperties=font_prop, color=myPalette_row[int(result_row.iloc[i,2])]) for i in range(0, len(row_list)) ]
adjust_text(texts_row, arrowprops=dict(arrowstyle='-', color='black'))
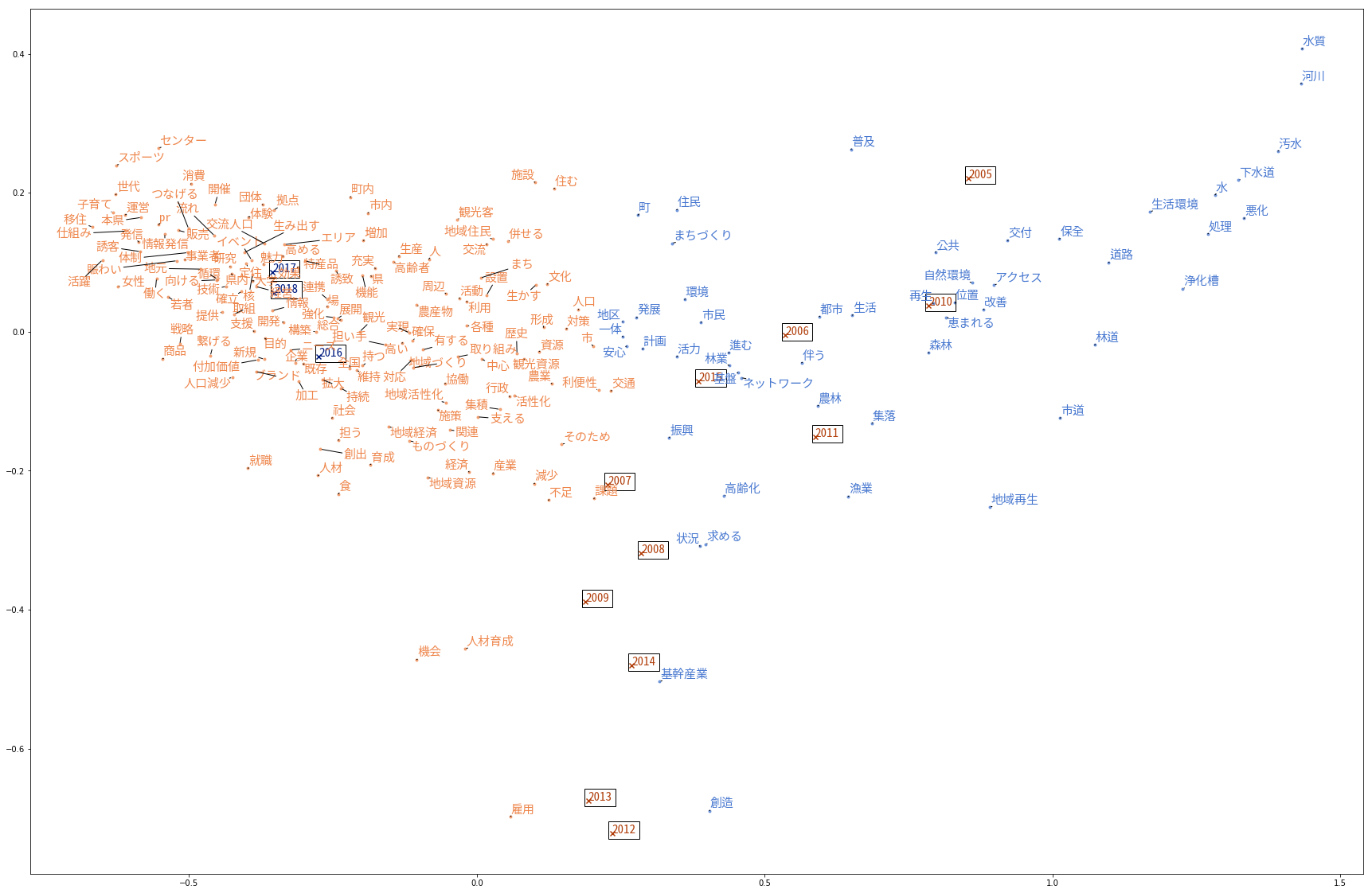
コレスポンデンス分析(TF-IDF)
vec_data = preVectorizer(subdata_year1)
from sklearn.feature_extraction.text import TfidfVectorizer
vec = TfidfVectorizer(token_pattern='(?u)\\b\\w+\\b')
vec.fit(vec_data)
X = vec.transform(vec_data)
vec_mat = pd.DataFrame(X.toarray().transpose(), index=vec.get_feature_names())
vec_mat.columns = files
vec_mat['sum']= vec_mat.iloc[:,0:-1].sum(axis=1)
vec_mat.sort_values('sum', ascending =False)
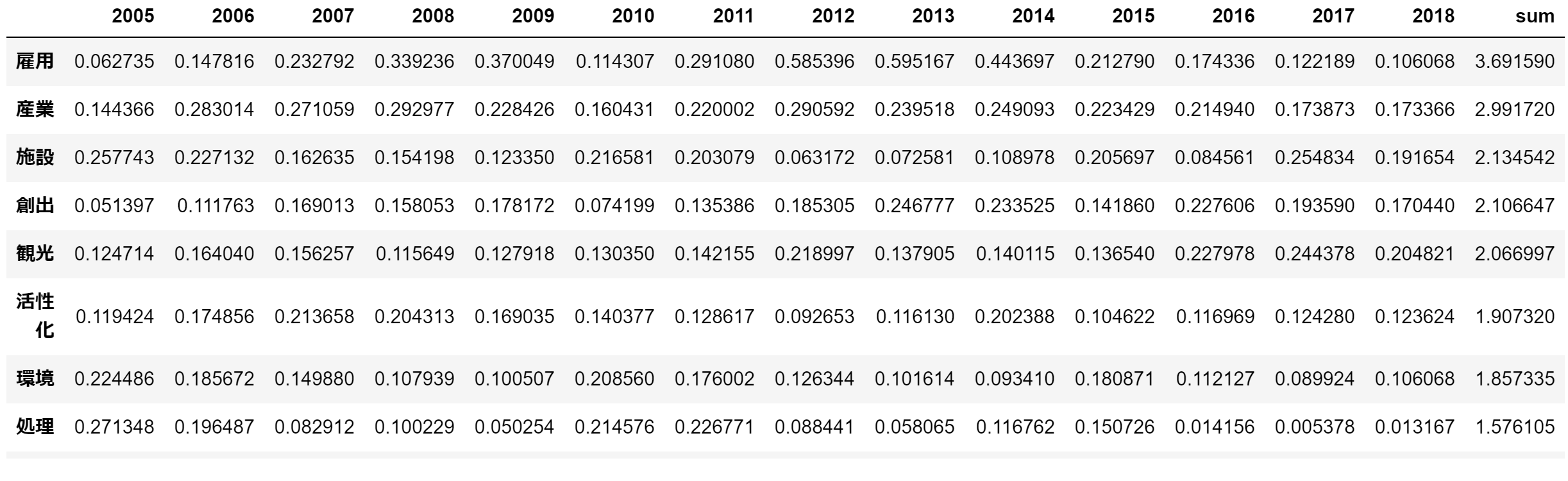
vec_mat_ca = vec_mat[vec_mat['sum']>0.25]
vec_mat_ca = vec_mat_ca.iloc[:,:-1]
print(vec_mat_ca.shape[0])
192単語。
data_ca = vec_mat_ca
ncol = data_ca.shape[1];
import mca
mca = mca.MCA(data_ca, ncols=ncol, benzecri=False)
result_col = pd.DataFrame(mca.fs_c(N=2));result_col.index = list(data_ca.columns)
result_row = pd.DataFrame(mca.fs_r(N=2));result_row.index = list(data_ca.index)
from sklearn.cluster import KMeans
n_cluster_col = 2
x_kmeans_col = KMeans(n_cluster_col).fit(result_col)
n_cluster_row = 2
x_kmeans_row = KMeans(n_cluster_row).fit(result_row)
plt.figure(figsize=(30,20))
plt.rcParams["font.size"] = 10
col_list = list(result_col.index)
result_col = result_col.join(pd.DataFrame(x_kmeans_col.labels_, index=result_col.index, columns=['group']))
myPalette_col = sns.color_palette("dark", n_cluster_col)
[plt.scatter(result_col.iloc[i,0], result_col.iloc[i,1],
color=myPalette_col[int(result_col.iloc[i,2])], marker="x") for i in range(result_col.shape[0])]
texts_col = [plt.text(result_col.iloc[i,0], result_col.iloc[i,1], col_list[i],
bbox=dict(facecolor='none', edgecolor='black'),
fontproperties=font_prop, color=myPalette_col[int(result_col.iloc[i,2])]) for i in range(result_col.shape[0]) ]
row_list = list(result_row.index)
result_row = result_row.join(pd.DataFrame(x_kmeans_row.labels_, index=result_row.index, columns=['group']))
myPalette_row = sns.color_palette("muted", n_cluster_row)
[plt.scatter(result_row.iloc[i,0], result_row.iloc[i,1],
color=myPalette_row[int(result_row.iloc[i,2])], marker=".", alpha=0.7) for i in range(result_row.shape[0])]
texts_row = [plt.text(result_row.iloc[i,0], result_row.iloc[i, 1], row_list[i],
fontproperties=font_prop, color=myPalette_row[int(result_row.iloc[i,2])]) for i in range(0, len(row_list)) ]
adjust_text(texts_row, arrowprops=dict(arrowstyle='-', color='black'))